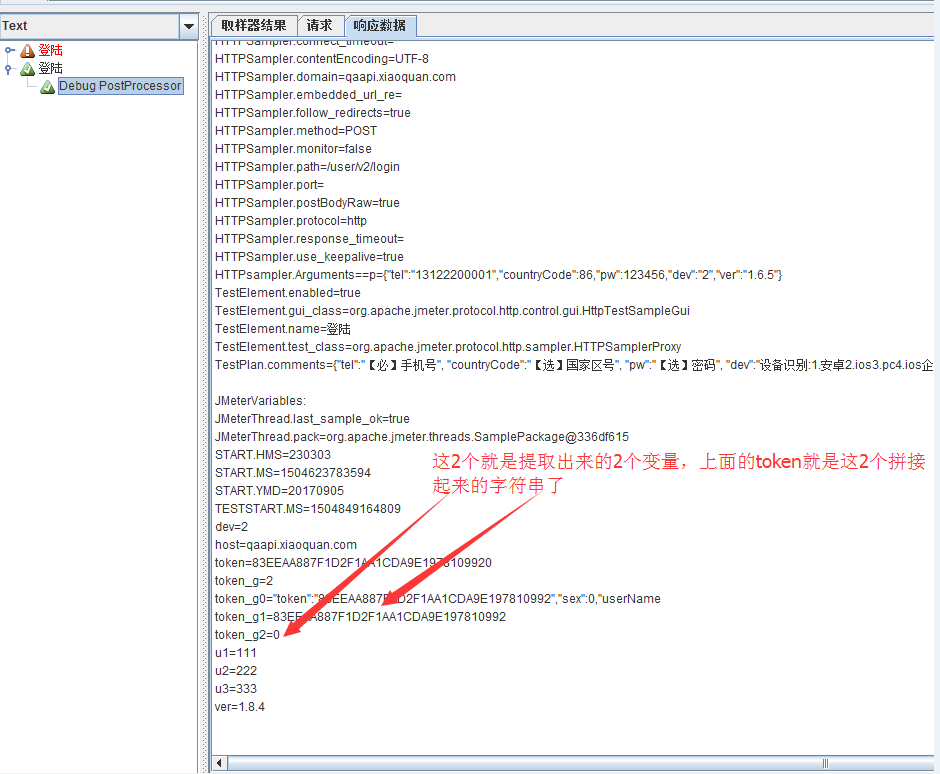
jmeter自带后置处理器:正则表达式提取器,可以用来提取接口响应里的信息,给予后续接口传参用。
例如要提取响应结果里的token字段及sex字段(响应内容为:

"token":"83EEAA887F1D2F1AA1CDA9E197810992","sex":0,"userName":"12548650"),提取器如下设置,
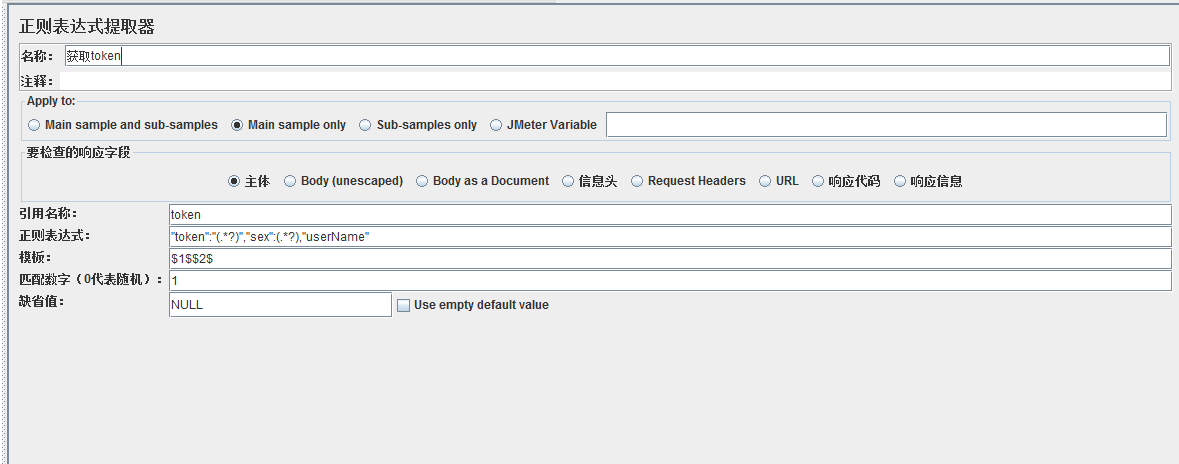
正则表达式提取器说明:
Apply to:应用范围(一般就选择默认的Main sample only),就算有重定向,一般也是提取最终那个请求的接口。
要检查的响应字段:样本数据源。
主体: 接口响应主体内容,一般要提取普通http响应结果的数据,都勾选这个。
信息头:响应头的所有内容。
Request Headers:请求头的所有内容。
url:是对sample的url进行匹配,也就是查看结果树里请求内容的第一行url,不包含data里的请求参数(即只能匹配protocol(协议)+host+path+querystring,如:https://www.baidu.com/index.php?tn=monline_3_dg)。
响应代码:http响应代码,如101,200,302,404,501等。
响应信息:http响应代码对应的响应信息,例如:OK, Found(HTTP/1.1 200 Ok;HTTP/1.1 302 Found)。
引用名称:其他地方引用时的变量名称,名称只能是一个,引用方法:${token}。如图
正则表达式:数据提取器,一般简单的通用语法就是:左边界(.*?)右边界,左右边界就是为了能准确定位到想匹配的内容,如最上面图的"token":"(.*?)","sex":(.*?),"userName", 其中"token":"以及","sex": 和,"userName"这3个就是左右边界,(.*?) 是替换了想要提取的内容,里面的'?'为非贪婪匹配,(非贪婪模式就是说在遇到第一个右边界后就停止匹配,这样就可以精确拿到想要的内容)。建议均使用非贪婪匹配,除非特殊情况。
