Hadoop入门环境搭建
1.基础环境
1.1安装版本
Hadoop2.8.4,
JDK1.8,
Centos7,
VMware Workstation14
1.2在虚拟机安装服务器并配置
我在虚拟机上安装3个centos系统,分别命名为master,slave1,slave2。
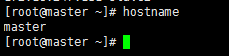
1.2.1 修改服务器名称
使用hostname命令查看机器名称,我的已经修改,如果没有修改分别在三台服务器 上执行 hostname master,hostname slave1,hostname slave2:
1.2.2 配置服务器IP与名称对应,这样我们使用时直接使用名称即可
各服务器名称对应IP如下:

可以通过 vim /etc/hosts修改,如果没有足够的权限,可以切换用户为root。
配置完成后使用ping命令检查这3个机器是否相互ping得通,以master为例,在masters上执行命令:
ping -c 3 slave1,
ping -c 3 slave2,结果如下:
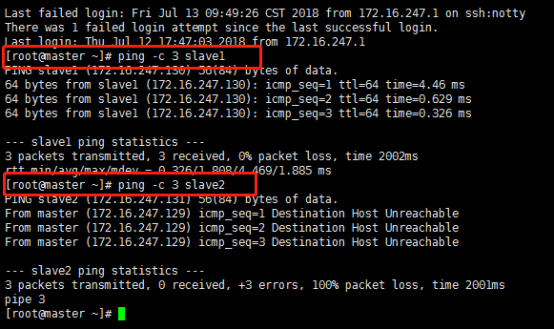
也可登录其他服务器验证是否能ping通
1.3关闭防火墙
CentOS 7默认使用的是firewall作为防火墙,
查看状态:firewall-cmd --state
停止firewall:systemctl stop firewalld.service
禁止firewall开机启动:systemctl disable firewalld.service
2.软件安装与配置
2.1软件安装
软件安装顺序(自行下载,不在赘述):虚拟机、centos、jdk(需要配置环境变量)、Hadoop
在此重点讲述Hadoop安装,其它不是重复,不会的同学自行百度。
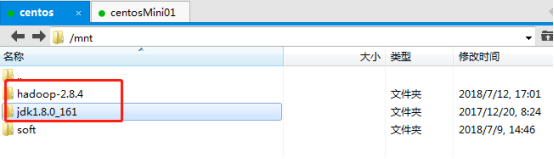
将下载的hadoop-2.8.4.tar.gz上传至master服务器上并解压,目录为:/mnt,
Jdk和Hadoop安装在三台服务器上都需要安装,如图:
2.2 配置ssh进行无密码登录
以master为例:
执行以下命令后,如果提示,就一直按“Enter”键,直至生成公钥
ssh-keygen -t rsa
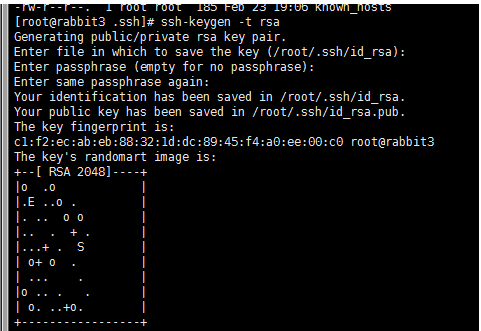
执行完成后会在/root/.ssh目录下生成两个文件id_rsa、id_rsa.pub,其中id_rsa.pub就是我们需要的公钥,在每台服务器上都会生成一个公钥和私钥。
进入master服务器的/root/.ssh目录,新建文件authorized_keys,并将三台服务器生成的公钥合并至authorized_keys文件内,合并完成后,将改文件复制到slave1和slave2
两台服务器的/root/.ssh目录下。
验证:

