一、磁力链接
现在我们使用迅雷等工具下载资源的时候,基本上都只需要一个叫做磁力链接的东西就可以了,非常方便。
二、磁力定义
磁力链接是对等网络中进行信息检索和下载文档的电脑程序。和基于“位置”连接的统一资源定位符不同,磁力链接是基于元数据文件内容,属于统一资源名称。也就是说,磁力链接不基于文档的 IP 地址或定位符,而是在分布式数据库中,通过散列函数值来识别、搜索来下载文档。因为不依赖一个处于启动状态的主机来下载文档,所以特别适用没有中心服务器的对等网络。
磁力链接格式类似于 magnet:?xt=urn:btih:E7FC73D9E20697C6C440203F5884EF52F9E4BD28
分解一下这个链接
magnet:协议名。
xt:exact topic 的缩写,表示资源定位点。BTIH(BitTorrent Info Hash)表示哈希方法名,这里还可以使用 SHA1 和 MD5。这个值是文件的标识符,是不可缺少的。
一般来讲,一个磁力链接只需要上面两个参数即可找到唯一对应的资源。也有其他的可选参数提供更加详细的信息。
dn:display name 的缩写,表示向用户显示的文件名。
tr:tracker 的缩写,表示 tracker 服务器的地址。
kt: 关键字,更笼统的搜索,指定搜索关键字而不是特定文件。
mt:文件列表,链接到一个包含磁力链接的元文件 (MAGMA - MAGnet MAnifest)。
扫描二维码关注公众号,回复: 2211247 查看本文章
这里可以阅读阮一峰的 BT 下载的未来,我很喜欢他文章的最后一句话。
当互联网上每一台机器都在自动交换信息的时候,谎言和封锁又能持续多久呢?
三、种子/DHT
通过磁力就可以获取种子文件从而进行下载,这跟直接使用种子下载时一个道理的,只是少了从磁力到种子文件的一个过程而已。


1.种子定义
BitTorrent 协议的种子文件可以保存一组文件的元数据。这种格式的文件被 BitTorrent 协议所定义。扩展名一般为“.torrent”。
2.种子结构
.torrent 种子文件本质上是文本文件,包含 Tracker 信息和文件信息两部分。Tracker 信息主要是 BT 下载中需要用到的 Tracker 服务器的地址和针对 Tracker 服务器的设置,文件信息是根据对目标文件的计算生成的,计算结果根据 BitTorrent 协议内的 Bencode 规则进行编码。它的主要原理是需要把提供下载的文件虚拟分成大小相等的块,块大小必须为2k的整数次方(由于是虚拟分块,硬盘上并不产生各个块文件),并把每个块的索引信息和 Hash 验证码写入种子文件中;所以,种子文件就是被下载文件的“索引”。
4.种子-磁力联系
磁力链接的唯一标识符就是 40 个 16 进制字符码,也就是magnet:?xt=urn:btih:E7FC73D9E20697C6C440203F5884EF52F9E4BD28中的E7FC73D9E20697C6C440203F5884EF52F9E4BD28。这个同时也是种子文件的 info_hash,是每个种子的唯一标识码。根据它就能将磁力链接于种子联系起来,得到资源的详细信息,进而下载资源。
3.DHT
BitTorrent 使用”分布式哈希表”(DHT)来为无 tracker 的种子(torrents)存储 peer 之间的联系信息。这样每个 peer 都成了 tracker。这个协议基于 Kademila 网络并且在 UDP 上实现。DHT 由节点组成,它存储了 peer 的位置。BitTorrent 客户端包含一个 DHT 节点,这个节点用来联系 DHT 中其他节点,从而得到 peer 的位置,进而通过 BitTorrent 协议下载。
peer: 一个 TCP 端口上监听的客户端/服务器,它实现了 BitTorrent 协议。
节点: 一个 UDP 端口上监听的客户端/服务器,它实现了 DHT(分布式哈希表) 协议。
如果对 DHT 协议感兴趣的话一定要看下 DHT 协议 的具体内容,这里有 中文翻译版本。(想要彻底读懂项目的话一定要先了解该协议,代码都是基于该协议实现的,我也是反复的阅读了好几遍。)
四、项目来源
一般来讲到 Python 爬取,大家的第一印象可能就是 requests/aiohttp,或者是 scrapy/pyspider 等爬虫框架。基本上都是从指定的 HTML 页面爬取信息。我有一个项目 torrent-cli 就是一个从资源网站上爬取磁力信息的工具。

然而我

想自给自足获取磁力种子,Google 了一番,发现大家基本上的代码都是从 simDHT 这个项目来的,首先这个项目很棒,但是些问题如代码不规范、实现细节基本没有一行注释、不兼容 Python3。然而很多网上同类的代码基本上也是对这个完全照搬….

