原文见:https://blog.csdn.net/google19890102/article/details/23924971
一、近邻算法(Nearest Neighbors)
1、近邻算法的概念
近邻算法(Nearest Neighbors)是一种典型的非参模型,与生成方法(generalizing method)不同的是,在近邻算法中,通过以实例的形式存储所有的训练样本,假设有m个训练样本:
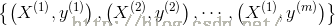
此时需要存储这m个训练样本,因此,近邻算法也称为基于实例的模型。
对于一个需要预测的样本,通过与存储好的训练样本比较,以较为相似的样本的标签作为近邻算法的预测结果。
2、近邻算法的分类
在近邻算法中,根据处理的问题的不同,可以分为:在本篇博文中,主要介绍近邻分类算法。
- 近邻分类算法
- 近邻回归算法
注意:除了上述的监督式近邻算法,在近邻算法中,还有一类非监督的近邻算法。
二、近邻分类算法
1、近邻分类算法的概念
2、KNN算法概述
K-NN算法是最简单的分类算法,主要的思想是计算待分类样本与训练样本之间的差异性,并将差异按照由小到大排序,选出前面K个差异最小的类别,并统计在K个中类别出现次数最多的类别为最相似的类,最终将待分类样本分到最相似的训练样本的类中。与投票(Vote)的机制类似。
3、样本差异性
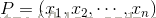 与样本
与样本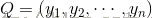 之间的欧式距离为:
之间的欧式距离为:
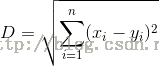
4、KNN算法的流程
- 求预测样本与训练样本之间的相似性
- 依据相似性排序
- 选择前K个最为相似的样本对应的类别
- 得到预测的分类结果

三、K-近邻算法实现
1、Python实现

-
# coding:UTF-8
-
-
import cPickle
as pickle
-
import gzip
-
import numpy
as np
-
-
def load_data(data_file):
-
with gzip.open(data_file,
‘rb’)
as f:
-
train_set, valid_set, test_set = pickle.load(f)
-
return train_set[
0], train_set[
1], test_set[
0], test_set[
1]
-
-
def cal_distance(x, y):
-
return ((x - y) * (x - y).T)[
0,
0]
-
-
def get_prediction(train_y, result):
-
result_dict = {}
-
for i
in xrange(len(result)):
-
if train_y[result[i]]
not
in result_dict:
-
result_dict[train_y[result[i]]] =
1
-
else:
-
result_dict[train_y[result[i]]] +=
1
-
predict = sorted(result_dict.items(), key=
lambda d: d[
1])
-
return predict[
0][
0]
-
-
def k_nn(train_data, train_y, test_data, k):
-
# print test_data
-
m = np.shape(test_data)[
0]
# 需要计算的样本的个数
-
m_train = np.shape(train_data)[
0]
-
predict = []
-
-
for i
in xrange(m):
-
# 对每一个需要计算的样本计算其与所有的训练数据之间的距离
-
distance_dict = {}
-
for i_train
in xrange(m_train):
-
distance_dict[i_train] = cal_distance(train_data[i_train, :], test_data[i, :])
-
# 对距离进行排序,得到最终的前k个作为最终的预测
-
distance_result = sorted(distance_dict.items(), key=
lambda d: d[
1])
-
# 取出前k个的结果作为最终的结果
-
result = []
-
count =
0
-
for x
in distance_result:
-
if count >= k:
-
break
-
result.append(x[
0])
-
count +=
1
-
# 得到预测
-
predict.append(get_prediction(train_y, result))
-
return predict
-
-
def get_correct_rate(result, test_y):
-
m = len(result)
-
-
correct =
0.0
-
for i
in xrange(m):
-
if result[i] == test_y[i]:
-
correct +=
1
-
return correct / m
-
-
if
name ==
“main”:
-
# 1、导入
-
print
“———- 1、load data ————”
-
train_x, train_y, test_x, test_y = load_data(
“mnist.pkl.gz”)
-
# 2、利用k_NN计算
-
train_x = np.mat(train_x)
-
test_x = np.mat(test_x)
-
print
“———- 2、K-NN ————-“
-
result = k_nn(train_x, train_y, test_x[:
10,:],
10)
-
print result
-
# 3、预测正确性
-
print
“———- 3、correct rate ————-“
-
print get_correct_rate(result, test_y)
-
-
2、Scikit-leanrn库
