foreach及Enumeration接口
JDK1.5之后增加了许多新的功能,其中foreach可以输出数组,实际上foreach语法中同样也支持集合的输出操作
import java.util.ArrayList;
import java.util.List;
public class ForeachDemo01 {
public static void main(String[] args) {
List<String> all=new ArrayList<String>();
all.add("Hello");
all.add("_");
all.add("World");
for (String str: all) {
System.out.println(str+",");
}
}}
实际上Iterator属于一个新的输出接口,在最早Java刚出来的时候如果向要输出,使用Enumeration接口完成输出。但是在Java因为存在发展的历史问题,所以有些地方还会使用到Enumeration输出。而且必须注意的是在使用Enumeation的时候一般是直接操作Vector类完成的。
import java.util.ArrayList;
import java.util.Enumeration;
import java.util.List;
import java.util.Vector;
public class ForeachDemo02 {
public static void main(String[] args) {
Vector<String> vector=new Vector<String>();
vector.add("Hello");
vector.add("_");
vector.add("World");
Enumeration<String> enumeration=vector.elements();
while (enumeration.hasMoreElements()) {
System.out.println(enumeration.nextElement()+",");
}
}}
在所有的输出操作中,以Iterator接口为标准的输出操作,这一点始终记住。
在部分旧的操作中Enumeration依然存在。
Map接口
Map接口的常用子类:HashMap,Hashtable,TreeMap,WeekHashMap
之前所学的Collection,Set,List接口都属于单值操作,即每次只能操作一个对象,而Map与它们不同的是,每次操作的是一对对象,即二元偶对象,Map中的每个元素都使用Key->value的形式存储在集合之中。接口定义如下:public interface Map<K,V>
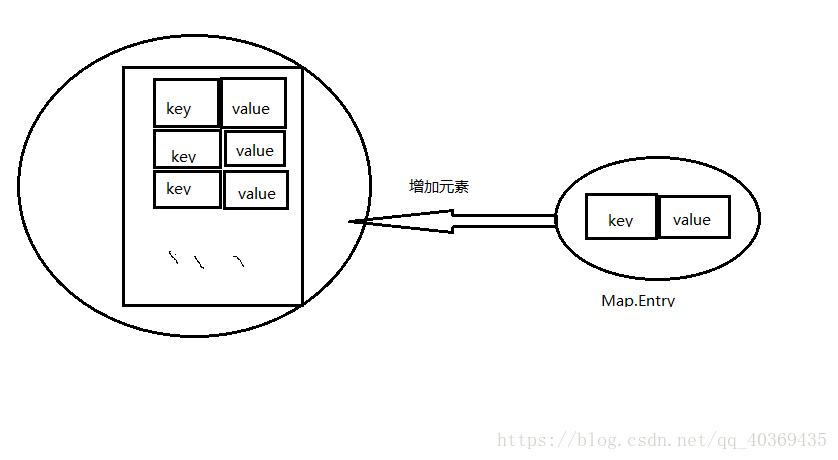
Map.Entry接口
Map.Entry是Map中内部定义的一个接口,专门用来存放key->value的内容
Map.Entry接口定义:public static interface Map.Entry<K,V>;
Map.Entry接口的常用方法:
public loolean equals(Object o) 对象比较
public K getKey() 取得Key
public V getValue() 取得value
public int hashCode() 返回哈希码
public V setValue(V value) 设置value的值
Map与Map.Entry的关系
Map接口的常用子类:
HashMap:无序存放,是新的操作类,key不允许重复
Hashtable:无序存放,是旧的操作类,Key不允许重复
TreeMap:是可以排序的Map集合,按集合中的Key排序,但是Key不允许重复
WeakHashMap:弱引用的Map集合,当集合中的某些内容不再使用时,可以清除掉无用的数据,九二幺使用gc进行回收
IdentityHashMap:key可以重复的Map集合
以HashMap为例的基本操作方法:
import java.util.HashMap;
import java.util.Map;
public class HashMapDemo01 {
public static void main(String[] args) {
Map<String, String> map=null;//声明Map对象,其中Key和value的类型为String
map=new HashMap<String, String>();
map.put("学号1", "张三");//增加内容
map.put("学号2", "李四");
map.put("学号3", "王五");
String val=map.get("学号1");//根据Key取出值
System.out.println("取出的值为"+val);
}
}
在map中也可以使用containsXXX()方法判断指定的key或者value是否存在
if(map.containsKey("学号1')){System.out.println("搜索的Key存在!")}//判断Key是否存在
else{System.out.println("搜索的Key不存在!")}
if(map.containsValue("学号1')){System.out.println("搜索的Value存在!")}//判断Value是否存在
else{System.out.println("搜索的Value不存在!")}
如果输出所有的key,使用如下方法:
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class HashMapDemo03 {
public static void main(String[] args) {
Map<String, String> map=null;//声明Map对象,其中Key和value的类型为String
map=new HashMap<String, String>();
map.put("学号1", "张三");//增加内容
map.put("学号2", "李四");
map.put("学号3", "王五");
Set<String> keys=map.keySet();//得到全部的key
Iterator<String> iterator=keys.iterator();
while(iterator.hasNext()){
String str=iterator.next();
System.out.print(str+",");
}
}
}
既然可以输出所有的Key,那么也可以输出全部的value
Collecation <String> iter=map.values();//得到全部的value
在Map中也存在一个Hashtable子类,实际上这个子类的推出时间与Vector一样,都属于旧的类
Map<String,String> map=null;
map=new Hashtable<String,String>();
其他的步骤跟HashMap没啥区别
HashMap与Hashtable的区别
HashMap Hashtable
性能 采用异步处理方式,性能更高 采用同步处理方式,性能较低
线程安全 属于非线程安全的操作类 属于线程安全的操作类
在Map中还存在一个TreeMap的子类,此类也属于排序类,按key排序。
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
import java.util.TreeMap;
public class TreeMapDemo01 {
public static void main(String[] args) {
Map<String, String> map=null;
map=new TreeMap<String, String>();
map.put("A","小明");
map.put("B", "小李");
map.put("C", "小王");
Set<String> keysSet=map.keySet();//得到所有的key
Iterator<String> iterator=keysSet.iterator();
while (iterator.hasNext()) {
String string=iterator.next();
System.out.println(string+">>>>"+map.get(string));//取出内容
}
}
}
使用TreeMap可以方便的完成排序的操作,如果自定义的类想要作为key的话,则肯定需要实现Comparable接口,指定比较规则。
如果假设一个Map中某些内容长时间不使用的话,按照之前的做法时不会删除掉的,如果希望其可以自动删除,可以说使用弱引用。当里面的某些内容不使用时,可以自动删除掉。
import java.util.Iterator;
import java.util.Map;
import java.util.WeakHashMap;
import java.util.Set;
import java.util.TreeMap;
public class WeakHashMapDemo01 {
public static void main(String[] args) {
Map<String, String> map=null;
map=new WeakHashMap<String, String>();
map.put(new String("A"),new String("小王"));
map.put(new String("B"),new String("小明"));
map.put(new String("C"),new String("小李"));
System.gc();//强制性进行垃圾的回收机制
System.out.println(map);
map.put(new String("D"),new String("小wang"));
System.out.println(map);
}
}
强引用:当内存不足时,JVM宁愿出现OutOfMemeryError错误而使程序停止,也不会回收此对象来释放空间;
软引用:当内存不足时,会回收这些对象的内存,用来实现内存敏感的高速缓存;
弱引用:无论内存是否紧张,被垃圾回收器发现,立即回收;
虚引用:和没有任何引用一样
小总结:
介绍了Map的特点及基本操作
Map和Map.Entry的关系
Map的子类:HashMap,Hashtable,TreeMap,WeakHashMap
主要功能就是查找,根据Key查找到value
Map接口的使用注意事项
Map接口输出: |
对于Map接口来说,其本身是不能迭代直接使用迭代(例如:Iterator,foreach)进行输出,因为Map中的每个位置存放的是一对值(key->value),而Iterator中每次只能找到一个值,所以如果此时非要进行迭代输出的话,则必须按照以下的步骤完成:
1:将Map的实例通过entrySet()方法变为Set接口对象;
2:通过Set接口实例为Iterator实例化
3:通过Iterator迭代输出,每个内容都是Map.Entry的对象
4:通过Map.Entry进行Key->value的分离
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class IteratorDemo4 {
public static void main(String[] args) {
Map<String, String> map=null;
map=new HashMap<String, String>();
map.put("学号1", "小明");
map.put("学号2", "小李");
map.put("学号3", "小王");
Set<Map.Entry<String, String>> allSet=null;
allSet=map.entrySet();//获得Map.Entry<String, String>集合
Iterator<Map.Entry<String, String>> iterator=null;//迭代器类型为Map.Entry<String, String>
iterator=allSet.iterator();
while (iterator.hasNext()) {
Map.Entry<String, String> meEntry=iterator.next();
System.out.println(meEntry.getKey()+"---->"+meEntry.getValue());//Map.Entry<String, String>提供了getKey()和getValue()的方法
}
}
}
第一种方式是通过Ierator完成,当然,在JDK1.5之后也可以使用foreach完成。 forach(Map.Entry<String,String> me: map.entrySet()){ System.out.println(meEntry.getKey()+"---->"+meEntry.getValue());//Map.Entry<String, String> } |
| 两种输出形式最终实际上还是以Collection的形式输出,只是以Map.Entry作为内容的操作类型 |
在Map中可以使用任意的类型作为Key和value,那么非系统类也可以。
| import java.util.HashMap; import java.util.Map; class Person{ private String name; private int age; public Person(String name,int age) { this.name=name; this.age=age; } public String toString(){ return "姓名: "+this.name+";年龄: "+this.age; } } public class HashMapDemo05 { public static void main(String[] args) { Map<String, Person> map=null; map=new HashMap<String, Person>(); map.put("zhangsan", new Person("张三", 30)); System.out.println(map.get("zhangsan")); } } |
如果现在以String为key是可以取出内容的,但如果以下:
map.put(new Person("张三", 30), "zhangsan"); System.out.println(map.get(new Person("张三", 30))); |
以自定的类作为Key,但无法取值,则结果为空!!!
