摘要
本文主要在数据集上综合运用kNN、决策树与朴素贝叶斯,并作对比。
目录
一、问题描述
消费者产生买车需求是一切的缘由。在选车时纠结,这源于人类天生具有的比较心理。在面临多种选择时,会比来比去。此外,买车是一笔不菲投入,这导致人们选择时更加谨慎,压力山大。选车纠结是当前消费者的痛点所在。一旦考虑到买车后的维护费,更是让人头痛。
人人后希望花更少的钱,买到一辆性价比高的车,使买的车有宽坦的空间、后备箱,还可以容纳更多人,而且上下车是可以随手开门。每一个人都希望有部安全可靠的车。但汽车的种类是那么繁多,一部车与安全部分有关的零件又是那么繁多。
到底该选择哪一部车呢?
受各种条件和客观因素限制,在一般的选车过程中,人们不可能都对这些情况了如指撑。因此了解专业人士如何对汽车进行综合评价,应该是购车者掌握“如何判断汽车是否合适自己”最基本、最简捷的好办法。
请收集国内外某些专业人士对汽车的综合评价,利用kNN算法、决策树、朴素贝叶斯算法这三种算法或模型,来帮消费者根据实际情况选择适合自己的汽车,并比较这三种算法或模型的优劣性。
二、数据获取与预处理
2.1 数据的获取
在此从UCI数据库中选取汽车评价数据集Car Evaluation Database,本数据集专业汽车评价人士对于1728单买卖的实际情况进行综合评价,并给出顾客的买车建议。专业人士就顾客对于买车价格(共4个等级)、维护费(共4个等级)、车门数(共4个等级)、载人数(共3个等级)、后备箱大小(共3个等级)、安全性(共3个等级)等方面的看法进行专业评价,并给出合适的建议:不可接收、可以接受、好、非常好。数据集部分原始数据截图如图1所示。

2.2 数据预处理
2.2.1 字符分割
原始的数据参杂评价等级和标点符号,这使得数据集不能直接使用,所示,先将评价等级和标点符号分割开来,使用Python中split函数,并逐行读取后,以“,”作为分割点将每行字符串分割后保存在另一文件中。分割完成后的数据集部分数据截图如图2所示。
2.2.2 评价等级量化
为得到6个评价属性和综合评价之间较精确的数学关系,在此应该使用数字的序号作为评价等级以代替原来的文字评价等级。考虑到人们习惯上认为属性的数值越大则属性越好,于是,对于这6个评价属性中各评价等级应该等价地认同为:
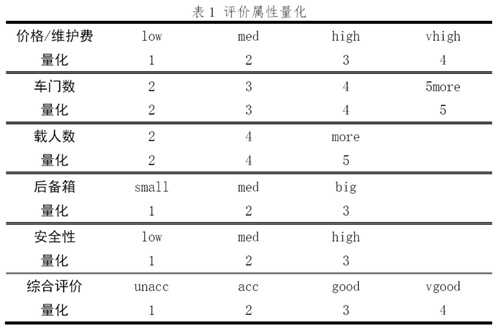

对于这6个评价属性,在不同情况下便使用不同的形式。在数值类计算情况下比如kNN算法,便是使用数值化后的评价属性。在类别分类情况下比如决策树,可以应用文字属性等级的形式。
2.2.3 缺失数据和异常数据的检测
逐行检测数据集中的数据,检查是否含有缺失值和异常值。幸运的是,本汽车评价数据集中不含缺失数据和异常数据,所以可以进行下一步处理。
2.3 数据可视化
对于汽车评价数据集中1728个数据,考虑到综合评价值只是包含4个等级:不可接收、可以接受、好、非常好,每种等级的数据的数量不一定相同,而且不一定具有庞大的数量。为了接下来的测试和计算的严谨性,应该先对综合评价等级进行统计,其统计结构如图3和图4所示。
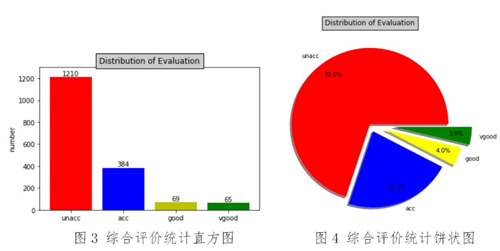
从图3和图4中可以看出,在1728个数据中,含综合评价为好、非常好的数据只是占不超过8%,数量只为69、65,而数据集中大部分的数据为综合评价为不可接受的数据。考虑到在数据测试时,若是选取80%、90%的训练集作为测试集,而剩下的作为测试集,这是有可能在训练集中将综合评价为好、非常好的数据排除在外或者它们的影响较大。
于此,为确保训练集包含每一种综合评价等级的数据,应该在选取训练集时,将按照各种综合评价等级的数据选取相应的比例的数据作为训练集,而剩下的作为测试集。
三、算法的简要介绍
3.1 kNN算法
3.1.1 kNN算法介绍
k近邻分类算法(k-Nearest Neighbor,kNN),是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。k近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这k个实例的多数属于某个类,就把该输入实例分类到这个类中。
