前言
Spark的部署模式有Local、Local-Cluster、Standalone、Yarn、Mesos,其中Yarn和Mesos是类似的,都不需要额外部署Spark集群,其中Yarn也是有Yarn-Client,Yarn-Cluster两种模式。Mesos和Yarn差不多,在这就不详细说明了。
一、Local模式
Local模式分为Local本地模式和Local-Cluster本地伪分布式集群模式,两种具体的构建如下:
| 部署模式 | 说明 |
|---|---|
| “local” | 最简单的本地模式。这种本地模式下,任务的失败重试次数为1,即失败不重试。 |
| local[*]、local[N] | 指定线程个数的本地模式,指定方式及最终的线程数如下:1)local[*]:当前处理器个数。2)local[N]:指定的N。这种本地模式下,任务的失败重试次数为1,即失败不重试。 |
| local[*, M]、local[N, M] | 指定线程个数以及失败重试次数的本地模式,仅比上一种本地模式多了一个失败重试次数的设置,对应为M。 |
| local-cluster[numSlaves, coresPerSlave, memoryPerSlave] | 本地伪分布式集群,由于本地模式下没有集群,因此需要构建一个用于模拟集群的实例:localCluster = new LocalSparkCluster。对应的三个参数:numSlaves:模拟集群的Slave节点个数。coresPerSlave:模拟集群的各个Slave节点上的内核数。memoryPerSlave:模拟集群的各个Slave节点上的内存大小。 |
Local模式适用于在本地IDEA编写Scala程序调试Spark程序时使用。
二、Standalone模式
前面集群安装已经介绍了该模式,这里就不再复述,该模式是经典的集群模式,但该模式没有对集群资源的管理,所以会有Yarn模式和Mesos模式。
三、Yarn模式
首先注意几个概念:
ResourceManager:是集群所有应用程序的资源管理器,能够管理集群的计算资源并为每个Application分配,它是一个纯粹的调度器。
NodeManager:是每一台slave机器的代理,执行应用程序,并监控应用程序的资源使用情况。
Application Master:每一个应用程序都会有一个Application Master,它的主要职责是向RM申请资源、在每个NodeManager上启动executors、监控和跟踪应用程序的进程等。
1、Cluster模式
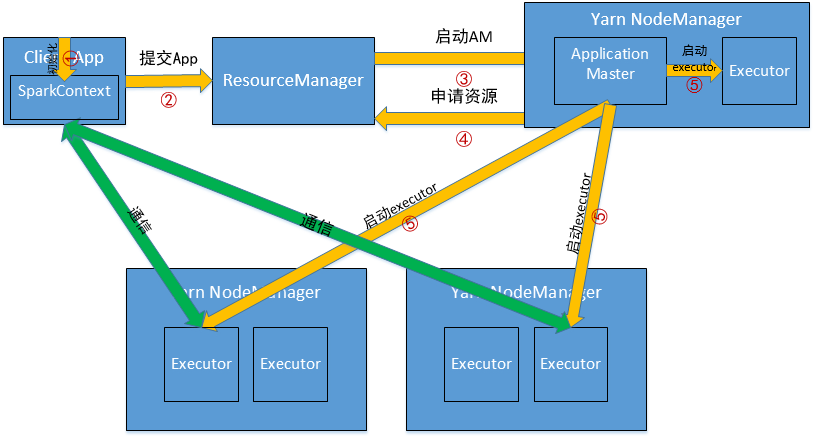
2、Client模式
YARN-Cluster和YARN-Client的区别
(1)SparkContext初始化不同,这也导致了Driver所在位置的不同,YarnCluster的Driver是在集群的某一台NM上,但是Yarn-Client就是在RM在机器上;
(2)而Driver会和Executors进行通信,这也导致了Yarn_cluster在提交App之后可以关闭Client,而Yarn-Client不可以;
(3)最后再来说应用场景,Yarn-Cluster适合生产环境,Yarn-Client适合交互和调试。