实际上,对于匹配过程,对象要一样才能进行匹配查找
Person per=new Person("张三", 30); map.put(per, "zhangsan"); System.out.println(map.get(per)); 若上方能查找 但是这样并不是解决问题的方法,因为不可能将Person的对象per对象到处带着走,应该像String一样,可以使用匿名对象的形式找到内容 |
那么此时,实际上就需要按照与Set接口中判断重复元素的方式一样,进行方法重写:
| public boolean equals(Object object) { if (this==object) { return true; } if (!(object instanceof Person)) { return false; } Person person=(Person)object; if (this.name.equals(person.name)&&this.age==person.age){ return true; } else { return false; } } public int hashCode(){ return this.name.hashCode()*this.age; } |
总结:
Map可以使用迭代输出
map->entrySet->Set->Iterator->Map.Entry->key和value
如果使用非系统类作为key,则一点要在该类中重写equals()和hashCode()方法,否则无效。
IdentityHashMap类:
public static void main(String[] args) {
Map<Person00, String> map=null;
map=new HashMap<Person00, String>();//声明Map对象
map.put(new Person00("张三", 30), "zhangsan_1");
map.put(new Person00("张三", 31), "zhangsan_2");
map.put(new Person00("李四", 32), "lisi");
Set<Map.Entry<Person00, String>> allSet=null;
allSet=map.entrySet();
Iterator<Map.Entry<Person00, String>> iterator=allSet.iterator();//接受Set的全部内容
while (iterator.hasNext()) {
Map.Entry<Person00, String> mEntry=iterator.next();
System.out.println(mEntry.getKey()+"-->"+mEntry.getValue());
}
}
如果现在希望Key的内容可以重复,(两个对象的地址不一样)则要使用第二个子类
Map<Person00, String> map=null;
map=new IdentityHashMap<Person00, String>();//声明Map对象
就算是两个对象的内容相等,但是因为都使用了new关键字,所有地址肯定不等,那么就可以加进去,key是可以重复的
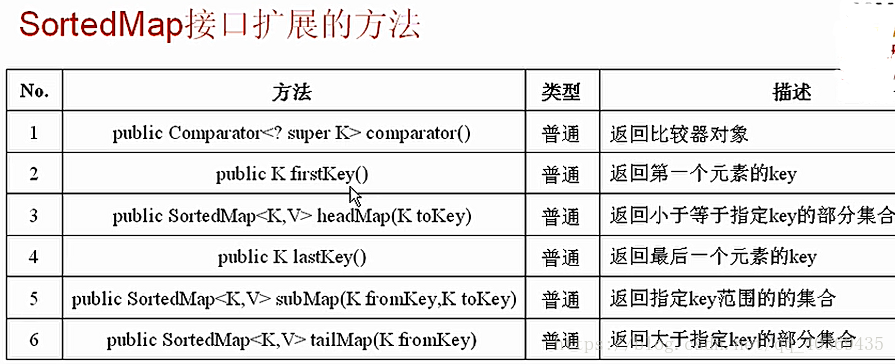
SortedMap类:
import java.util.SortedMap;
import java.util.TreeMap;
public class SortedMapDemo {
SortedMap<String, String> map=null;
map=new TreeMap<String, String>();
map.put("D", "小明");
map.put("B", "小李");
map.put("C", "小王");
map.put("A", "小六");
System.out.println("第一个元素的内容的key:"+map.firstKey());
System.out.println("对应的值:"+map.get(map.firstKey()));
System.out.println("最后一个元素的内容"+map.lastKey());
System.out.println(":对应的值:"+map.get(map.lastKey()));
System.out.println("返回小于指定范围的集合:");
for (Map.Entry<String, String> meEntry:map.headMap("B").entrySet()) {
System.out.println(meEntry.getKey()+"-->"+meEntry.getValue());
}
System.out.println("部分集合:");
for (Map.Entry<String, String> meEntry:map.subMap("B","D").entrySet()) {
System.out.println(meEntry.getKey()+"-->"+meEntry.getValue());
}
}
}
Collections类:
Set<String>allSet=Collections.emptySet();
allList.add("Hello");
Stack类:
方法: 1. public push (item ) 把项 压入栈顶。其作用与 addElement (item ) 相同。
参数 item 压入栈顶的项 。 返回: item 参数 ;
2. public pop () 移除栈顶对象,并作为函数的值 返回该对象。
返回:栈顶对象(Vector 对象的中的最后一项)。
抛出异常 : EmptyStackException 如果堆栈式空的 。。。
3. public peek() 查看栈顶对象而不移除它。。
返回:栈顶对象(Vector 对象的中的最后一项)。
抛出异常 : EmptyStackException 如果堆栈式空的 。。。
4. public boolean empty (测试堆栈是否为空。) 当且仅当堆栈中不含任何项时 返回 true,否则 返回 false.
