题目描述:在一个排序的链表中,存在重复的结点,请删除该链表中重复的结点,重复的结点不保留,返回链表头指针。 例如,链表1->2->3->3->4->4->5 处理后为 1->2->5
1.新建p1指针记录新的不包含重复节点的链表
2.指针p2遍历原链表,跳过重复的节点
3.将不重复的节点地址赋值给p1
新建指针p1作为不包含重复节点链表的头节点
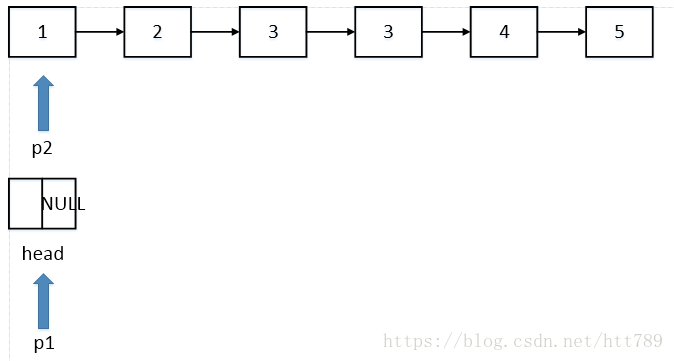
p2遍历原链表,当p2指向的节点与下一个节点没有重复时,将p2所指向的节点赋值给p1,p1后移
如图所示,1不等于2,所以将p1指向p2的节点
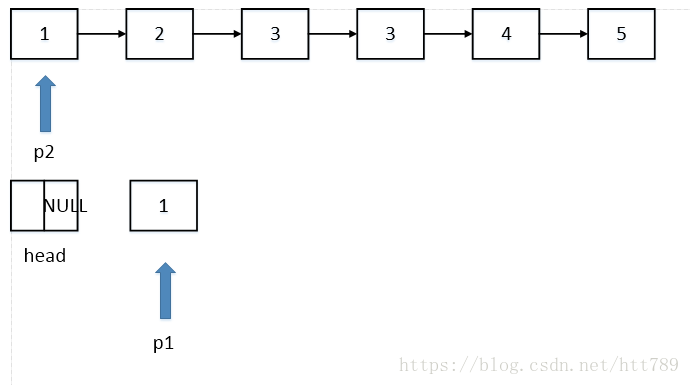
p2遍历原链表,当p2指向的节点与下一个节点出现重复时,向后移动p2直到指向不重复节点,将不重复的节点赋值给p1
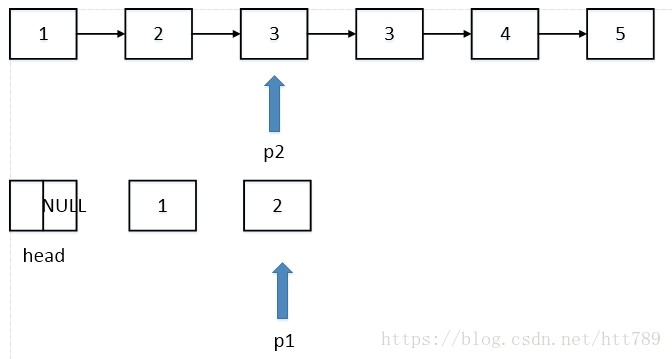
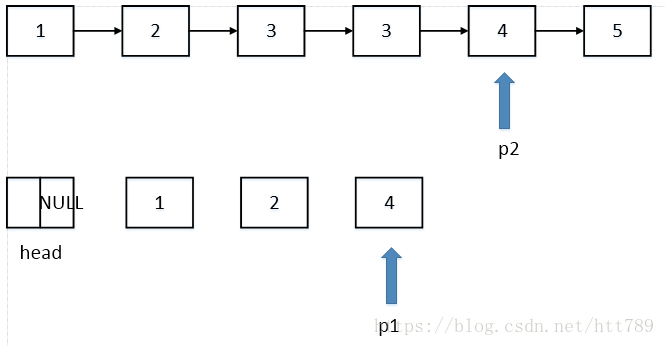
ListNode* deleteDuplication(ListNode* pHead)
{
if (pHead == NULL || pHead->next == NULL)
return pHead;
/*---------先为链表创建一个头结点---------*/
ListNode* head = new ListNode(0);
head->next = NULL;//p1的轨迹记录没有重复的节点
ListNode* p1 = head;
ListNode* p2 = pHead;//p2用于遍历原链表,方便p1跳过重复的点
while(p2){
if(p2->next && p2->val == p2->next->val){
while(p2->next && p2->val == p2->next->val){
p2 = p2->next;
}
p2 = p2->next;//p2跳过重复串中的最后一个重复节点
//防止链表尾出现重复,p2==NUll,程序跳出will循环,而p1没有跳过尾部重复
p1->next = p2;
}
else{//如果没有重复
p1->next = p2;
p1 = p1->next;
p2 = p2->next;
}
}
return head->next;//返回时要去除头节
}