参考:
http://blog.didispace.com/springcloud5/
http://blog.didispace.com/springcloud7-2/
4 消息总线
在前面的配置中心篇中讲到过,可以通过消息总线刷新配置的更新。Spring Cloud Bus除了支持RabbitMQ的自动化配置之外,还支持现在被广泛应用的Kafka。下面将通过Kafka实现消息总线的功能。
4.1 Kafka简介
Kafka是一个由LinkedIn开发的分布式消息系统,于2011年初开源,现由Apache维护和开发。Kafka使用Scala实现,被用作LinedIn的活动流和运营数据处理的管道,现在也被诸多互联网企业广泛地用作为数据流管道和消息系统。
Kafka是基于消息发布/订阅模式实现的消息系统,其主要设计目标如下:
消息持久化:以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间复杂度的访问性能。
高吞吐:在廉价的商用机器上也能支持单机每秒100K条以上的吞吐量。
分布式:支持消息分区以及分布式消费,并保证分区内的消息顺序。
跨平台:支持不同技术平台的客户端。
实时性:支持实时数据处理和离散数据处理。
伸缩性:支持水平扩展。
Kafka中的一些基本概念:
Broker:Kfaka集群包含一个或多个服务器,这些服务器被称为Broker。
Topic:逻辑上同Rabbit的Queue队列相似,每条发布到Kfaka集群的消息都必须有一个主题。
Partition:Partition是物理概念上的分区,为了提供系统吞吐率,在物理上每个主题会分成一个或多个Partition,每个Partition对应一个文件夹(存储对应分区的消息内容和索引文件)。
Producer:消息生产者,负责生产消息并发送到Kafka Broker。
Consumer:消息消费者,向Kafka Broker读取消息并处理的客户端。
Consumer Group:每个消费者属于一个特定的组(可为每个消费者指定一个组,如不指定则属于默认组),组可以用来实现一条消息被组内多个成员消费等功能。
4.2环境安装
从官网下载kafka。地址为:http://kafka.apache.org/downloads.html。此处下载的是版本号为2.12-0.11.0.1,后缀为tgz的binary版本(windows下第一次解压成tar文件,需要再次解压)。解压到本地目录,注意目录中不能有空格,否则后面的命令会执行不了。解压好之后,bin/windows下会有windows环境的脚本。Kafka中自带zookeeper,这里就用自带的zookeeper来作分布式协调框架,建立起生产者和消费者的订阅关系并实现负载均衡。当然实际项目中肯定要用独立的zookeeper集群。下面依次启动zookeeper和kafka。
启动zookeeper
修改zookeeper.properties,自定义dataDir目录。
进入kafka根目录,执行
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties最终显示binding to port 0.0.0.0/0.0.0.0:2181(xxx)表示启动完毕。
启动kafka
修改server.properties,将listeners=PLAINTEXT://:9092改为listeners=PLAINTEXT://0.0.0.0:9092,将log.dirs改为你自己的自定义目录,zookeeper.connect改为127.0.0.1:2181(保持localhost的话需要在hosts文件中映射到127.0.0.1),将zookeeper.connection.timeout.ms改大一点,入60000。
进入kafka根目录,执行
.\bin\windows\kafka-server-start.bat .\config\server.properties如果启动时报无法连接到127.0.0.1,修改zookeeper.properties中maxClientCnxns的值(这个值表示单个客户端与单台服务器之间的最大连接数),0表示无限制,但这里不能为0(原因暂不清楚)。然后重新启动zookeeper和kafka。
创建主题
进入bin的windows目录,执行命令:
kafka-topics --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test通过该命令,创建一个名为“test”的Topic,该Topic包含一个分区一个Replica。在创建完成后,可以使用kafka-topics –list –zookeeper localhost:2181命令来查看当前的Topic。如果不使用kafka-topics命令来手工创建,直接进行下面的内容进行消息创建时也会自动创建Topics来使用。