3.1.2 计算步骤
(1)计算测试对象与训练集中所有对象的距离,选取欧式距;
(2)找出上步计算的距离中最近的k个对象,作为测试对象的k个邻居;
(3)找出K个邻居中类别出现频率最高的对象,其所属的类别就是该测试对象所属的类别。
3.2 决策树
3.2.1 决策树介绍
决策树是将所要处理的数据看做是树的根,相应的选取数据的特征作为一个个节点(决策点),每次选取一个节点将数据集分为不同的数据子集,可以看成对树进行分支,直到最后无法可分停止。
3.2.2 构造决策树
(1)选取香农熵的信息增益作为根据进行划分,使得划分在同一集合中的数据具有共同的特征;
(2)按照给定特征划分数据集并进行简单的测试,接下来我们遍历整个数据集,循环计算香农熵,找到最好的划分方式并简单测试;
(3)递归构建决策树,将每一个划分的数据看成是原数据集,那么之后的每一次划分都可以看成是和第一次划分相同的过程。递归结束的条件是:程序遍历完所有划分数据集的属性,或者每个分支下的所有实例都有相同的分类;
(4)使用matplotlib注解绘制树形图。
3.3 朴素贝叶斯算法
3.3.1 朴素贝叶斯算法介绍
朴素贝叶斯算法的原理是通过某对象的先验概率,利用贝叶斯公式计算出它的后验概率(对象属于某一类的概率),选取具有最大后验概率的类作为该对象所属的类。
对于随机变量 和 , 就是 的后验概率, 是 的先验概率,则贝叶斯公式为:
3.3.2 基本假设
(1)特征之间相互独立,即一个特征的出现于其它相邻的特征并无关系;
(2)每个特征同等重要。
3.3.3 计算步骤
(1)计算训练集中每一种综合评级等级下各个评价属性的等级的概率,及每一种综合评级等级的先验概率;
(2)计算测试集中待测数据的每一种综合评级等级下各个评价属性的等级的概率的乘积以及和综合评级等级的积;
(3)计算过程中出现概率为0情况时,使用拉普拉斯平滑进行修正;
(4)综合评级等级对应的最大的乘积所在的数据的综合评价等级即是待测数据的综合评价等级。
四、测试与计算
4.1 kNN算法
在不同的训练数据与测试数据的比例和k的取值下,其结果如表2所示。
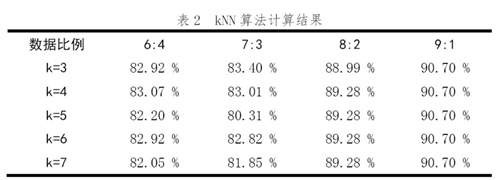
可以看出,相同的训练数据与测试数据的比例下,其k值的改变对结果影响较小,结果基本稳定,且计算结果显示,kNN算法的准确率较高,在训练数据与测试数据的比例为9:1时超过90%的准确率。
4.2 决策树
4.2.1 初步结果
使用决策树方法对评价属性为文字等级的数据集进行测试,训练集和测试集的比例为7:3,初步测试结果的准确率仅为33.40 %,决策树的可视化如图5所示。
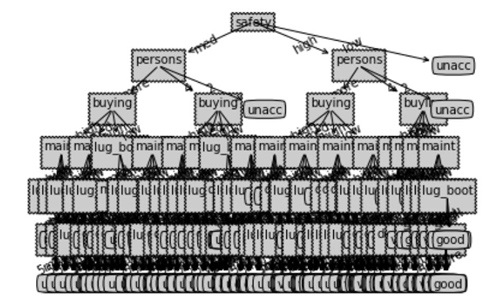
图5 决策树
可以看出,这决策树枝叶繁多,决策树生成算法递归地产生决策树,直到不能继续下去为止。这样产生的树往往对训练数据的分类很准确,但对未知的测试数据的分类却没那么准确,即出现过拟合现象。过拟合的原因在于学习时过多地考虑如何提高对训练数据的正确分类,从而构建出过于复杂的决策树。这就造成了对于测试数据时准确率只有33.40 %。
4.2.2 简化决策树
决策树出现过拟合现象,这是由于数据集中属性较多,使得决策树分类太过仔细。在此将决策树简化为二叉树,在每一个属性的分类中,使用二分的策略,具体是:香农熵最小的作为二叉树的一个子树,剩下的作为二叉数的另一个子树。这样就使得决策树简化为深度为7层的二叉树,结果如图6所示。
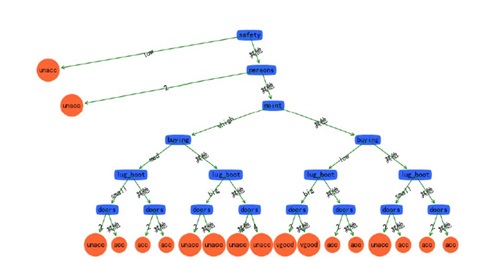
图6 简化后决策树
使用简化后的决策树对上述测试数据在此进行测试,其准确率为83.40%左右。这远远大于没有简化时的准确率。
4.3 朴素贝叶斯算法
使用朴素贝叶斯算法对不同的训练数据与测试数据的比例情况下进行测试,其计算结果如表3所示。

可以看出,在此朴素贝叶斯算法下,其计算结果准确率较低。进一步测试数据集,在训练数据与测试数据的比例约为3:1时,计算结果准确率达到最大值,为85.88%。
五、总结
