我们配置好了spark和zk,下一步就是启动它们了,启动的方法是先把slave2,5,6的zk首先启动起来,然后到master这台机器上启动spark,最后到slave1上面启动备用的Spark-Master节点,从而实现高可用架构。
接下来我来说一下什么叫做蒙特卡洛法,很简单,我们现在有一个边长为2的正方形,里面内嵌一个半径为1的圆:
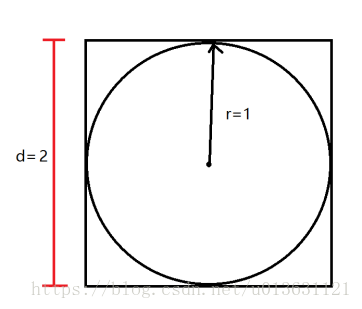
我们把这个东西分为三部分,一部分是圆的内部,一部分是圆的外部且在正方形内部,最后一部分是正方体的外部。
我们定义正方形左下角坐标为(0,0),然后建立一个直角坐标系,这样我们的正方形内部的坐标都确定了下来,其集合为{(x,y) | 0=<x<=2, 0=<y<=2}。然后我们生成N组随机数(x,y),且0=<x<=2, 0=<y<=2。(x,y)有两种情况:落到圆内和圆外(且在正方形内部)。接下来我们做一个公式:
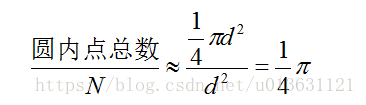
那么圆周率就为:

这个就叫做蒙特卡洛法。至于为什么点数之比就为四分之一圆周率了呢?你们想想,假如点是均匀分布的,且有无数个,是不是就是这些点正好把一个圆给覆盖住了?想不明白?那么我们就在正方体里面打格子,假设一个格子里面有一个点,格子无限小,和质点一样小,所有格子面积加和就是整体的面积吧。也就是质点数目乘以一个小格个面积等于总的面积,然后我们因为用圆内点比上总点数,一个小格的面积就被约分了。

还有公式为什么是约等呢,那是因为我们N不是无穷个点,而且点也不是均匀分布的,会有误差。但N越大越接近于等号。
介绍完成了理论之后,我们来一个实践吧!
我们在slave4这台机器(只要是安装了spark的机器就行)命令行输入:
~/bigdata/spark-2.2.0-bin-hadoop2.7/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://master:7077,slave1:7077 \
--executor-memory 2G \
--total-executor-cores 24 \
~/bigdata/spark-2.2.0-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.2.0.jar \
100
这样,我们就执行了操作,第一行指的是spark目录下的上交菜单在哪。第二行是告诉机器,我们要执行的是哪一个类,这里是Spark自带的类,蒙特卡洛法求圆周率。第三行是指定我们spark的Master主机的地址,第四行是每一个Worker机器用多大的内存,第五行是所有的Worker机器一共有多少个线程数,第六行是我们求圆周率的jar包在哪,最后一行就是我们的生成的点数N了,这里取100。之后我们运行后得出结果:
数据不是很准确,因为我们的点数太少了,我们换成1000,再计算:
换成10000再计算:
换成3W:
我们发现越来越接近了。
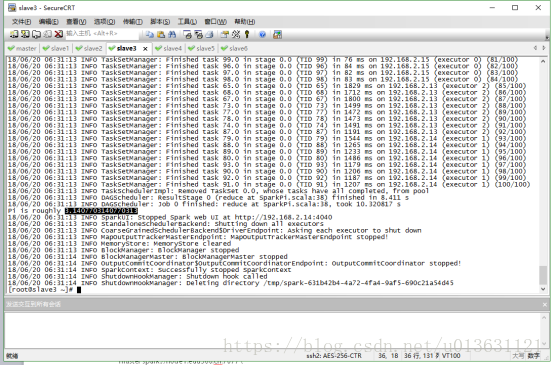
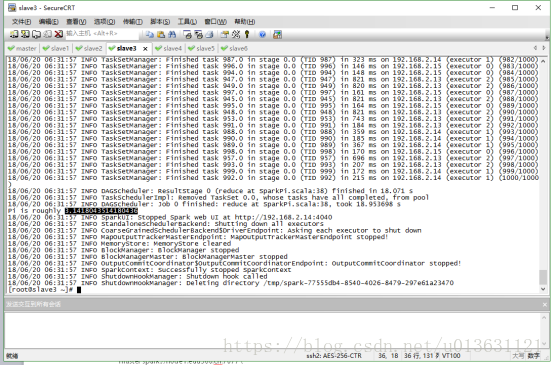
计算完毕后,我们可以在spark终端上面看到执行的时间:
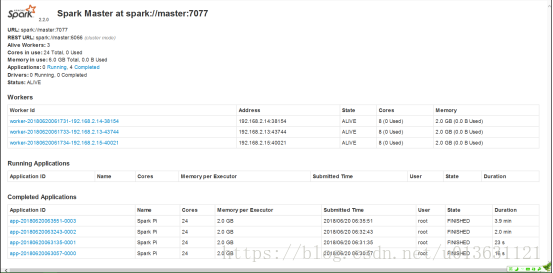
我们看到最下面的4行就是我们执行的四次操作,各行分别是3W,1W,1000,100个点的情况。最后一列就是运行的时间了。
我们得出结论,点越多圆周率越准确,但是消耗的时间却越长。OK,蒙特卡洛法讲完了。
———————————————
如果对我的课程感兴趣的话,欢迎关注小木希望学园-微信公众号:
mutianwei521
也可以扫描二维码哦!