创建消息生产者
进入bin的windows目录
kafka-console-producer --broker-list localhost:9092 --topic test在生产者窗口输入要发送的消息。
创建消息消费者
进入bin的windows目录,执行命令:
kafka-console-consumer --zookeeper localhost:2181 --topic test --from-beginning在消费者窗口就能看到生产者产生的消息了。
4.3 整合Spring Cloud Bus
在配置中心篇中引入rabbitMQ作消息总线时,需要引入spring-cloud-starter-bus-amqp模块,这里需要替换成spring-cloud-starter-bus-kafka:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bus-kafka</artifactId>
</dependency>将配置中心(上篇架构优化中也引入了消息总线)及两个客户端的pom.xml中引入的rabbitMQ模块都替换成kafka。依次启动服务注册中心,配置中心,两个配置中心客户端,修改git仓库中配置文件的参数值。
访问http://localhost:7003/from,发现无法获取最新的值,发送post请求http://localhost:7001/bus/refresh。再次访问http://localhost:7003/from和http://localhost:7002/from,发现获取到了最新值。通过kafka-topics –list –zookeeper localhost:2181命令也可以看到,当前kafka的主题中多了一个主题springCloudBus。
使用kafka作消息总线的原理和rabbitMQ是一样的,向其中一个客户端发送更新消息后,该更新请求被发送到消息总线上,消息总线的RefreshListener监听器收到了刷新请求后就去配置中心获取最新的配置信息。
4.4 Kafka配置
由于Kafka,Zookeeper均运行于本地,所以并没有在测试程序中通过配置信息来指定Kafka和Zookeeper的配置信息。在实际应用中,Kafka和Zookeeper一般独立部署,所以在应用中都需要为Kafka和Zookeeoer配置连接信息。Kafka的整合与RabbitMQ不同,在Spring Boot 1.3.7中并没有直接提供Starter模块,而是采用了Spring Cloud Stream的Kafka模块,所以对于Kafka的配置均采用了Spring.cloud.stream.kafka的前缀。
spring.cloud.stream.kafka.binder.brokers,表示Kafka的服务端列表,默认值为localhost。
spring.cloud.stream.kafka.binder.defaultBrokerPort ,为Kafka服务端默认端口,当brokers属性中没有配置端口信息时,使用默认值9092。
spring.cloud.stream.kafka.binder.zkNodes,为Kafka服务端连接的ZooKeeper节点列表,默认为localhost。
spring.cloud.stream.kafka.binder.defaultZkPort,ZK节点的端口,默认为2181端口。
5 服务网关
前面讲了几个核心组件,Spring Cloud Eureka服务注册与发现,Spring Cloud Config配置中心,Spring Cloud Hystrix断路器以及Ribbon/Feign负载均衡。
在微服务架构中,通过Eureka实现了服务注册中心以及服务注册与发现,服务间通过Ribbon或Feign实现服务的消费以及均衡负载,通过配置中心实现了应用多环境的外部化配置以及版本管理。为了使得服务集群更为健壮,使用Hystrix的熔断机制来避免在微服务架构中个别服务出现异常时引起故障蔓延。
通过这几个组件,基本可以构建一个简略的微服务架构了,如下图所示:
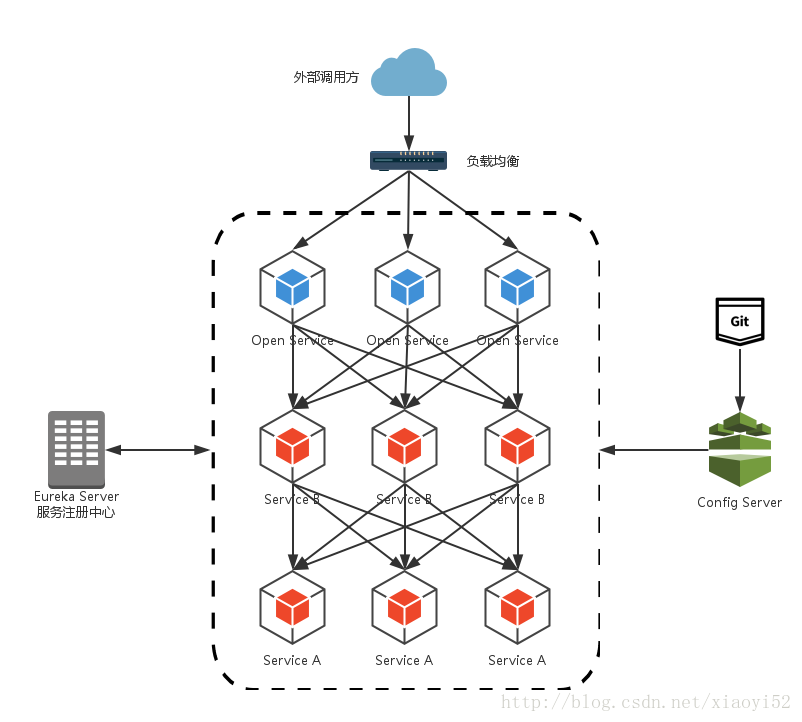
在该架构中,Open Service提供对外的服务,通过负载均衡公开至服务调用方。
该架构的不足:
(1) 提供给外部的服务为了保证安全性,需要做访问权限控制,而开放服务的权限控制机制将会污染整个开放服务的业务逻辑。带来的最直接的问题是,破坏了服务集群中REST API无状态的特点。从具体的开发和测试的角度讲,在工作中除了要考虑实际的业务逻辑之外,还需要额外考虑对接口访问的控制处理。
