布隆过滤器(Bloom Filter)是1970由布隆提出的。通过一个很长的二进制向量于一系列随即哈希函数生成。下面我就将通过以下小节来介绍布隆过滤器:
1、原因与结构解析
2、数学公式
1.1 原因与结构解析
首先,我们应当知道,hash是内存中使用的经典数据结构。
当我们需要判读一个元素是否在一个集合当中时,我们可以用哈希表来判断。在集合较小的情况下,hash是可行而且高效的。
然而数据量以PT计的大数据场景中,很多时候,hash便力有未逮。这是因为在海量数据下hash要占据巨额内存空间,这远远超过我们能够提供的内存大小。
例如在黑名单过滤当中,我们有100亿的网站黑名单url需要过滤,假设一个url是64bytes。如果我们用hash表来做,那么我们至少需要6400亿字节即640G的内存空间(实际所需空间还远大于此),空间消耗巨大,必须要多个服务器来同时分摊内存。
然而我们是否能用更加精简的结构来做这件事呢?布隆过滤器就是这样一个高度节省空间的结构,并且其时间也远超一般算法,但是布隆过滤器存在一定的失误率,例如在网页URL黑名单过滤中,布隆过滤器绝不会将黑名单中网页查错,但是有可能将正常的网页URL判定为黑名单当中的,它的失误可以说是宁可错杀,不可放过。不过布隆过滤器的失误率可以调节,下面我们会详细介绍。
布隆过滤器实际就是一种集合。假设我们有一个数组,它的长度为L,从0-(L-1)位置上,存储的不是一个字符串或者整数,而是一个bit,这意味它的取值只能为0或1.
例如我们实现如下的一个数组:
int[] array = new int[1000];
该数组中有1000个int类型的元素,而每一个int由有4个byte组成,一个byte又由8个bit组成,所以一个int就由32个bit所组成。
所以我们申请含1000整数类型的数组,它就包含32000个bit位。
但是我们如果想将第20001个bit位描黑,将其改为1,我们需要怎样做呢。
首先我们的需要定位,这第20001个bit位于哪个整数,接着我们需要定位该bit位于该整数的第几个bit位。
int index = 20001; int intIndex = index/32; int bitIndex = index%32;
然后我们就将其描黑:
array[intIndex] =(array[intIndex] | (1 << bitIndex));
这段代码可能有些同学不能理解,下面我们详细解释一下。我们的数组是0-999的整型数组,但是每个位置上实际保存的是32个bit,我们的intIndex就是代表第几个整数,定位到625,而bitIndex定位到第625个整数中的第几个bit,为1。
所以,我们需要描黑的位置是第625号元素的第1个bit。
而(1 << bitIndex)代表将1左移到1位置,即是代表只有1位置为1,而其他位置为零。就相当于获得了这样一串二进制数:
00000000 00000000 00000000 00000001
然后我们将这样的二进制数与array[indIndex]进行逻辑或运算,就能将第625号元素的第一个bit描黑变1,最后我们将描黑后的元素赋值给array[indIndex],完成运算。
这里我们采用的是int类型的数组,如果我们想更加节省空间,我们就能创建long类型的数组,这样申请1000个数组空间,我们就能得到64000个bit。
然后我们还能进一步扩展,将数组做成矩阵:
long[][] map = new long[1000][1000];
有了这些基础以后,我们如何设计黑名单问题呢?
