深度学习之TensorFlow安装与初体验
学习前
搞懂一些关系和概念
首先,搞清楚一个关系:深度学习的前身是人工神经网络,深度学习只是人工智能的一种,深层次的神经网络结构就是深度学习的模型,浅层次的神经网络结构是浅度学习的模型。
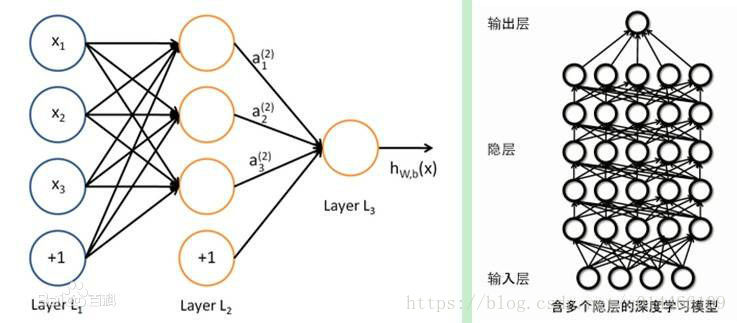
浅度学习:层数少于3层,使用全连接的一般被认为是浅度神经网络,也就是浅度学习的模型,全连接的可能性过于繁多,如果层数超过三层,计算量呈现指数级增长,计算机无法计算到结果,所以产生了深度学习概念
深度学习:层数可以有很多层,但是并不是全连接的传递参数,如上图中右边是一个7层的神经网络模型,其中隐藏层就是所谓的“学习”过程,我们所说的深度也是指隐藏层的深度。图中的有一处容易使人误解,右侧深度神经网络看上去是全连接的,但实际学习过程只采用部分的神经元,并非每一个神经元都互相连接的。如果深度+全连接的话,当前计算机还做不到那么庞大的计算量,模型是不切实际的。
最后,关于人工智能的一个经典评测标准:图灵测试,概括下来,在测试者不知道对面为机器还是人的情况下,向对方发问 ,如果机器的回答超过30%被误以为是人类回答的话,那么就说机器是智能的。
什么是人工神经网络,为什么要用他?
首先神经网络使用的是仿生学,人工神经网络的初衷和目的就是使得计算机像人脑一样“思考”,那硬件和软件的开发就应该仿照人类大脑来做,生物学,计算机学大佬们就想到了给机器按上一个神经元网络,但由于人类本身还没把自己的大脑搞个明白,所以人工智能尚处于一个半吊子状态,他只有人类一部分的智商而已。就目前而言,计算机远远赶不上人类思考的能力,而人类彻底研究明白大脑的那一天就是人工智能真正超越人类的一天(可怕哟)。
区别:
人类的神经网络系统:从出生那一天,神经元就已经存在了,只是连接的方式及其简单,稀疏而已,当你睁开眼睛的那一刻,你看到的爸爸,妈妈的脸,视觉系统就会触发大脑的部分神经元开始连接,这个连接简而言之就是,脸->爸妈(当然实际情况传输层次更多更复杂),以后当你再看到爸妈的脸,就会顺着这条已存在的连接传递(中间也是多层的),一下就认出了爸爸妈妈。
机器的神经网络系统:同样是人脸识别来看,机器先读取人脸,然后转换为二进制文件,将数据交给输入层,输入层传输到隐藏层,这时候会选择第一层部分的神经元,进行激活,神经元会根据给定的特征做一些参数调整,每一个神经元又选择下一层的几个神经元把自己处理好的数据传给他们,以此类推,直到输出层,给出一个“答案”,使用优化函数(如梯度下降算法)对比实际值的差距,比如把爸爸认成了妈妈,产生了这种差距后神经网络就要做一个重要的事情——反向传递,这是人类神经元所不需要的工作,将误差信息原路返回,修改刚刚路过的神经元,调整一些参数(权重),然后反反复复上述所有操作,最后得到接近正确答案的模型,算是学习结束,这时候再输入其他新数值一下就能得出结果了。这就是学习的过程!