(2) 无法直接复用既有接口。当需要对一个既有的集群内部访问接口,实现外部服务访问时,不得不通过在原有接口上增加校验逻辑,或增加一个代理调用来实现权限控制,无法直接服用原有的接口。
为了解决上述问题,需要将权限控制这样的东西从服务单元中抽离出去,而最适合这些逻辑的地方就是处于对外访问最前端的地方:负载均衡。因此需要一个更强大的均衡负载器,这就是:服务网关。
服务网关是微服务架构中一个不可或缺的部分。通过服务网关统一向外系统提供REST API的过程中,除了具备服务路由、负载均衡功能之外,它还具备了权限控制等功能,使得服务集群主体具备更高的可复用性和可测试性。
5.1 Zuul配置
新建一个maven工程mysc-gateway。引入依赖模块:
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.3.5.RELEASE</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zuul</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-eureka</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Brixton.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>在主类中开启@EnableZuulProxy注解:
@EnableZuulProxy
@SpringCloudApplication
public class ZuulApplication {
public static void main(String[] args) {
new SpringApplicationBuilder(ZuulApplication.class).web(true).run(args);
}
}说明一下,@SpringCloudApplication注解整合了@SpringBootApplication,@EnableDiscoveryClient,@EnableCircuitBreaker,就像@RestController整合了@Controller和@ResponseBody一样,目的是为了简化配置。
application.properties中配置应用名和端口信息(注意浏览器对端口的限制,比如chrome中,很多端口如6666-6669是不能用的):
spring.application.name=api-gateway
server.port=8888此时Zuul已经可以运行,但是要发挥服务网关的作用,还需要进行配置。
通过服务路由的功能,在对外提供服务的时候,只需要通过暴露Zuul中配置的调用地址就可以让调用方统一来访问服务,而不需要了解具体提供服务的主机信息。那么Zuul作为外部调用的入口,怎么将外部调用与服务对应起来呢?Zuul提供了两种映射方式。
一是通过url直接映射。如下配置:
# routes to url
zuul.routes.api-a-url.path=/api-a-url/**
zuul.routes.api-a-url.url=http://localhost:2222/该配置,定义了所有到Zuul的中规则为:/api-a-url/**的访问都映射到http://localhost:2222/上,也就是说当我们访问http://localhost:8888/api-a-url/add?a=1&b=2的时候,Zuul会将该请求路由到:http://localhost:2222/add?a=1&b=2上。
其中,配置属性zuul.routes.api-a-url.path中的api-a-url部分为路由的名字,可以任意定义,但是一组映射关系的path和url中的这个路由名字要保持一致。
通过url直接映射的方式需要配置提供服务的主机信息,这并不符合微服务架构中服务自动注册和发现的机制。在微服务架构中,服务名与服务实例地址的关系在eureka server中已经存在了,所以只需要将zuul注册到eureka server上去发现其他读物,就可以实现对serviceId的映射。如下配置:
zuul.routes.api.path=/api/**
zuul.routes.api.serviceId=compute-service
eureka.client.serviceUrl.defaultZone=http://localhost:1111/eureka/在前文(SpringCloud基础(1)创建服务提供者方和创建服务消费者部分)中创建过两个服务提供者,提供的服务相同,服务接口为add,服务名为compute-service,端口分别为2222和2223。因此通过这里的配置不难判断,对localhost:8888/api/add?a=2&b=1的访问会映射到compute-service服务实例的add接口上去。同时zuul也有负载均衡的作用,两个服务提供者会被轮流调用。启动服务注册中心和服务提供者,以及服务网关,访问localhost:8888/api/add?a=2&b=1,可以看到调用结果。