假设我们已经有了一个拥有m个bit的数组,然后我们将一个URL通过哈希函数计算出hashcode,然后hashcode%m将对应位置描黑。
然而这还不是真正的布隆过滤器,真正的布隆过滤器是通过多个哈希函数对一个URL进行计算,得到hashcode,然后在对不同位置的bit进行描黑。
注意:布隆过滤器采用的多个哈希函数必须是相互独立的,前面我们已经介绍了如何通过一个哈希函数构造多个独立哈希函数的方法。
当我们将一个URL通过n个哈希函数,得到hashcode,模以m,再将对应位置描黑之后。我们可以说该URL已经进入我们的布隆过滤器当中了。
接下来,我们将黑名单中所有URL都通过哈希函数,进入布隆过滤器中(布隆过滤器并不真正存储实际的URL)。
对于一个新的URL,我们要查询其是否在黑名单中,我们便通过同样的n个哈希函数,计算出n个位置,然后我们查询这n个位置是否都被描黑,如果都被描黑,我们就说该URL在黑名单当中。如果n个位置但凡有一个不为黑,我们就说该URL不在该黑名单中。
注意:我们的数组不应该过小,不然很可能数组中的大多数位置都被描黑,这很容易将正常的URL判定为不合法的,这也是布隆过滤器的失误率来源。
3.2 数学公式
通过上一小节的介绍,我们可以直观的感觉到,我们可以通过调整哈希函数n的大小以及数组m的大小来控制失误率。
事实确实如此,下面我们就介绍有有关哈希函数数量,数组大小,以及失误率的数学推论。
首先,我们要使用多少个哈希函数呢?
这一点只与我们黑名单中URL的数量及bit数组长度有关,而与单个URL的大小无关(哈希函数的输入域是无穷的)。它只要求我们的哈希函数能够接受URL这一参数类型。
而我们的数组或者矩阵的大小长度与什么有关呢?
它同样与我们黑名单中URL的数量有关,除此之外它还与我们能够接受的失误率有关。
下面我们给出有关公式:
m= - n*lnp /(ln2)^2 #n为样本数量 p为预计的失误率
当我们的样本量为100亿,而我们预计的失误率为万分之一,根据这个公式我们便可以得到m 为:
131571428572 bit
其单位为bit,但我们实际要用的是byte,所以还要除以8,最后需要的空间为23GB(向上取整)。
对比哈希表,原来我们需要640GB,而现在只需要23GB,大大节省了内存空间消耗。
而我们所需要的哈希函数的个数k的数学公式为:
k = ln2 * m/k #m为数组长度 n为样本数量 k向上取整
这里经过计算n为13。
因为我们的m和n都经过了向上取整,所以我们的实际失误率会变得更低。失误率的计算公式为:
p = (1-e^(-k*n/m))^k#n为样本数量,m为数组长度,k为哈希函数个数
经过我们向上取整后,计算出来的实际失误率为十万分之六。
二、hbase中的布隆过滤器
布隆过滤器是hbase中的高级功能,它能够减少特定访问模式(get/scan)下的查询时间。不过由于这种模式增加了内存和存储的负担,所以被默认为关闭状态。
hbase支持如下类型的布隆过滤器:
1、NONE 不使用布隆过滤器
2、ROW 行键使用布隆过滤器
3、ROWCOL 列键使用布隆过滤器
其中ROWCOL是粒度更细的模式。
2.1原因
在介绍为什么hbase要引入布隆过滤器之前,我们先来了解一下hbase存储文件HFile的块索引机制
我们知道hbase的实际存储结构是HFile,它是位于hdfs系统中的,也就是在磁盘中。而加载到内存中的数据存储在MemStore中,当MemStore中的数据达到一定数量时,它会将数据存入HFile中。
HFIle是由一个个数据块与索引块组成,他们通常默认为64KB。hbase是通过块索引来访问这些数据块的。而索引是由每个数据块的第一行数据的rowkey组成的。当hbase打开一个HFile时,块索引信息会优先加载到内存当中。