所以我知道我要开始干活了

经过一波 happy coding 之后。
当然最后还是给码出来了啦

五、项目结构
核心代码
#! usr/bin/python
# encoding=utf8
import socket
import codecs
import time
from threading import Thread
from collections import deque
from multiprocessing import Process, cpu_count
import bencoder
from .utils import get_logger, get_nodes_info, get_rand_id, get_neighbor
from .database import RedisClient
# 服务器 tracker
BOOTSTRAP_NODES = [
("router.bittorrent.com", 6881),
("dht.transmissionbt.com", 6881),
("router.utorrent.com", 6881),
]
# 双端队列容量
MAX_NODE_QSIZE = 10000
# UDP 报文 buffsize
UDP_RECV_BUFFSIZE = 65535
# 服务 host
SERVER_HOST = "0.0.0.0"
# 服务端口
SERVER_PORT = 9090
# 磁力链接前缀
MAGNET_PER = "magnet:?xt=urn:btih:{}"
# while 循环休眠时间
SLEEP_TIME = 0
# 节点 id 长度
PER_NID_LEN = 20
# 是否使用全部进程
ALL_PROCESSES = False
class HNode:
def __init__(self, nid, ip=None, port=None):
self.nid = nid
self.ip = ip
self.port = port
class DHTServer:
def __init__(self, bind_ip, bind_port):
self.bind_ip = bind_ip
self.bind_port = bind_port
self.nid = get_rand_id()
# nodes 节点是一个双端队列
self.nodes = deque(maxlen=MAX_NODE_QSIZE)
# KRPC 协议是由 bencode 编码组成的一个简单的 RPC 结构,使用 UDP 报文发送。
self.udp = socket.socket(
socket.AF_INET, socket.SOCK_DGRAM, socket.IPPROTO_UDP
)
# UDP 地址绑定
self.udp.bind((self.bind_ip, self.bind_port))
# redis 客户端
self.rc = RedisClient()
self.logger = get_logger("logger_{}".format(bind_port))
def bootstrap(self):
"""
利用 tracker 服务器,伪装成 DHT 节点,加入 DHT 网络
"""
for address in BOOTSTRAP_NODES:
self.send_find_node(address)
def send_krpc(self, msg, address):
"""
发送 krpc 协议
:param msg: 发送 UDP 报文信息
:param address: 发送地址,(ip, port) 元组
"""
try:
# msg 要经过 bencode 编码
self.udp.sendto(bencoder.bencode(msg), address)
except:
pass
def send_error(self, tid, address):
"""
发送错误回复
"""
msg = dict(t=tid, y="e", e=[202, "Server Error"])
self.send_krpc(msg, address)
def send_find_node(self, address, nid=None):
"""
发送 find_node 请求。
`find_node 请求`
find_node 被用来查找给定 ID 的节点的联系信息。这时 KPRC 协议中的
"q" == "find_node"。find_node 请求包含 2 个参数,第一个参数是 id,
包含了请求节点的 ID。第二个参数是 target,包含了请求者正在查找的
节点的 ID。当一个节点接收到了 find_node 的请求,他应该给出对应的
回复,回复中包含 2 个关键字 id 和 nodes,nodes 是字符串类型,
包含了被请求节点的路由表中最接近目标节点的 K(8) 个最接近的节点的联系信息。
`示例`
参数: {"id" : "<querying nodes id>", "target" : "<id of target node>"}
回复: {"id" : "<queried nodes id>", "nodes" : "<compact node info>"}
:param address: 地址元组(ip, port)
:param nid: 节点 id
"""
nid = get_neighbor(nid) if nid else self.nid
tid = get_rand_id()
msg = dict(
t=tid,
y="q",
q="find_node", # 指定请求为 find_node
a=dict(id=nid, target=get_rand_id()),
)
self.send_krpc(msg, address)
def send_find_node_forever(self):
"""
循环发送 find_node 请求
"""
self.logger.info("send find node forever...")
while True:
try:
# 弹出一个节点
node = self.nodes.popleft()
self.send_find_node((node.ip, node.port), node.nid)
time.sleep(SLEEP_TIME)
except IndexError:
# 一旦节点队列为空,则重新加入 DHT 网络
self.bootstrap()
def save_magnet(self, info_hash):
"""
将磁力链接保存到数据库
:param info_hash: 磁力链接的 info_hash
"""
# 使用 codecs 解码 info_hash
hex_info_hash = codecs.getencoder("hex")(info_hash)[0].decode()