5.2 服务过滤
在完成了服务路由之后,对外开放服务还需要一些安全措施来保护客户端只能访问它应该访问到的资源,需要利用Zuul的过滤器来实现对外服务的安全控制。
在服务网关中定义过滤器只需要继承ZuulFilter抽象类实现其定义的四个抽象函数就可对请求进行拦截与过滤。
下面的例子中定义了一个Zuul过滤器,实现了在请求被路由之前检查请求中是否有accessToken参数,若有就进行路由,若没有就拒绝访问,返回401 Unauthorized错误。
服务网关过滤器:
public class AccessFilter extends ZuulFilter {
private static Logger log = LoggerFactory.getLogger(AccessFilter.class);
@Override
public String filterType() {
return "pre";
}
@Override
public int filterOrder() {
return 0;
}
@Override
public boolean shouldFilter() {
return true;
}
@Override
public Object run() {
RequestContext ctx = RequestContext.getCurrentContext();
HttpServletRequest request = ctx.getRequest();
log.info(String.format("%s request to %s", request.getMethod(), request.getRequestURL().toString()));
Object accessToken = request.getParameter("accessToken");
if(accessToken == null) {
log.warn("access token is empty");
ctx.setSendZuulResponse(false);
ctx.setResponseStatusCode(401);
return null;
}
log.info("access token ok");
return null;
}
}自定义过滤器的实现继承ZuulFilter,需要重写实现下面四个方法:
filterType返回一个字符串代表过滤器类型,在zuul中定义了四种不同生命周期的过滤器类型,具体如下。
Pre:可以在请求被路由之前调用
Route:在路由请求时候被调用
Post:在route和error过滤器之后被调用
Error:处理请求发生错误时被调用
filterOrder返回一个boolean类型来判断该过滤器是否要执行,所以通过此函数可实现过滤器开关。
run过滤器的具体逻辑。通过ctx.setSendZuulResponse(false)令zuul过滤该请求,不对其进行路由,然后通过ctx.setResponseStatusCode(401)设置了其返回的错误码。事实上还可以通过ctx.setResponseBody(body)等方法对返回内容进一步进行编辑。
实现过滤器之后还需要让过滤器生效,在应用主类中增加:
@Bean
public AccessFilter accessFilter() {
return new AccessFilter();
}启动该服务网关后,访问:
http://localhost:8888/api/add?a=1&b=2:返回401错误
http://localhost:8888/api/add?a=1&b=2&accessToken=token:正确路由到compute-service,并返回计算内容。
服务网关是微服务架构的重要部分,主要体现在:
不仅仅实现了路由功能来屏蔽诸多服务细节,更实现了服务级别、均衡负载的路由。
实现了接口权限校验与微服务业务逻辑的解耦。通过服务网关中的过滤性,在各生命周期中去校验请求的内容,将原本在对外服务层作的校验前移,保证了微服务的无状态性,同时降低了微服务的测试难度,让服务本身更集中关注业务逻辑的处理。
实现了断路器,不会因为具体微服务的故障而导致服务网关的阻塞,依然可以对外服务。
代码地址:https://github.com/howetong/mysc
版本升级:将所有pom.xml中的parent依赖模块版本改为1.5.4.RELEASE,且将spring cloud版本改为Dalston.SR1。