在Scikit-learn库中对K-NN算法有很好的支持,核心程序为:
四、K-NN算法中存在的问题及解决方法
1、计算复杂度的问题
2、K-NN的均匀投票
参考文献
1、1.6. Nearest Neighbors点击打开链接
一、近邻算法(Nearest Neighbors)
1、近邻算法的概念
近邻算法(Nearest Neighbors)是一种典型的非参模型,与生成方法(generalizing method)不同的是,在近邻算法中,通过以实例的形式存储所有的训练样本,假设有m个训练样本:
此时需要存储这m个训练样本,因此,近邻算法也称为基于实例的模型。
对于一个需要预测的样本,通过与存储好的训练样本比较,以较为相似的样本的标签作为近邻算法的预测结果。
2、近邻算法的分类
在近邻算法中,根据处理的问题的不同,可以分为:在本篇博文中,主要介绍近邻分类算法。
- 近邻分类算法
- 近邻回归算法
注意:除了上述的监督式近邻算法,在近邻算法中,还有一类非监督的近邻算法。
二、近邻分类算法
1、近邻分类算法的概念
2、KNN算法概述
K-NN算法是最简单的分类算法,主要的思想是计算待分类样本与训练样本之间的差异性,并将差异按照由小到大排序,选出前面K个差异最小的类别,并统计在K个中类别出现次数最多的类别为最相似的类,最终将待分类样本分到最相似的训练样本的类中。与投票(Vote)的机制类似。
3、样本差异性
与样本
之间的欧式距离为:
4、KNN算法的流程
- 求预测样本与训练样本之间的相似性
- 依据相似性排序
- 选择前K个最为相似的样本对应的类别
- 得到预测的分类结果
三、K-近邻算法实现
1、Python实现
-
# coding:UTF-8
-
-
import cPickle
as pickle
-
import gzip
-
import numpy
as np
-
-
def load_data(data_file):
-
with gzip.open(data_file,
‘rb’)
as f:
-
train_set, valid_set, test_set = pickle.load(f)
-
return train_set[
0], train_set[
1], test_set[
0], test_set[
1]
-
-
def cal_distance(x, y):
-
return ((x - y) * (x - y).T)[
0,
0]
-
-
def get_prediction(train_y, result):
-
result_dict = {}
-
for i
in xrange(len(result)):
-
if train_y[result[i]]
not
in result_dict:
-
result_dict[train_y[result[i]]] =
1
-
else:
-
result_dict[train_y[result[i]]] +=
1
-
predict = sorted(result_dict.items(), key=
lambda d: d[
1])
-
return predict[
0][
0]
-
-
def k_nn(train_data, train_y, test_data, k):
-
# print test_data
-
m = np.shape(test_data)[
0]
# 需要计算的样本的个数
-
m_train = np.shape(train_data)[
0]
-
predict = []
-
-
for i
in xrange(m):
-
# 对每一个需要计算的样本计算其与所有的训练数据之间的距离
-
distance_dict = {}
-
for i_train
in xrange(m_train):
-
distance_dict[i_train] = cal_distance(train_data[i_train, :], test_data[i, :])
-
# 对距离进行排序,得到最终的前k个作为最终的预测
-
distance_result = sorted(distance_dict.items(), key=
lambda d: d[
1])
-
# 取出前k个的结果作为最终的结果
-
result = []
-
count =
0
-
for x
in distance_result:
-
if count >= k:
-
break
-
result.append(x[
0])
-
count +=
1
-
# 得到预测
-
predict.append(get_prediction(train_y, result))
-
return predict
-
-
def get_correct_rate(result, test_y):
-
m = len(result)
-
-
correct =
0.0
-
for i
in xrange(m):
-
if result[i] == test_y[i]:
-
correct +=
1
-
return correct / m
-
-
if
name ==
“main”:
-
# 1、导入
-
print
“———- 1、load data ————”
-
train_x, train_y, test_x, test_y = load_data(
“mnist.pkl.gz”)
-
# 2、利用k_NN计算
-
train_x = np.mat(train_x)
-
test_x = np.mat(test_x)
-
print
“———- 2、K-NN ————-“
-
result = k_nn(train_x, train_y, test_x[:
10,:],
10)
-
print result
-
# 3、预测正确性
-
print
“———- 3、correct rate ————-“
-
print get_correct_rate(result, test_y)
-
-
2、Scikit-leanrn库
在Scikit-learn库中对K-NN算法有很好的支持,核心程序为:
四、K-NN算法中存在的问题及解决方法
1、计算复杂度的问题
2、K-NN的均匀投票
参考文献
1、1.6. Nearest Neighbors点击打开链接