不用输入密码即可登录,一定要注意的是,每次ssh完成后,都要执行exit,否则你的后续命令是在另外一台机器上执行的。
如果配置完成后,仍需输入密码验证,可修改下面的配置信息:
[root@master ~]# vim /etc/ssh/sshd_config
PermitRootLogin yes
AuthorizedKeysFile .ssh/authorized_keys
PasswordAuthentication yes
2.3 Hadoop配置:
Hadoop安装目录:/mnt/hadoop-2.8.4,进入Hadoop配置文件目录/mnt/hadoop-2.8.4/etc/hadoop,需要配置的文件如下:core-site.xml、hdfs-site.xml、
mapred-site.xml、yarn-site.xml以及slaves文件,
配置前先建一下目录,后面配置文件中会用到:
/root/hadoop-2.8/hdfs
/root/hadoop-2.8/hdfs/name #存放namenode信息
/root/hadoop-2.8/hdfs/data #存放datanode信息
/root/hadoop-2.8/tmp #存放临时数据
2.3.1修改core-site.xml
在<configuration>节点内加入配置:
<configuration> <property> <name>fs.detaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/root/hadoop-2.8/tmp</value> </property> </configuration>
2.3.2 修改hadoop-env.sh
修改/mnt/hadoop-2.8.4/etc/hadoop/hadoop-env.sh文件
将export JAVA_HOME=${JAVA_HOME}
修改为:
export JAVA_HOME=/mnt/jdk1.8.0_161
2.3.3修改hdfs-site.xml
<configuration> <property> <name>dfs.namenode.name.dir</name> <value>file:/root/hadoop-2.8/hdfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/root/hadoop-2.8/hdfs/data</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>master:9001</value> </property> </configuration>
2.3.4新建并且修改mapred-site.xml
有一个名为mapred-site.xml.template的文件,复制该文件,然后改名为mapred-site.xml,
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/root/hadoop-2.8/tmp</value> </property> </configuration>
2.3.5修改slaves文件
#localhost
slave1
slave2
2.3.6修改yarn-site.xml文件
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>master:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>master:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>master:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>master:8088</value> </property> </configuration>
以上配置文件的修改三台服务器都要修改,可以先将主服务器配置完成后,远程复制到从服务器上
3.启动Hadoop,在master上操作即可:
3.1格式化
进入/mnt/hadoop-2.8.4/bin,执行初始化脚本,也就是执行命令:
./hadoop namenode -format
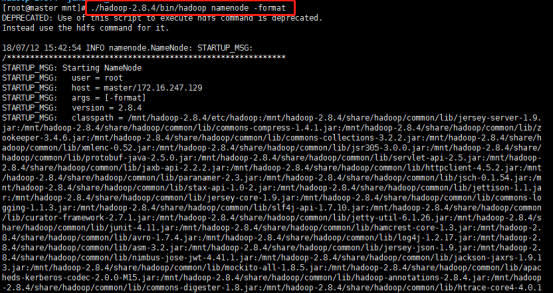
执行完结果:
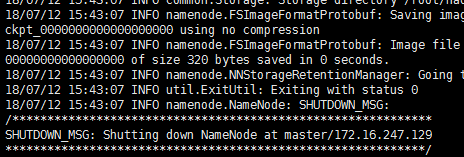
格式化完成。
3.2启动并使用jps查看
进入/mnt/hadoop-2.8.4/sbin,执行下面红色的命令:

启动完成后,在两台从服务器上查看结果如下:
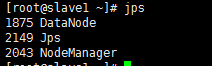
4.测试 Hadoop入门之WordCount
4.1 在/root/hadoop-2.8/file新建一下两个文件:
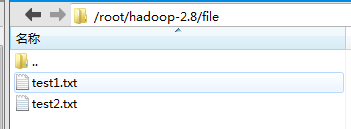
test1.txt内容如下:hello world hello me!
test2.txt内容如下:hello hadoop hello you!
4.2 进入hadoop安装的bin目录 在hdfs上创建一个新文件夹
[root@master hadoop-2.8.4]# bin/hdfs dfs -mkdir -p test_input
4.3将/root/hadoop-2.8/file下的文件上传至test_input目录:
[root@master hadoop-2.8.4]#
bin/hdfs dfs -put /root/hadoop-2.8/file/test*.txt test_input
4.4 查看[root@master hadoop-2.8.4]# bin/hdfs dfs -ls test_input

4.5执行如下命令:
[root@master hadoop-2.8.4]#
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.4.jar wordcount test_input output

查看结果:
