链接:https://www.zhihu.com/question/35887527/answer/73048322
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
首先膜拜RBG(Ross B. Girshick)大神,不仅学术牛,工程也牛,代码健壮,文档详细,clone下来就能跑。
断断续续接触detection几个月,将自己所知做个大致梳理,业余级新手,理解不对的地方还请指正。
传统的detection主流方法是DPM(Deformable parts models), 在VOC2007上能到43%的mAP,虽然DPM和CNN看起来差别很大,但RBG大神说“Deformable Part Models are Convolutional Neural Networks”(http://arxiv.org/abs/1409.5403)。
CNN流行之后,Szegedy做过将detection问题作为回归问题的尝试(Deep Neural Networks for Object Detection),但是效果差强人意,在VOC2007上mAP只有30.5%。
既然回归方法效果不好,而CNN在分类问题上效果很好,那么为什么不把detection问题转化为分类问题呢?RBG的RCNN使用region proposal(具体用的是Selective Search Koen van de Sande: Segmentation as Selective Search for Object Recognition)来得到有可能得到是object的若干(大概10^3量级)图像局部区域,然后把这些区域分别输入到CNN中,得到区域的feature,再在feature上加上分类器,判断feature对应的区域是属于具体某类object还是背景。当然,RBG还用了区域对应的feature做了针对boundingbox的回归,用来修正预测的boundingbox的位置。RCNN在VOC2007上的mAP是58%左右。
RCNN存在着重复计算的问题(proposal的region有几千个,多数都是互相重叠,重叠部分会被多次重复提取feature),于是RBG借鉴Kaiming He的SPP-net的思路单枪匹马搞出了Fast-RCNN,跟RCNN最大区别就是Fast-RCNN将proposal的region映射到CNN的最后一层conv layer的feature map上,这样一张图片只需要提取一次feature,大大提高了速度,也由于流程的整合以及其他原因,在VOC2007上的mAP也提高到了68%。
探索是无止境的。Fast-RCNN的速度瓶颈在Region proposal上,于是RBG和Kaiming He一帮人将Region proposal也交给CNN来做,提出了Faster-RCNN。Fater-RCNN中的region proposal netwrok实质是一个Fast-RCNN,这个Fast-RCNN输入的region proposal的是固定的(把一张图片划分成n*n个区域,每个区域给出9个不同ratio和scale的proposal),输出的是对输入的固定proposal是属于背景还是前景的判断和对齐位置的修正(regression)。Region proposal network的输出再输入第二个Fast-RCNN做更精细的分类和Boundingbox的位置修正。Fater-RCNN速度更快了,而且用VGG net作为feature extractor时在VOC2007上mAP能到73%。
个人觉得制约RCNN框架内的方法精度提升的瓶颈是将dectection问题转化成了对图片局部区域的分类问题后,不能充分利用图片局部object在整个图片中的context信息。可能RBG也意识到了这一点,所以他最新的一篇文章YOLO(http://arxiv.org/abs/1506.02640)又回到了regression的方法下,这个方法效果很好,在VOC2007上mAP能到63.4%,而且速度非常快,能达到对视频的实时处理(油管视频:https://www.youtube.com/channel/UC7ev3hNVkx4DzZ3LO19oebg),虽然不如Fast-RCNN,但是比传统的实时方法精度提升了太多,而且我觉得还有提升空间。
感谢有RGB这样的牛人们不断推动detection的进步&期待YOLO代码的公布
泻药,终于看到符合自己胃口的问题啦!怒答一枚。RCNN和Fast-RCNN简直是引领了最近两年目标检测的潮流!
