Bash的基础特性(3)
(1)bash的快捷键
Ctrl+l:相当于clear,清屏操作
Ctrl+a:将光标跳转至命令首部
Ctrl+e:将光标跳转至结尾处
Ctrl+c:取消命令执行
Ctrl+u:删除光标所在之前的命令
Ctrl+k:删除光标所在处至命令尾部的所有内容
(2)bash中的I/O重定向及管道
程序=指令+数据
读入数据:Input
输出数据:Output
Note:每一个打开的文件都有一个文件描述符(fd)
标准输入:键盘(如果不指定标准输入,则默认为键盘),文件描述符为0
标准输出:显示器(如果不指定输出位置,则默认输出在显示器)文件描述符为1
标准错误输出:显示器,文件描述符为2
I/O重定向:改变输入输出位置
输出重定向:COMMAND > NEW_POS(通常是文件),COMMAND >> NEW_POS
>:覆盖重定向,将输出内容覆盖至目标文件
>>:追加重定向,将输出内容追加至目标文件末尾
例子:
ls /etc > /tmp/etc.out #将"ls /etc"的结果输出到"/tmp/etc.out"
ls /var > /tmp/etc.out #将"ls /var"的结果输出到"/tmp/etc.out"从而覆盖原有的etc.out
ls /var/log >> /tmp/etc.out #将"ls /var/log"内容追加输出到"/tmp/etc.out"
#set -C:禁止将内容覆盖输出至已有文件中,这样比较安全,防止将重要文件覆盖(仅对当前shell有效)
强制覆盖:>|
#set +C:将不允许覆盖重定向功能关闭
标准错误输出重定向:
2>:覆盖,重定向错误输出数据流
2>>:追加,重定向错误输出数据流
标准输出和错误输出各自定向至不同位置
COMMAND > NEW_POS1 2> NEW_POS2 #如果命令成功则将输出保存至NEW_POS1,如果命令失败,则将错误输出保存至
NEW_POS2中
合并标准输出和错误输出为同一个数据流进行重定向:
&>:合并后做覆盖重定向
&>>:合并后追加重定向
COMMAND > "文件路径" 2>&1 #将标准输出覆盖重定向到"文件路径"中,然后将错误输出覆盖重定向到"文件路径中"
COMMAND >> "文件路径" 2>>&1 #将标准输出追加输入到"文件路径"中,然后将错误输出追加重定向到"文件路径中"
输入重定向: < (下列"tr"的例子中有关于输入重定向的语句,可以结合命令理解一下)
tr命令:转换或删除字符(这个命令后期会比较常用的,我建议你最好常用,然后记住怎么用)
tr[OPTION]...SET1[SET2](从标准输入读数据,而标准输入就是键盘)
例子:
1 [root@bogon ~]# tr abc ABC
hello #手动输入hello,查看结果
hello #输入hello后的结果
alpha #手动输入alpha
AlphA #结果"a"就会替换为了"A"
abcdefg #手动输入abcdefg
ABCdefg #结果中输入的"abcdefg"中的"abc"全都替换为了大写
只替换对应的字符集,你也可以再去试试
2 [root@bogon ~]# tr 'a-z' 'A-Z' < /etc/fstab #将/etc/fstab中所有小写字母替换为大写,这就是
输入重定向,本来只能从标注输入读取,我们改变了
它的读取方向,改为/etc/fstab文件了
-d:删除指定的字符
例子:
[root@bogon ~]#tr -d abc
abcdd #手动输入要处理的字符
dd #最后只会剩下dd,因为"-d"选项后面指定了要删除的"abc"字符
HERE Documentation: <<(创建文档)
例子:
1 [root@bogon ~]#cat << EOF
> how are you? #手动键入字符串
> how old are you? #手动键入字符串
> EOF #手动键入字符串,代表结束输入
how are you? #输出结果
how old are you? #输出结果
2 [root@bogon ~]# cat >> /tmp/test.out << EOF #将下列键盘输入的字符重定向到test.out中
> how are you? #手动输入要重定向到test.out的字符
> how old are you? #手动输入要重定向到test.out的字符
> EOF #表示手动输入结束,最终会在test.out中看到输入内容
管道:将前一个命令的结果作为标出输出到下一个命令上,将第二个命令结果输出到第三个命令上执行,以此类推.....
COMMAND1 | COMMAND2 | COMMAND3 |....
Note:最后一个命令会在当前shell进程中的子shell进程中执行;
例子:
[root@bogon ~]# echo '$PATH' | tr 'a-z' 'A-Z' | tr -d 'U'
解释:打印'$PATH'变量,将结果做"tr"处理(将所有小写字母转换为大写),然后再将结果传送到下一个"tr"处理
"-d"删除所有"U"字母!
tee命令:从标准输入读数据,输出到屏幕上同时也可以输出到文件中
tee [OPTION]... [FILE]...