self.rc.add_magnet(MAGNET_PER.format(hex_info_hash))
# self.logger.info("Add a new magnet.")
def on_message(self, msg, address):
"""
负责返回信息的处理
:param msg: 报文信息
:param address: 报文地址
"""
try:
# `回复`
# 对应于 KPRC 消息字典中的 y 关键字的值是 r,包含了一个附加的关键字 r。
# 关键字 r 是字典类型,包含了返回的值。发送回复消息是在正确解析了请求消息的
# 基础上完成的。
if msg[b"y"] == b"r":
# nodes 是字符串类型,包含了被请求节点的路由表中最接近目标节点
# 的 K个最接近的节点的联系信息。
if msg[b"r"].get(b"nodes", None):
self.on_find_node_response(msg)
# `请求`
# 对应于 KPRC 消息字典中的 y 关键字的值是 q,它包含 2 个附加的关键字
# q 和 a。关键字 q 是字符串类型,包含了请求的方法名字。关键字 a 一个字典
# 类型包含了请求所附加的参数。
# 而实际上我们只需要获取这两者中的 info hash,用于构造磁力链接进而获取种子。
elif msg[b"y"] == b"q":
# get_peers 与 torrent 文件的 info_hash 有关。这时 KPRC 协议中的
# "q" = "get_peers"。get_peers 请求包含 2 个参数。第一个参数是 id,
# 包含了请求节点的 ID。第二个参数是 info_hash,它代表 torrent 文件的 info_hash
if msg[b"q"] == b"get_peers":
self.on_get_peers_request(msg, address)
# announce_peer 表明请求的节点正在某个端口下载 torrent
# 文件。announce_peer 包含 4 个参数。第一个参数是 id,包含了请求节点的 ID;
# 第二个参数是 info_hash,包含了 torrent 文件的 info_hash;第三个参数是 port
# 包含了整型的端口号,表明 peer 在哪个端口下载;第四个参数数是 token,
# 这是在之前的 get_peers 请求中收到的回复中包含的。
elif msg[b"q"] == b"announce_peer":
self.on_announce_peer_request(msg, address)
except KeyError:
pass
def on_find_node_response(self, msg):
"""
解码 nodes 节点信息,并存储在双端队列
:param msg: 节点报文信息
"""
nodes = get_nodes_info(msg[b"r"][b"nodes"])
for node in nodes:
nid, ip, port = node
# 进行节点有效性判断
if len(nid) != PER_NID_LEN or ip == self.bind_ip:
continue
# 将节点加入双端队列
self.nodes.append(HNode(nid, ip, port))
def on_get_peers_request(self, msg, address):
"""
处理 get_peers 请求,获取 info hash
:param msg: 节点报文信息
:param address: 节点地址
"""
tid = msg[b"t"]
try:
info_hash = msg[b"a"][b"info_hash"]
self.save_magnet(info_hash)
except KeyError:
# 没有对应的 info hash,发送错误回复
self.send_error(tid, address)
def on_announce_peer_request(self, msg, address):
"""
处理 get_peers 请求,获取 info hash
:param msg: 节点报文信息
:param address: 节点地址
"""
tid = msg[b"t"]
try:
info_hash = msg[b"a"][b"info_hash"]
self.save_magnet(info_hash)
except KeyError:
# 没有对应的 info hash,发送错误回复
self.send_error(tid, address)
def receive_response_forever(self):
"""
循环接受 udp 数据
"""
self.logger.info(
"receive response forever {}:{}".format(
self.bind_ip, self.bind_port
)
)
# 首先加入到 DHT 网络
self.bootstrap()
while True:
try:
# 接受返回报文
data, address = self.udp.recvfrom(UDP_RECV_BUFFSIZE)
# 使用 bdecode 解码返回数据
msg = bencoder.bdecode(data)
# 处理返回信息
self.on_message(msg, address)
time.sleep(SLEEP_TIME)
except Exception as e:
self.logger.warning(e)
def _start_thread(offset):
"""
启动线程
:param offset: 端口偏移值
"""
dht = DHTServer(SERVER_HOST, SERVER_PORT + offset)
Thread(target=dht.send_find_node_forever).start()
Thread(target=dht.receive_response_forever).start()
def start_server():
"""
多线程启动服务
"""
max_process = 1
if ALL_PROCESSES:
max_process = cpu_count()
processes = []
for i in range(max_process):
processes.append(Process(target=_start_thread, args=(i,)))
for p in processes:
p.start()
for p in processes:
p.join()
从 DHT 网络中获取磁力链接。主要是利用一些大型的服务器 tracker,冒充 DHT 节点,使用 UDP 协议加入到 DHT 网络中搜索一波以及和其他节点搞好关系,让他们也分享我点资源。