然后hbase会通过这些块索引来查询数据。
但是块索引是相当粗粒度的,我们可以简单计算一下。假设一个行占100bytes的空间,所以一个数据块64KB,所包含的行大概有:(64 * 1024)/100 = 655.53 = ~700行。而我们只能从索引给出的一个数据块的起始行开始查询。
如果用户随机查找一个行键,则这个行键很可能位于两个开始键(即索引)之间的位置。对于hbase来说,它判断这个行键是否真实存在的唯一方法就是加载这个数据块,并且扫描它是否包含这个键。
同时,还存在很多情况使得这种情况更加复杂。
对于一个应用来说,用户通常会以一定的速率进行更新数据,这就将导致内存中的数据被刷写到磁盘中,并且之后系统会将他们合并成更大的存储文件。在hbase的合并存储文件的时候,它仅仅会合并最近几个存储文件,直至合并的存储文件到达配置的最大大小。最终系统中会有很多的存储文件,所有的存储文件都是候选文件,其可能包含用户请求行键的单元格。如下图所示:
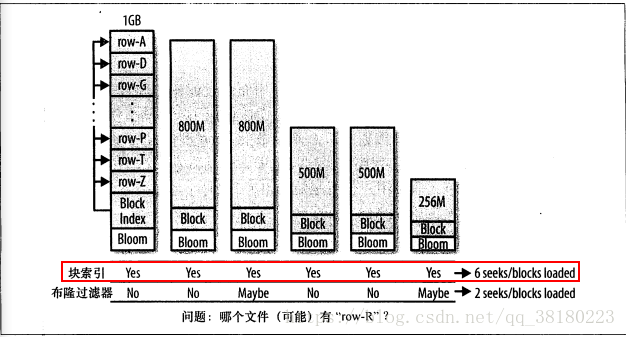
我们可以看到,这些不同的文件都来着同一个列族,所以他们的行键分布类似。所以,虽然我们要查询更新的特定行只在某个或者某几个文件中,但是采用块索引方式,还是会覆盖整个行键范围。当块索引确定那些块可能含有某个行键后,regionServer需要加载每一个块来检查该块中是否真的包含该行的单元格。
2.2作用
从4.1小节当中我们可以知道,当我们随机读get数据时,如果采用hbase的块索引机制,hbase会加载很多块文件。如果采用布隆过滤器后,它能够准确判断该HFile的所有数据块中,是否含有我们查询的数据,从而大大减少不必要的块加载,从而增加hbase集群的吞吐率。
这里有几点细节:
1、布隆过滤器的存储在哪?
对于hbase而言,当我们选择采用布隆过滤器之后,HBase会在生成StoreFile(HFile)时包含一份布隆过滤器结构的数据,称其为MetaBlock;MetaBlock与DataBlock(真实的KeyValue数据)一起由LRUBlockCache维护。所以,开启bloomfilter会有一定的存储及内存cache开销。但是在大多数情况下,这些负担相对于布隆过滤器带来的好处是可以接受的。
2、采用布隆过滤器后,hbase如何get数据?
在读取数据时,hbase会首先在布隆过滤器中查询,根据布隆过滤器的结果,再在MemStore中查询,最后再在对应的HFile中查询。
3、采用ROW还是ROWCOL布隆过滤器?
这取决于用户的使用模式。如果用户只做行扫描,使用更加细粒度的行加列布隆过滤器不会有任何的帮助,这种场景就应该使用行级布隆过滤器。当用户不能批量更新特定的一行,并且最后的使用存储文件都含有改行的一部分时,行加列级的布隆过滤器更加有用。
例如:ROW 使用场景假设有2个Hfile文件hf1和hf2, hf1包含kv1(r1 cf:q1 v)、kv2(r2 cf:q1 v) hf2包含kv3(r3 cf:q1 v)、kv4(r4 cf:q1 v) 如果设置了CF属性中的bloomfilter(布隆过滤器)为ROW,那么get(r1)时就会过滤hf2,get(r3)就会过滤hf1 。
ROWCOL使用场景假设有2个Hfile文件hf1和hf2, hf1包含kv1(r1 cf:q1 v)、kv2(r2 cf:q1 v) hf2包含kv3(r1 cf:q2 v)、kv4(r2 cf:q2 v) 如果设置了CF属性中的bloomfilter为ROW,无论get(r1,q1)还是get(r1,q2),都会读取hf1+hf2;而如果设置了CF属性中的bloomfilter为ROWCOL,那么get(r1,q1)就会过滤hf2,get(r1,q2)就会过滤hf1。