-------------------------------
提到这两个工作,不得不提到RBG大神rbg's home page,该大神在读博士的时候就因为dpm获得过pascal voc 的终身成就奖。博士后期间更是不断发力,RCNN和Fast-RCNN就是他的典型作品。
RCNN:RCNN可以看作是RegionProposal+CNN这一框架的开山之作,在imgenet/voc/mscoco上基本上所有top的方法都是这个框架,可见其影响之大。RCNN的主要缺点是重复计算,后来MSRA的kaiming组的SPPNET做了相应的加速。
Fast-RCNN:RCNN的加速版本,在我看来,这不仅仅是一个加速版本,其优点还包括:
(a) 首先,它提供了在caffe的框架下,如何定义自己的层/参数/结构的范例,这个范例的一个重要的应用是python layer的应用,我在这里支持多label的caffe,有比较好的实现吗? - 孔涛的回答也提到了。
(2) training and testing end-to-end 这一点很重要,为了达到这一点其定义了ROIPooling层,因为有了这个,使得训练效果提升不少。
(3) 速度上的提升,因为有了Fast-RCNN,这种基于CNN的 real-time 的目标检测方法看到了希望,在工程上的实践也有了可能,后续也出现了诸如Faster-RCNN/YOLO等相关工作。
这个领域的脉络是:RCNN -> SPPNET -> Fast-RCNN -> Faster-RCNN。关于具体的细节,建议题主还是阅读相关文献吧。
这使我看到了目标检测领域的希望。起码有这么一部分人,他们不仅仅是为了几个百分点的提升,而是切实踏实在做贡献,相信不久这个领域会有新的工作出来。
以上纯属个人观点,欢迎批评指正。
参考:
[1] R-CNN: Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C], CVPR, 2014.
[2] SPPNET: He K, Zhang X, Ren S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[C], ECCV, 2014.
[3] Fast-RCNN: Girshick R. Fast R-CNN[C]. ICCV, 2015.
[4] Fater-RCNN: Ren S, He K, Girshick R, et al. Faster r-cnn: Towards real-time object detection with region proposal networks[C]. NIPS, 2015.
[5] YOLO: Redmon J, Divvala S, Girshick R, et al. You Only Look Once: Unified, Real-Time Object Detection[J]. arXiv preprint arXiv:1506.02640, 2015.
是这样的,如果都用一句话来描述
RCNN 解决的是,“为什么不用CNN做classification呢?”
(但是这个方法相当于过一遍network出bounding box,再过另一个出label,原文写的很不“elegant”
Fast-RCNN 解决的是,“为什么不一起输出bounding box和label呢?”
(但是这个时候用selective search generate regional proposal的时间实在太长了
Faster-RCNN 解决的是,“为什么还要用selective search呢?”
于是就达到了real-time。开山之作确实是开山之作,但是也是顺应了“Deep learning 搞一切vision”这一潮流吧。作者:Oh233
链接:https://www.zhihu.com/question/35887527/answer/72884459
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
在个人知乎专栏里写了一个系列:
晓雷机器学习笔记
链接:https://www.zhihu.com/question/35887527/answer/140239982
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
<img src="https://pic4.zhimg.com/50/v2-0c98fb30a9e589fa164d99c50e6ca711_hd.jpg" data-rawwidth="1080" data-rawheight="623" class="origin_image zh-lightbox-thumb" width="1080" data-original="https://pic4.zhimg.com/v2-0c98fb30a9e589fa164d99c50e6ca711_r.jpg">
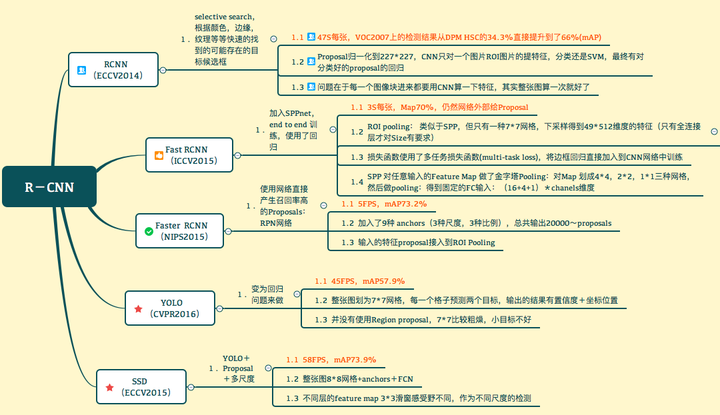
个人觉得,分析比较Faster Yolo SSD这几种算法,有一个问题要先回答,Yolo SSD为什么快?