磁力数据存放在了 redis,利用 redis 的集合特性来去重。使用了多线程/多进程,用于提高爬取效率。在我的本地机器(i7-7700HQ/16G 内存/8M 网速)跑了一下,效果还不错,4 小时爬了 100 万条磁力链接。
$ redis-cli
127.0.0.1:6379> scard magnets
(integer) 1137627
然后代码推送到我那台 性能强悍 1 核/2G 内存/1M 网速 阿里云服务器跑一下,哎….

#!usr/bin/python
# encoding=utf8
from http.client import HTTPConnection
import json
from .database import RedisClient
SAVE_PATH = ".\\torrents"
STOP_TIMEOUT = 60
MAX_CONCURRENT = 16
MAX_MAGNETS = 256
ARIA2RPC_ADDR = "127.0.0.1"
ARIA2RPC_PORT = 6800
rd = RedisClient()
def get_magnets():
"""
获取磁力链接
"""
mgs = rd.get_magnets(MAX_MAGNETS)
for m in mgs:
# 解码成字符串
yield m.decode()
def exec_rpc(magnet):
"""
使用 rpc,减少线程资源占用,关于这部分的详细信息科参考
https://aria2.github.io/manual/en/html/aria2c.html?highlight=enable%20rpc#aria2.addUri
"""
conn = HTTPConnection(ARIA2RPC_ADDR, ARIA2RPC_PORT)
req = {
"jsonrpc": "2.0",
"id": "magnet",
"method": "aria2.addUri",
"params": [
[magnet],
{
"bt-stop-timeout": str(STOP_TIMEOUT),
"max-concurrent-downloads": str(MAX_CONCURRENT),
"listen-port": "6881",
"dir": SAVE_PATH,
},
],
}
conn.request(
"POST",
"/jsonrpc",
json.dumps(req),
{"Content-Type": "application/json"},
)
res = json.loads(conn.getresponse().read())
if "error" in res:
print("Aria2c replied with an error:", res["error"])
def magnet2torrent():
"""
磁力转种子
"""
for magnet in get_magnets():
exec_rpc(magnet)
利用 aria2 将磁力链接转换为种子文件。尝试了一些其他的方式将磁力转换为种子,但效果好像都不怎么理想。使用过 libtorrent 的 Python 版本,不知道是我打开方式不对还是它本来效率就不高,反正愣是一个种子都没有转换成功。

最后兜兜转转用到了 aria2 发现效率还可以。但是要先把 aria2 安装到你的 PATH 中,具体参考官网介绍。使用其 RPC 特性,节省线程开销。

#!/usr/bin/env python
# coding=utf-8
import os
import codecs
from pprint import pprint
from bencoder import bdecode
TORRENT_SAVE_PATH = "torrents"
class ParserTorrent:
def __init__(self, torrent):
self.meta_info = self.get_meta_info(torrent)
@staticmethod
def get_meta_info(torrent):
"""
返回解码后的 meta info 字典
"""
with open(torrent, "rb") as f:
return bdecode(f.read())
def is_files(self):
"""
判断种子文件为单文件或者多文件
"""
if b"files" in self.meta_info[b"info"]:
return True
return False
def get_creation_date(self):
if b"creation date" in self.meta_info:
return self.meta_info[b"creation date"]
def _get_single_filename(self):
"""
获取种子单个文件名
"""
info = self.meta_info[b"info"]
if b"name.utf-8" in info:
filename = info[b"name.utf-8"]
else:
filename = info[b"name"]
for c in filename:
if c == "'":
filename = filename.replace(c, "\\'")
return filename.decode()
def _get_multi_filename(self):
"""
获取种子多个文件名
"""
files = self.meta_info[b"info"][b"files"]
info = []
for item in files:
for k, v in item.items():
if isinstance(v, list):
try:
v = [i.decode() for i in v]
except:
continue
elif isinstance(v, int):
v = round(v / 1024 / 1024, 2)
else:
v = codecs.getencoder("hex")(v)[0].decode()
info.append((k.decode(), v))
return info
def get_filename(self):
"""
获取种子文件名
"""
if self.is_files():
return self._get_multi_filename()
else:
return self._get_single_filename()
def get_createby(self):
"""
返回创建种子创建时间
"""
if b"created by" in self.meta_info:
return self.meta_info[b"created by"]
def parse_torrent():
for _, _, files in os.walk(TORRENT_SAVE_PATH):
for file in files:
info = ParserTorrent(os.path.join(TORRENT_SAVE_PATH, file))
print(TORRENT_SAVE_PATH, file)
pprint(info.get_filename())
print()
解析种子文件内容,同样也是利用了 Bencode 进行解码。有了种子我们当然要看看到底是些什么资源了啦。你说世界就是这么小,在我解析出来的几百个种子文件中,居然有几个都是一个社区的,那个以 1024 为标志的社区。