(1)从计算结果直观上来看,在这三种算法中,kNN算法的计算准确率普遍较高,且kNN算法在训练数据与测试数据的比例为9:1时,其准确率达到90%以上。
但是在每次计算测试数据的类别时,都要进行与训练数据的比较。在这种情况下,其复杂度随着数据量的增大而迅速增长。
(2)决策树在递归地产生决策树时,其枝叶较繁杂,且对未知的测试数据的分类却没那么准确,会出现过拟合现象。
在简化决策树为二叉树后,其准确率提高,且二叉树型的决策树在分类时更加简洁。但对于连续性数据,首先应该将数据进行离散化才能使用决策树。
(3)朴素贝叶斯算法在拉普拉斯平滑修正后,其性能在kNN和决策树之间,但相对于kNN算法,朴素贝叶斯算法的准确率较之低。
朴素贝叶斯算法的优点在于其在数据量较少时仍然适用,且对于多种属性的数据集的效果良好。但其不适用于连续性数据,只能用于离散数据。
六、参考文献
[1]周志华.机器学习[M].北京:清华大学出版社,2016.
[2]Peter Harrington.机器学习实战[M].北京:人民邮电出版社,2013.
[3]韩家炜等.数据挖掘概念与技术[M].北京:机械工业出版社,2012.
七、附录
《机器学习实战》的代码,其代码的资源网址为:
https://www.manning.com/books/machine-learning-in-action
其中,kNN和决策树代码在之前博客中已经给出,现在是朴素贝叶斯的代码。
bayes.py文件为:
from numpy import *
def trainNB0(trainMatrix,trainCategory):
numTrainDocs = len(trainMatrix) #行数
numWords = len(trainMatrix[0]) #列数
pAbusive = sum(trainCategory)/float(numTrainDocs)
p1Num = ones(numWords);p2Num = ones(numWords); #change to ones()
p3Num = ones(numWords);p4Num = ones(numWords);
p1Denom = 2.0; p2Denom = 2.0 #change to 2.0
p3Denom = 2.0; p4Denom = 2.0
for i in range(numTrainDocs):
if trainCategory[i] == 1:
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else:
p2Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = log(p1Num/p1Denom) #change to log()
p0Vect = log(p2Num/p0Denom) #change to log()
return p0Vect,p1Vect,pAbusive
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
p1 = sum(vec2Classify * p1Vec) + log(pClass1) #element-wise mult
p0 = sum(vec2Classify * p0Vec) + log(1.0 - pClass1)
if p1 > p0:
return 1
else:
return 0
"""
errorCount = 0
for docIndex in testSet: #classify the remaining items
wordVector = bagOfWords2VecMN(vocabList, docList[docIndex])
if classifyNB(array(wordVector),p0V,p1V,pSpam) != classList[docIndex]:
errorCount += 1
print ('the error rate is: ',float(errorCount)/len(testSet))
return vocabList,p0V,p1V
"""