链接如下: https://www.cnblogs.com/alwayswangzi/p/7138154.html
1、为什么要使用线程池:
(1)进程的创建和销毁都伴随着大量的系统开销,如果并发的线程数量很多(例如数百万高并发的处理),并且每个线程都是执行一个时间很短的任务就结束了,这样频繁创建和销毁线程需要消耗很大比重的时间。那么有没有一种办法使得线程可以重复使用,也就是说执行完一个任务后并不被销毁,而是可以继续执行其他的任务?线程池可以用来缓存线程,可用已有的闲置线程来执行新的任务,避免线程频繁创建和销毁所带来的系统开销。此外,一个理想的线程池能够合理地动态调节池内线程数量,既不会因为线程过少而导致大量任务堆积,也不会因为线程过多了而增加额外的系统开销。
(2)运用线程池控制线程并发数,避免因并发数过多抢占系统资源而引起阻塞。
(3)对线程进行一些简单的管理如延迟执行、定时循环执行等。
2、线程池的基本原理:
其实线程池的原理非常简单:它就是一个非常典型的生产者消费者同步问题。根据刚才描述的线程池的功能,可以看出线程池的实现至少包括两个主要动作:(1)一个是主程序不断地向线程池(任务队列)添加任务。(2)另一个是线程池里的线程领取任务去执行。不论执行的是什么概念的任务,可以保证的一点是一个任务肯定只能分配给一个线程执行。这样就可以简单猜想线程池的一种可能的架构了:主程序执行入队操作,把任务添加到一个队列里面;池子里的多个工作线程共同对这个队列试图执行出队操作,这里要保证同一时刻只有一个线程出队成功,抢夺到这个任务,其他线程继续共同试图出队抢夺下一个任务。所以在实现线程池之前,我们需要一个队列。这里的生产者就是主程序,生产任务(增加任务),消费者就是工作线程,消费任务(执行、减少任务)。因为这里涉及到多个线程同时访问一个队列的问题,所以我们需要互斥锁来保护队列,同时还需要条件变量来处理主线程通知任务到达、工作线程抢夺任务的问题。
一般来说实现一个线程池主要包括以下4个组成部分:
- 线程管理器:用于创建并管理线程池。
- 工作线程:线程池中实际执行任务的线程。在初始化线程时会预先创建好固定数目的线程在池中,这些初始化的线程一般处于空闲状态。
- 任务接口:每个任务必须实现的接口。当线程池的任务队列中有可执行任务时,被空间的工作线程调去执行(线程的闲与忙的状态是通过互斥量实现的),把任务抽象出来形成一个接口,可以做到线程池与具体的任务无关。
- 任务队列:用来存放没有处理的任务。提供一种缓冲机制。实现这种结构有很多方法,常用的有队列和链表结构。
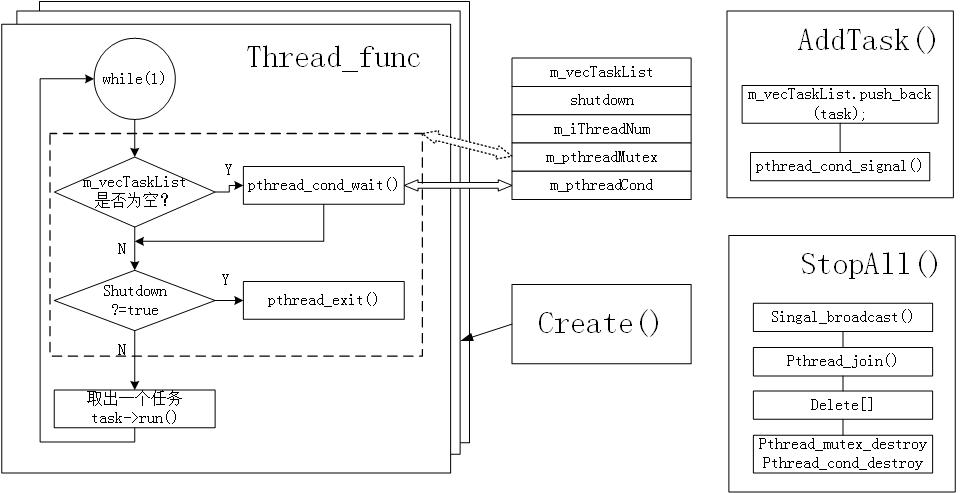
流程图如下:
#ifndef THREADPOOL_H
#define THREADPOOL_H
#include <list>
#include <cstdio>
#include <exception>
#include <pthread.h>\
/*第14章的线程同步机制的包装类*/
#include "locker.h"
/*线程池,将其定义为模板是为了更好的复用。参数模板T是任务类*/
template< typename T >
class threadpool
{
public:
threadpool( int thread_number = 8, int max_requests = 10000 );
~threadpool();
/*往请求队列中添加任务*/
bool append( T* request );
private:
/*工作线程运行的函数,它不断的从工作队列取任务并执行*/
static void* worker( void* arg );
/*启动线程池*/
void run();
private:
int m_thread_number;/*线程池中的线程数*/
int m_max_requests;/*请求队列中允许的最大请求数*/
pthread_t* m_threads;/*描述线程池的数组,其大小为m_thread_number*/
std::list< T* > m_workqueue;/*请求队列*/
locker m_queuelocker;/*保护请求队列的互斥锁*/
sem m_queuestat;/*是否有任务需要处理*/