有图有真相
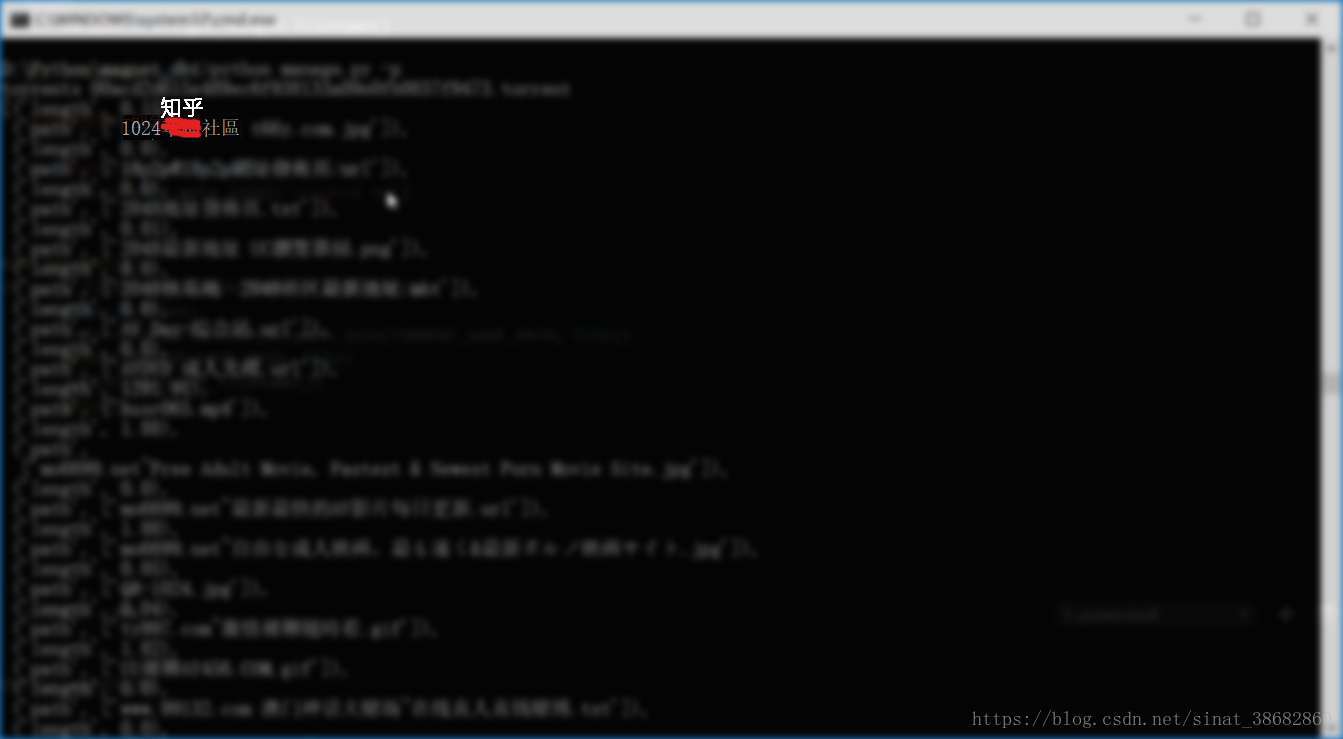
不过我还是希望大家铭记下面这 24 字箴言
辅助代码
database.py:封装了关于 redis 的数据操作,主要是利用其集合数据结构。
#!/usr/bin/env python
# coding=utf-8
import redis
# redis key
REDIS_KEY = "magnets"
# redis 地址
REDIS_HOST = "localhost"
# redis 端口
REDIS_PORT = 6379
# redis 密码
REDIS_PASSWORD = None
# redis 连接池最大连接量
REDIS_MAX_CONNECTION = 20
class RedisClient:
def __init__(
self, host=REDIS_HOST, port=REDIS_PORT, password=REDIS_PASSWORD
):
conn_pool = redis.ConnectionPool(
host=host,
port=port,
password=password,
max_connections=REDIS_MAX_CONNECTION,
)
self.redis = redis.Redis(connection_pool=conn_pool)
def add_magnet(self, magnet):
"""
新增磁力链接
"""
self.redis.sadd(REDIS_KEY, magnet)
def get_magnets(self, count=128):
"""
返回指定数量的磁力链接
"""
return self.redis.srandmember(REDIS_KEY, count)
utils.py:一些工具函数
#!usr/bin/python
# encoding=utf8
import os
import logging
from struct import unpack
from socket import inet_ntoa
# 每个节点长度
PER_NODE_LEN = 26
# 节点 id 长度
PER_NID_LEN = 20
# 节点 id 和 ip 长度
PER_NID_NIP_LEN = 24
# 构造邻居随机结点
NEIGHBOR_END = 12
# 日志等级
LOG_LEVEL = logging.INFO
def get_rand_id():
"""
生成随机的节点 id,长度为 20 位
"""
return os.urandom(PER_NID_LEN)
def get_neighbor(target):
"""
生成随机 target 周边节点 id
:param target: 节点 id
"""
return target[:NEIGHBOR_END] + get_rand_id()[NEIGHBOR_END:]
def get_nodes_info(nodes):
"""
解析 find_node 回复中 nodes 节点的信息
:param nodes: 节点薪资
"""
length = len(nodes)