模板:对应正则表达式提取器类型,样式为:$n$。若模板为:$0$,则为整个表达式匹配到的内容,就是包括小括号内跟小括号外的内容,即("token":"83EEAA887F1D2F1AA1CDA9E197810992","sex":0,"userName")。若模板为:$1$,则对应正则表达式中的第一个(.*?)所匹配的内容,即(83EEAA887F1D2F1AA1CDA9E197810992) ,若模板为:$2$,则对应正则表达式中的第二个(.*?)所匹配的内容,即(0),若模板为$1$$2$,则把2个(.*?)所匹配的内容拼接起来,即(83EEAA887F1D2F1AA1CDA9E1978109920)。模板是可以自由组合的,后续案例中再介绍。
匹配数字:正则表达式匹配数据的最终结果可以看做一个数组,匹配数字即可看做是数组的第几个元素。当为 0 时,随机返回匹配的数据。当为 1 时,表示返回匹配结果数组的第一个元素。当为负数(-1,-2,-100都可以)时,表示返回全部元素,并且同时会返回一个元素总数的变量token_matchNr,在引用时:通过${token_1}的方式来取第1个匹配的内容,${token_2}来取第2个匹配的内容。
缺省值:匹配失败时的默认值。通常用于后续的逻辑判断,建议使用一些特殊含义的,比如0,NULL,ERROR等。
正则测试:
可以直接在察看结果树里选择Regexp正则测试模式来测试正则是否写的正确。
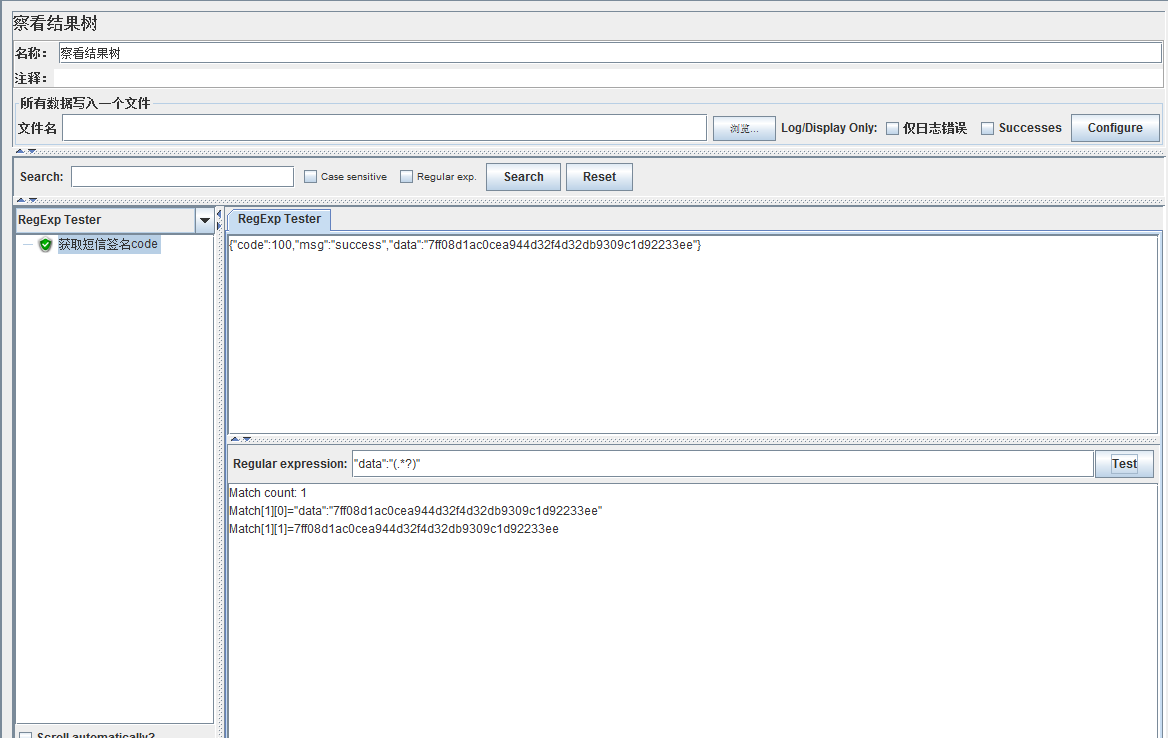
正则结果查看:
如何查看提取到了想要的内容呢,这里就需要提到另外一个后置处理器:Debug PostProcessor
该元件就为调试所用,一般用于查看变量值,添加方法同正则表达式提取器。