bool m_stop;/*是否结束线程*/
};
/*线程池的构造函数*/
template< typename T >
threadpool< T >::threadpool( int thread_number, int max_requests ) :
m_thread_number( thread_number ), m_max_requests( max_requests ), m_stop( false ), m_threads( NULL )
{
if( ( thread_number <= 0 ) || ( max_requests <= 0 ) )
{
throw std::exception();
}
/*工作线程组*/
/*---------------------------------------
typedef unsigned long int pthread_t;用于声明线程ID。
此处就是建立一个unlong int数组的意思,每个元素都是线程的索引即线程ID。
----------------------------------------*/
m_threads = new pthread_t[ m_thread_number ];/*所有的线程都放到这个大小固定的数组里面*/
if( ! m_threads )//如果建立失败
{
throw std::exception();
}
//系统调用pthread_create来建立thread_number个线程,并将他们都设置为脱离线程。
//线程ID放线程组数组、线程运行函数worker。
for ( int i = 0; i < thread_number; ++i )
{
printf( "create the %dth thread\n", i );
if( pthread_create( m_threads + i, NULL, worker, this ) != 0 )
{
delete [] m_threads;
throw std::exception();
}
/*
pthread_detach()即主线程与子线程分离,子线程结束后,资源自动回收。
pthread_join()即是子线程合入主线程,主线程阻塞等待子线程结束,然后回收子线程资源。
为了避免存储器泄漏,每个可结合线程都应该要么被显示地回收,即调用pthread_join;要么通过调用pthread_detach函数被分离。
*/
if( pthread_detach( m_threads[i] ) )//成功返回0,否则出错。
{
delete [] m_threads;
throw std::exception();
}
}
}
/*析构函数,主要就是西沟那个线程组数组即可*/
template< typename T >
threadpool< T >::~threadpool()
{
delete [] m_threads;
m_stop = true;
}
/*往请求队列添加任务*/
template< typename T >
bool threadpool< T >::append( T* request )
{
/*--------------------------------------------------
操作工作队列的时候一定要加锁,因为它被所有线程共享
--------------------------------------------------*/
m_queuelocker.lock();//加锁
if ( m_workqueue.size() > m_max_requests ){
m_queuelocker.unlock();
return false;
}
m_workqueue.push_back( request );//将请求加入队列
m_queuelocker.unlock();//解锁
m_queuestat.post();//以原子操作的方式将信号量加1
return true;
}
/*工作线程运行的函数,它不断的从工作队列取任务并执行*/
//void*有指向的指针 ,只不过暂时指向什么还不确定。
template< typename T >