最主要的原因还是提proposal(最后输出将全连接换成全卷积也是一点)。其实总结起来我认为有两种方式:1.RPN,2. 暴力划分。RPN的设计相当于是一个sliding window 对最后的特征图每一个位置都进行了估计,由此找出anchor上面不同变换的proposal,设计非常经典,代价就是sliding window的代价。相比较 yolo比较暴力 ,直接划为7*7的网格,估计以网格为中心两个位置也就是总共98个”proposal“。快的很明显,精度和格子的大小有关。SSD则是结合:不同layer输出的输出的不同尺度的 Feature Map提出来,划格子,多种尺度的格子,在格子上提“anchor”。结果显而易见。
还需要说明一个核心: 目前虽然已经有更多的RCNN,但是Faster RCNN当中的RPN仍然是一个经典的设计。下面来说一下RPN:(当然你也可以将YOLO和SSD看作是一种RPN的设计)
<img src="https://pic2.zhimg.com/50/v2-40a051c7fa7a6d73faf949a6d487019a_hd.jpg" data-rawwidth="840" data-rawheight="509" class="origin_image zh-lightbox-thumb" width="840" data-original="https://pic2.zhimg.com/v2-40a051c7fa7a6d73faf949a6d487019a_r.jpg">
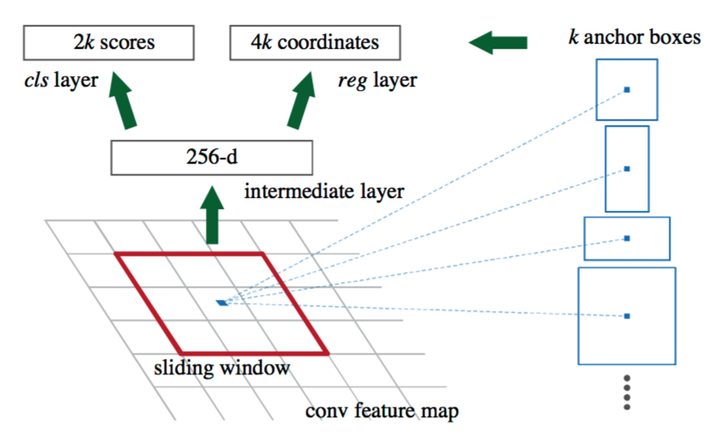
在Faster RCNN当中,一张大小为224*224的图片经过前面的5个卷积层,输出256张大小为13*13的 特征图(你也可以理解为一张13*13*256大小的特征图,256表示通道数)。接下来将其输入到RPN网络,输出可能存在目标的reign WHk个(其中WH是特征图的大小,k是anchor的个数)。
实际上, 这个RPN由两部分构成:一个卷积层,一对全连接层分别输出分类结果(cls layer)以及 坐标回归结果(reg layer)。卷积层:stride为1,卷积核大小为3*3,输出256张特征图(这一层实际参数为3*3*256*256)。相当于一个sliding window 探索输入特征图的每一个3*3的区域位置。当这个13*13*256特征图输入到RPN网络以后, 通过卷积层得到13*13个 256特征图。也就是169个256维的特征向量,每一个对应一个3*3的区域位置,每一个位置提供9个anchor。于是,对于每一个256维的特征,经过 一对 全连接网络(也可以是1*1的卷积核的卷积网络),一个输出 前景还是背景的输出2D;另一个输出回归的坐标信息(x,y,w, h,4*9D,但实际上是一个处理过的坐标位置)。于是,在这9个位置附近求到了一个真实的候选位置。