# 每个节点单位长度为 26 为,node = node_id(20位) + node_ip(4位) + node_port(2位)
if (length % PER_NODE_LEN) != 0:
return []
for i in range(0, length, PER_NODE_LEN):
nid = nodes[i:i + PER_NID_LEN]
# 利用 inet_ntoa 可以返回节点 ip
ip = inet_ntoa(nodes[i + PER_NID_LEN:i + PER_NID_NIP_LEN])
# 解包返回节点端口
port = unpack("!H", nodes[i + PER_NID_NIP_LEN:i + PER_NODE_LEN])[0]
yield (nid, ip, port)
def get_logger(logger_name):
"""
返回日志实例
"""
logger = logging.getLogger(logger_name)
logger.setLevel(LOG_LEVEL)
fh = logging.StreamHandler()
fh.setFormatter(
logging.Formatter("%(asctime)s - %(levelname)s - %(message)s")
)
logger.addHandler(fh)
return logger
六、如何使用
1.获取源码及安装依赖环境
确保已经安装好 redis,redis 的具体配置可以在 database.py 里面修改
$ git clone https://github.com/chenjiandongx/magnet-dht.git
$ cd magnet-dht
$ pip install -r requirements.txt
2.运行项目
进程数量可以在 crawler.py 进行调整
$ python manage.py -h
usage: manage.py [-h] [-s] [-m] [-p]
start manage.py with flag.
optional arguments:
-h, --help show this help message and exit
-s run start_server func.
-m run magnet2torrent func
-p run parse_torrent func
Note:在运行 python manage.py -m 的时候,要先开个终端窗口启动 aria2c 服务。
$ aria2c --enable-rpc=true --bt-metadata-only=true --bt-save-metadata=true
七、深刻的感悟
自我接触编程以来,我一直都是属于兴趣驱动的,对某种技术感兴趣的话就会花时间去研究去尝试。想成为一个有趣的人,去做一些有趣的事。
真心觉得能把脑海里的想法转变为代码实现是件很棒的事,即使可能这件事在别人看来并没有什么了不起。技术发展变化总是那么快,不紧跟着可能不小心就掉队了。所以希望每个真心热爱编程的人都能不忘初心,永远保持对新技术的热情,永远能从编码中找到乐趣。
python学习交流群:125240963
作者:chenjiandongx
原文:https://github.com/chenjiandongx/magnet-dht