void* threadpool< T >::worker( void* arg )
{
threadpool* pool = ( threadpool* )arg;
pool->run();
return pool;
}
template< typename T >
void threadpool< T >::run()
{
while ( ! m_stop ){
m_queuestat.wait();//以原子操作的方式将信号量减1
/*---------操作工作队列一定要加锁--------*/
m_queuelocker.lock();//加锁
if ( m_workqueue.empty() )
{
m_queuelocker.unlock();
continue;
}
/*-----------如果队列中还有请求,就把他取出来------------*/
T* request = m_workqueue.front();
m_workqueue.pop_front();
m_queuelocker.unlock();//取完队列后解锁。
if ( ! request )
{
continue;
}
/*-----------------------------此处就是处理这个请求------------------------------------*/
request->process();
}
}
#endif
《Linux高性能服务器编程》里面的threadpoll就是基于这个思想实现的。源代码如上。但是一直被被的线程池中的线程在抢不到任务的时候都干啥去了呢?所谓的空闲的线程被阻塞、不占用CPU并没有看到这样的实现呀!网上看了很多帖子,有的讲道理的时候这样讲但是所给的代码并没有对空闲线程阻塞进行阻塞处理呀!不靠谱,,,。
3、线程池的三个实现程度:
根据实现程度可以分为三个层次:
(1)实现基本功能。即:主程序执行入队操作把任务添加到任务队列,池子里的多个工作线程共同对这个队列试图执行出队操作。这里仅需要保证每次只有一个线程抢夺到这个任务,其他线程继续共同试图出队抢夺下一个任务。
(2)具备上述功能的同时,保证线程空闲时处于阻塞状态不消耗CPU,仅占用很少内存空间。
(3)在具备上述两点同时,具备线程池线程数量大小的动态调整。
(2)(3)两点一个连贯的描述是:线程池采用预创建的技术,在应用程序启动之后,将立即创建一定数量的线程(N1),放入空闲队列中。这些线程都是处于阻塞(Suspended)状态,不消耗CPU,但占用较小的内存空间。当任务到来后,缓冲池选择一个空闲线程,把任务传入此线程中运行。当N1个线程都在处理任务后,缓冲池自动创建一定数量的新线程,用于处理更多的任务。在任务执行完毕后线程也不退出,而是继续保持在池中等待下一次的任务。当系统比较空闲时,大部分线程都一直处于暂停状态,线程池自动销毁一部分线程,回收系统资源。基于这种预创建技术,线程池将线程创建和销毁本身所带来的开销分摊到了各个具体的任务上,执行次数越多,每个任务所分担到的线程本身开销则越小,不过我们另外可能需要考虑进去线程之间同步所带来的开销。
层次一的代码如前文所示;
层次二的代码参加 https://www.cnblogs.com/yangang92/p/5485868.html。
层次三的代码有空在找找尝试实现。
4、线程池的适用场合:
线程池不是万能的,它有其特定的使用场合。线程池致力于减少线程本身的开销对应用所产生的影响是有前提的。前提就是线程本身开销与线程执行任务相比不可忽略。如果线程本身的开销相对于线程任务执行开销而言是可以忽略不计的,那么此时线程池所带来的好处是不明显的,比如对于FTP服务器以及Telnet服务器,通常传送文件的时间较长,开销较大,那么此时,我们采用线程池未必是理想的方法,我们可以选择“即时创建,即时销毁”的策略。
总之线程池通常适合下面的几个场合:
(1) 单位时间内处理任务频繁而且任务处理时间短
(2) 对实时性要求较高。如果接受到任务后在创建线程,可能满足不了实时要求,因
此必须采用线程池进行预创建。
(3) 必须经常面对高突发性事件,比如Web服务器,如果有足球转播,则服务器将产生
巨大的冲击。此时如果采取传统方法,则必须不停的大量产生线程,销毁线程。此时
采用动态线程池可以避免这种情况的发生。