个性化推荐理论
基于内容的推荐算法,原理是用户喜欢和自己关注过的Item在内容上类似的Item,比如你看了哈利波特I,基于内容的推荐算法发现哈利波特II-VI,与你以前观看的在内容上面(共有很多关键词)有很大关联性,就把后者推荐给你,这种方法可以避免Item的冷启动问题(冷启动:如果一个Item从没有被关注过,其他推荐算法则很少会去推荐,但是基于内容的推荐算法可以分析Item之间的关系,实现推荐),弊端在于推荐的Item可能会重复,典型的就是新闻推荐,如果你看了一则关于MH370的新闻,很可能推荐的新闻和你浏览过的,内容一致;另外一个弊端则是对于一些多媒体的推荐(比如音乐、电影、图片等)由于很难提内容特征,则很难进行推荐,一种解决方式则是人工给这些Item打标签。
2.协同过滤算法,原理是用户喜欢那些具有相似兴趣的用户喜欢过的商品,比如你的朋友喜欢电影哈利波特I,那么就会推荐给你,这是最简单的基于用户的协同过滤算法(user-based collaboratIve filtering),还有一种是基于Item的协同过滤算法(item-based collaborative filtering),这两种方法都是将用户的所有数据读入到内存中进行运算的,因此成为Memory-based Collaborative Filtering,另一种则是Model-based collaborative filtering,包括Aspect Model,pLSA,LDA,聚类,SVD,Matrix Factorization等,这种方法训练过程比较长,但是训练完成后,推荐过程比较快。
最后一种方法是基于知识的推荐算法,也有人将这种方法归为基于内容的推荐,这种方法比较典型的是构建领域本体,或者是建立一定的规则,进行推荐。
3.混合推荐算法,则会融合以上方法,以加权或者串联、并联等方式尽心融合。
当然,推荐系统还包括很多方法,其实机器学习或者数据挖掘里面的方法,很多都可以应用在推荐系统中,比如说LR、GBDT、RF(这三种方法在一些电商推荐里面经常用到),社交网络里面的图结构等,都可以说是推荐方法。
1 推荐问题的定义
假设C是用户集合,S是所有可能被推荐的条目的集合。那么我们可以在用户集合和条目集合的笛卡尔乘积之上定义一个效用函数u,来衡量条目s对用户c的有用程度,比如:푢:퐶×푆→푅,其中R是一个良序集(例如一定范围内的实数或者非负整数),那么对于任意用户푐∈퐶,我们需要选择条目푠'∈푆从而最大化用户的效用值,也就是说:

其示意图见图1
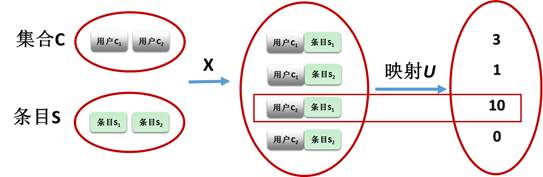
Figure 1. Illustration of Recommendation Algorithm
图1 推荐算法示意图
在一般的推荐系统中,效用值通常用用户评分或者是标记喜欢与否来衡量。但从原始的形式化定义出发,这个效用函数可以是任意形态,比如用户点击、收藏,或停留时间、回访,甚至是网站的销量、利润等,只要它满足效用函数的基本性质(可加性、传递性和三角不等式)。在这样的问题定义框架下,推荐问题转化为优化问题,个性化推荐算法的选择与推荐问题本身相互解耦。
我们只需关心算法对解决问题的效果和算法本身的效率,从而在最大程度上体现了对算法的包容性,各式各样的算法都可以在统一的框架下为最终的优化目标充分展开竞争。
过去20年,个性化推荐算法得到长足的发展和进步。自从20世纪90年代中期第一篇系统介绍协同过滤算法的论文发表以来,针对个性化推荐系统的算法优化,学术界和工业界的研究学者和实践者们从不同的领域出发,提出了各种模型和解决方案。
粗略统计,所涉及到的学科包括人工智能、机器学习、认知科学、信息抽取、数据挖掘、预测理论、近似理论,甚至是管理科学、市场营销和心理学。所使用的算法除了传统的协同过滤,还包括图模型(Graph Model)、矩阵分解(Matrix Factorization)、奇异值分解(SVD,SingularValue Decomposition)、链接分析(Link Analysis)、回归分析(Regression Analysis),以及机器学习领域各种分类和学习算法。
Table 1 Categories of Recommendation Algorithm
表1 推荐算法分类
| 启发式算法 |
基于模型 |
|
| 基于内容 |
TF-IDF 聚类 最大熵 相似度度量 |
贝叶斯分类 决策树 神经网络 专家系统 知识推理 |
| 协同过滤 |
K近邻 聚类 链接分析 关联规则 相似度度量 |
贝叶斯分类 决策树 神经网络 矩阵分解 概率模型 图模型 Boosting Topic Model 回归分析 |
| 混合式 |
线性组合 投票机制 meta-heuristics |
Ensemble 统一推荐框架 |
早期的推荐系统文献中一般从所选取的角度和所采用的技术两个不同的维度对个性化推荐算法进行划分。从选取的角度不同,可以分为基于内容的算法、协同过滤算法,以及混合式算法三大类。从具体技术角度,可以分为基于内存(Memory-based)的算法和基于模型(Model based)的算法两种形式。
2.1 基于内容的算法
基于内容的推荐是从信息抽取领域自然而然发展起来的一类算法,其出发点是在对文本信息和条目元信息进行整理、建模的基础上,针对用户的不同兴趣偏好进行推送。
最初,基于内容的推荐其实是协同过滤的衍生。他不依赖于用户对产品的评价,而是根据用户所选择的产品内容信息计算用户之间的相似度进行推荐的。基于内容的算法根本在于信息获取和信息过滤。因为在文本信息获取与过滤方面较为常数,现有很多基于内容的推荐系统都是通过分析产品的文本信息进行推荐。
在信息抽取领域,最常用的文本抽取方法便是TF-IDF方法:
假设有N个文本文件,关键词푘푖在푛푖个文件中出现,设푓푖푗为关键词푘푖在文件푑푗中出现的次数,那么푘푖在푑푗中的词频푇퐹푖푗定义为:

其中分母的最大值可以通过计算푑푗中所有关键词푘푧的频率得到。
在许多文件中同时出现的关键词对于表示文件的特性, 区分文件的关联性是没有贡献的. 因此TFij与这个关键词在文件中出现数的逆( IDFi ) 一起使用, IDFi的定义为:
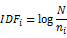
文件dj可表示成向量:
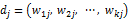
其中:
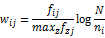
这样,用户的配置文件和产品都可以表示成TD-IDF模型,通过计算两者的相关度进行推荐:
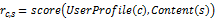
rc,s可以用二者的余弦相似度计算,如:

与基于内容的推荐相对应,协同过滤推荐并不关心条目的具体属性,而是对用户群整体的评分信息进行整理和建模,根据用户行为找出口味相似的用户群或者风格类似的条目,在此基础上进行推荐。
协同过滤算法的核心思想是,先根据用户的历史信息计算用户间的相似度,再根据相似用户的喜好,为邻居用户推荐类似的产品。协同过滤最大特点是对产品格式没有特殊要求,可以处理难以文本化的产品如音乐、视频等。
协同过滤可以分为基于记忆的和基于模型的算法。
基于记忆的算法会根据目前系统中所有打过分的产品进行预测。这一类算法不需要预先训练模型,只需定期对评分数据进行预处理,比如计算用户或条目的相似性,在给用户进行推荐时,整个过程都可以在内存中完成。我们所熟知的基于余弦相似和K近邻的标准协同过滤算法就属于这个范畴,此外还有各种利用聚类做推荐的算法、关联规则、链接分析等。由于这类算法更多强调规则而非模型,有时也把基于内存的算法称为启发式推荐算法。
基于模型的推荐算法则有一个独立的模型训练阶段,利用全体或部分评分数据训练一个模型,这一步一般是离线完成的,在线推荐时则林勇训练好的模型实时做出相应。在这个框架下,可以利用人工智能和机器学习领域多年研究的各种模型和成果,算法的设计和实现过程要更加规范。
现有的推荐系统中,大都使用准确度评价算法的优劣。假设用户可以浏览所有产品条目,并根据自身兴趣爱好对所浏览的产品进行偏好的排序。这样,用户对产品做出的排名与推荐算法预测到的产品排序之间的贴近程度即可定义为准确度。由于系统形式千差万别,因此评价指标难以标准化,在不同系统之间做出比较是很困难的。针对目前不同的系统,已有的准确度指标有:预测准确度、分类准确度、排序准确度、预测打分关联、距离标准化指标和半衰期效用指标。
3.1 预测准确度
预测准确度考虑推荐算法的预测打分与用户实际打分的相似程度。预测准确度的一个经典度量方法是度量系统的预测打分与用户的实际打分的平均绝对误差(Mean Absolute Error)。
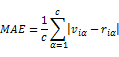
其中,c为系统中用户i打分产品的个数,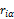 为用户的实际打分,
为用户的实际打分,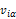 为系统的预测打分。
为系统的预测打分。
这种方法有两个优点:一是计算方法比较简单,便于直观上的理解;二是对于不同的系统,其平局绝对误差是不同的,从而能区别不同系统的绝对误差。
除了平均绝对误差之外,还有平均平方误差(Mean Square Error)和标准平均绝对误差(NormalizedMean Absolute Error)等方法。其中,平均平方误差定义如下:
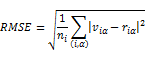
其中, 为系统中用户一产品对
为系统中用户一产品对 的个数。在平局平方误差计算中,预测打分与实际打分作差之后还有一个平方操作,这样打分误差的影响会比平局绝对误差大。
的个数。在平局平方误差计算中,预测打分与实际打分作差之后还有一个平方操作,这样打分误差的影响会比平局绝对误差大。
3.2 分类准确度
分类准确度定义为推荐算法对一个产品用户是否喜欢判定正确的比例。因此,当用户只有二元选择时,用分类准确度进行评价较为合适。而且这种方法受打分稀疏性的影响。虽然目前有一些方法处理打分稀疏性问题,但效果并不理想。
另一种广泛应用的分类准确度指标为准确率、召回率以及相关指标。但准确率和召回率的计算又成了另一个新的问题。另外一个度量系统分类准确度的重要指标就是ROC曲线。