一、基本原理
1. 模型形式
假设数据集为,对于每个
,有
个属性。则模型如下
其中,
,
2. 模型求解
模型预测值与实际值越接近,则模型越好,所以定义损失函数
当损失函数取到最小值时,模型最优。即当损失函数对w的导数为0时,取得最小值,考虑到矩阵求导后的结果存在可不可逆的情况,故更改损失函数的表达形式,写成标量的形式来进行求导。
针对某一个样本,模型预测后的结果为
,那么算式函数改写为:
对进行求导,可得
根据梯度下降,每次迭代对参数进行更新
其中为学习率,该参数太大会找不到极小值,太小迭代次数就会增多。
由于每次更新模型参数,都需要将整个样本带入模型计算,耗时会很大,可采用小批量梯度下降,可以很好地解决这个问题。先将整个样本分成一堆小份,每一份含有batch_size个样本,每次计算完一份,就对参数进行更新。
二、代码实现
#author jiangshan
#data 2018-7-16
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
# data prepare
diabetes = datasets.load_diabetes()
diabetes_X = diabetes['data'][:,2]
diabetes_X_train = diabetes_X[:-20]
diabetes_X_test = diabetes_X[-20:]
diabetes_y_train = diabetes['target'][:-20]
diabetes_y_test = diabetes['target'][-20:]
dim_num = 1
learn_rate = 0.01
sample_num = diabetes_X_train.shape[0]
batch_size = 20
w = np.zeros((dim_num+1,1))
x = np.ones((sample_num, dim_num+1))
y = diabetes_y_train.reshape((sample_num,1))
diabetes_X_train = diabetes_X_train.reshape((sample_num,dim_num))
x[:,0:-1] = diabetes_X_train
# train
while(1):
w0 = w.copy()
for j in range(dim_num+1):
grad_j = 0
h = np.dot(x, w)
for k in range(sample_num):
grad_j = grad_j + (h[k,0]-y[k,0])*x[k,j]
if((k+1) % batch_size==0):
w[j,0] = w[j,0] - learn_rate*grad_j
h = np.dot(x, w)
grad_j = 0
w[j,0] = w[j,0] - learn_rate*grad_j
if(sum(abs(w-w0))<0.01):
break
# predict
test_num = diabetes_X_test.shape[0]
test_x = np.ones((test_num,dim_num+1))
test_x[:,0:-1]=diabetes_X_test.reshape((test_num,dim_num))
test_y = diabetes_y_test.reshape((test_num,1))
pred_y = np.dot(test_x,w)
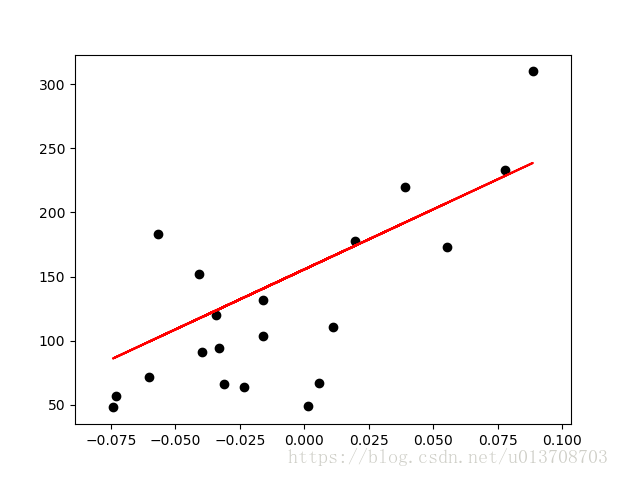
# visualize
plt.scatter(test_x[:,0],test_y[:,0],color='black')
plt.plot(test_x[:,0],pred_y[:,0],color='red')
plt.show()效果图:
三、调用sklearn库
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, linear_model
from sklearn.metrics import mean_squared_error,r2_score
diabetes = datasets.load_diabetes()
diabetes_X = diabetes['data'][:,np.newaxis,2]
diabetes_X_train = diabetes_X[:-20]
diabetes_X_test = diabetes_X[-20:]
diabetes_y_train = diabetes['target'][:-20]
diabetes_y_test = diabetes['target'][-20:]
regr = linear_model.LinearRegression()
regr.fit(diabetes_X_train,diabetes_y_train)
diabetes_y_pred= regr.predict(diabetes_X_test)
print('Coefficients: \n',regr.coef_)
print('Mean squared error: %.2f' % mean_squared_error(diabetes_y_test, diabetes_y_pred))
print('Variance score: %.2f' % r2_score(diabetes_y_test,diabetes_y_pred))
plt.scatter(diabetes_X_test,diabetes_y_test,color='black')
plt.plot(diabetes_X_test,diabetes_y_pred,color='blue',linewidth=3)
plt.xticks(())
plt.yticks(())
plt.show()