5. public int search (object o) 返回对象在堆栈中位置, 以 1 为基数, 如果对象 o是栈中的一项,该方法返回距离 栈顶最近的出现位置到栈顶的距离; 栈中最上端项的距离
Stack stack =
new
Stack();
// 创建堆栈对象
System.out.println(
"11111, absdder, 29999.3 三个元素入栈"
);
stack.push(
new
Integer(
11111
));
//向 栈中 压入整数 11111
printStack(stack);
//显示栈中的所有元素
stack.push(
"absdder"
);
//向 栈中 压入
printStack(stack);
//显示栈中的所有元素
stack.push(
new
Double(
29999.3
));
//向 栈中 压入
printStack(stack);
//显示栈中的所有元素
String s =
new
String(
"absdder"
);
System.out.println(
"元素absdder在堆栈的位置"
+stack.search(s));
System.out.println(
"元素11111在堆栈的位置"
+stack.search(
11111
));
System.out.println(
"11111, absdder, 29999.3 三个元素出栈"
);
//弹出 栈顶元素
System.out.println(
"元素"
+stack.pop()+
"出栈"
);
printStack(stack);
//显示栈中的所有元素
System.out.println(
"元素"
+stack.pop()+
"出栈"
);
printStack(stack);
//显示栈中的所有元素
System.out.println(
"元素"
+stack.pop()+
"出栈"
);
printStack(stack);
//显示栈中的所有元素
Properties类集:
在类集属性中提供了专门的Properties类以完成属性的操作。
public class Properties extends Hashtable(Object,Object)
proties是Hashtable的子类,则也是Map的子类,可以使用Map的全部操作,但是一般情况下属性类是单独使用的。
设置属性:public Object setProperty(String Key,String key)
得到属性:public String getProperty(String key)
public String getProperty(String key,String defaultValue)
以下为设置和读取属性
import java.io.FileOutputStream;
import java.util.Properties;
public class PropertiesDemo {
Properties per=new Properties();//设置Properties对象
per.setProperty("BJ", "beijing");//设置属性
per.setProperty("TJ", "tianjing");
per.setProperty("SH", "shanghai");
System.out.println("BJ属性存在:"+per.getProperty("BJ"));
}
}
以下将属性保存到问价之中,提供了这个方法:public void store(OutputStream out,String comments)throws IOException
import java.io.FileOutputStream;
import java.util.Properties;
public class PropertiesDemo {
Properties per=new Properties();//设置Properties对象
per.setProperty("BJ", "beijing");//设置属性
per.setProperty("TJ", "tianjing");
per.setProperty("SH", "shanghai");
File file=new File("D:"+File.separator+"area.properteis");//指定要操作的文件
try {
per.store(new FileOutputStream(file),"Area Info");//保存属性到普通文件
} catch (Exception e) {
// TODO: handle exception
}
}
}
那么也可以读取文件:
import java.io.FileInputStream;
import java.util.Properties;
public class PropertiesDemo02 {
Properties per=new Properties();//设置Properties对象
per.setProperty("BJ", "beijing");//设置属性
per.setProperty("TJ", "tianjing");
per.setProperty("SH", "shanghai");
File file=new File("D:"+File.separator+"area.properteis");//指定要操作的文件
try {
per.load(new FileInputStream(file));//读取文件
} catch (Exception e) {
// TODO: handle exception
}
System.out.print("BJ属性存在"+per.getProperty("BJ"));
}
}
也可以存在XML文件之中
File file=new File("D:"+File.separator+"area.xml");//指定要操作的文件
也可以读取XML文件:
per.loadFromXML(new FileInputStream(file));//读取属性文件
属性可以向普通文件或者XML文件保存或读取,按照指定格式可以向文件中扩充属性。
心态真的是被IE浏览器玩崩,一下午写的东西被IE浏览器卡顿的一下就全没了,以后些东西都再也不用IE浏览器了!!!!!!!!!
!!! 2018.07.13