结合上面两点来看,这就是为什么人只要看见一次就能记住的脸所对应的人,而机器只要发现脸变胖了,变黑了,就需要反向传递修改一些参数,记住胖脸和黑脸也是这个人,人识别人脸只需要部分特征数据即可,机器识别人脸则需要大量的特征数据。
最后需要知道一点是:机器学习的识别能力是来自大概率事件,只能做到某张图百分之多少是谁,这是指像素点落在某个范围的概率,那就确认是他本人,故而一些噪点(干扰项)落在别的范围,由于概率小,这些神经元在识别过程中会被直接忽略——dropout
安装TensorFlow
说道深度学习框架,第一反应就是Google的TensorFlow,就是围棋大神AlphaGo的前身。
ubuntu安装
安装python3
sudo apt-get install python3-pip python3-dev python-virtualenv构建虚拟环境
virtualenv --system-site-packages -p python3 ~/tensorflow
source ~/tensorflow/bin/activatesource过后bash环境会有所变化,前方多个括号虚拟目录名,表示在虚拟环境下运行

安装TensorFlow 1.5
pip3 install tensorflow==1.5.0注意:就安装1.5.0版本,默认的最新版(1.6)安装后,import tensorflow会报内存溢出错误,目前没有找到解决方案。
测试:
python3
import tensorflow如果python3的解释器不报错就是安装成功了。
第一个案例
新建一个py文件:
import tensorflow as tf
import numpy as np
x = np.random.rand(100).astype(np.float32)
y = x*311.3+2.2
w = tf.Variable(tf.random_uniform([1],0.0,4.0))
b = tf.Variable(tf.zeros([1]))
y_pre = w*x+b
loss = tf.reduce_mean(tf.square(y_pre-y))
opt = tf.train.GradientDescentOptimizer(0.1)
train = opt.minimize(loss)
init = tf.initialize_all_variables()
session = tf.Session()
session.run(init)
for step in range(10000):
session.run(train)
if step % 100==0:
print step,session.run(w),session.run(b)
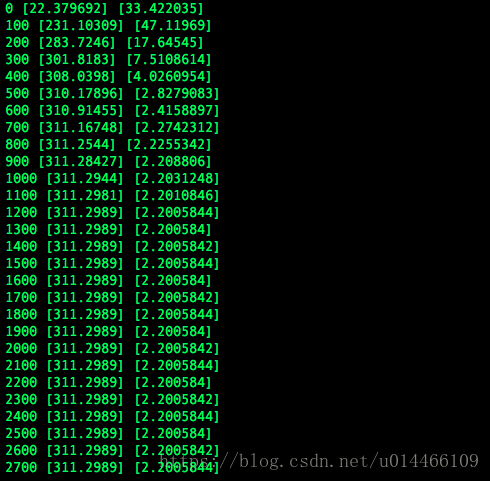
以上python代码是对TensorFlow使用的一个简单例子,实现:求一次函数系数k和偏量b。
如果是人类实现的话,则是采用待定系数法。
机器学习如下:
首先使用numpy制造一些有关系的数字,产生随机的x,然后模拟一个y=kx+b,产生一些y变量,搞出一批(x,y)集合
tf.Variable的作用是给定两个变量并给出初始值,其实就是k与b的初始值,接下来就是让TensorFlow去“猜”k与b是多少,所谓的“猜”就是一个学习过程。
y_pre = w*x+b是给出了函数的基本类型:线性函数,事实上后面学习卷积神经网络之后都不需要给出这样的基本函数类型,而是让机器自己发现。
loss = tf.reduce_mean(tf.square(y_pre-y))
opt = tf.train.GradientDescentOptimizer(0.1)
train = opt.minimize(loss)上面三段代码非常重要,是学习优化的规则,此处使用的是梯度下降优化算法:
loss = (真实值-输出值)^2,loss越小说明梯度越小,则当前机器学习的数值越接近预期值,即我们所给出的y = x*311.3+2.2
最后是要初始化所有提供给神经网络的输入值(变量),然后获取到session,这个session是指机器学习的一个状态,通过他可以获得当前机器学习已经算出的k,b是多少了。根据k,b值来判断是否需要继续学习。当k,b已经为想要的值时可以停止学习了。session.run放在for循环中,训练循环越多则越接近预期值。