例子:
[root@bogon ~]# tee /tmp/tee.out #结果输出到了屏幕上,同时也输出到了tee.out文件中
first line. #手动输入的字符
first line. #输入后输出的字符
www.test.com #手动输入的字符
www.test.com #输入后输出的字符
练习
1、将/etc/passwd文件中的前5行内容转换为大写后保存至/tmp/passwd.out文件中?
解:head -n5 /etc/passwd | tr '[[:lower:]]' '[[:upper:]]' | tee /tmp/passwd.out
#首先使用"head -n5"筛出"/etc/passwd"的前五行,然后输出至"tr"命令中做大小写替换的处理"[[:lower:]]与[[:upper:]]"
在上一章有讲过,如果看了上一章还不知道什么意思就去好好再看看吧,再将"tr"处理的结果输出至"tee"命令做处理,得到结果
如果不想输出到屏幕上则使用head -n5 /etc/passwd | tr '[[:lower:]]' '[[:upper:]]' > /tmp/passwd.out
2、将登陆至当前系统上用户信息中的前3位的信息转化为大写后保存至/tmp/who.out文件中?
解:who | head -n3 | tr '[[:lower:]]' '[[:upper:]]' | tee /tmp/who.out
#首先使用"who"命令查看出当前登录至系统的用户信息,标准输出至"head"命令处理取前三行之后,再标准输出至"tr"命令转换
字母大小写,最后标准输出至"tee"命令输出至屏幕同时输出至"/tmp/who.out"的文件中
如果不想输出到屏幕上则使用who | head -n3 | tr '[[:lower:]]' '[[:upper:]]' > /tmp/who.out文本处理工具:wc,sort,cut,uniq
wc命令:
wc [OPTION]...[FILE]...
例子:
[root@bogon ~]# wc /etc/passwd
38 77 1989 /etc/passwd #38行,77个单词,1989个字节,逐一对应的是"行数","单词数","字节数",单词
是以空白字符分隔来区分的,不是英语中的那种单词
常用选项:
-l:只统计行数
-w:只统计单词数
-c:只统计字节数
cut命令:以指定"字符"作为"分隔符"对一行文本进行切割,然后取出第几列,默认以空白字符进行切割
cut [OPTION]... [FILE]...
常用选项:(如果选项看不太明白,案例中有详细说明还有图片)
-d:指定分隔符
-f:指定要取出的列
#:第几个字段比如"-f1"就是第一个字段也就是第一列
#,#:第几个字段和第几个字段,比如"-f1,3"就是第一个字段和第三个字段
#-#:第几个字段到第几个字段,比如"-f1-3"就是第一个字段到第三个字段
--output-delimiter= :指定输出分隔符
例子:
1 [root@bogon ~]# cut -d' ' -f1 /etc/fstab #指定"空白字符"作为分隔符,并取出第一列
-f1,3 #取出第一个和第三个字段
-f1-3 #取出第一个到第三个字段
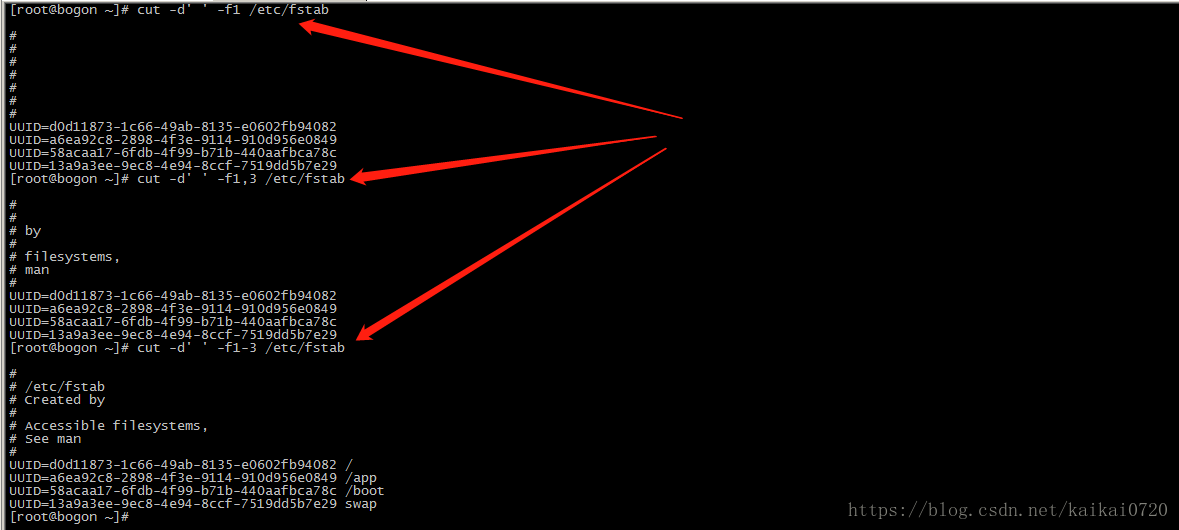
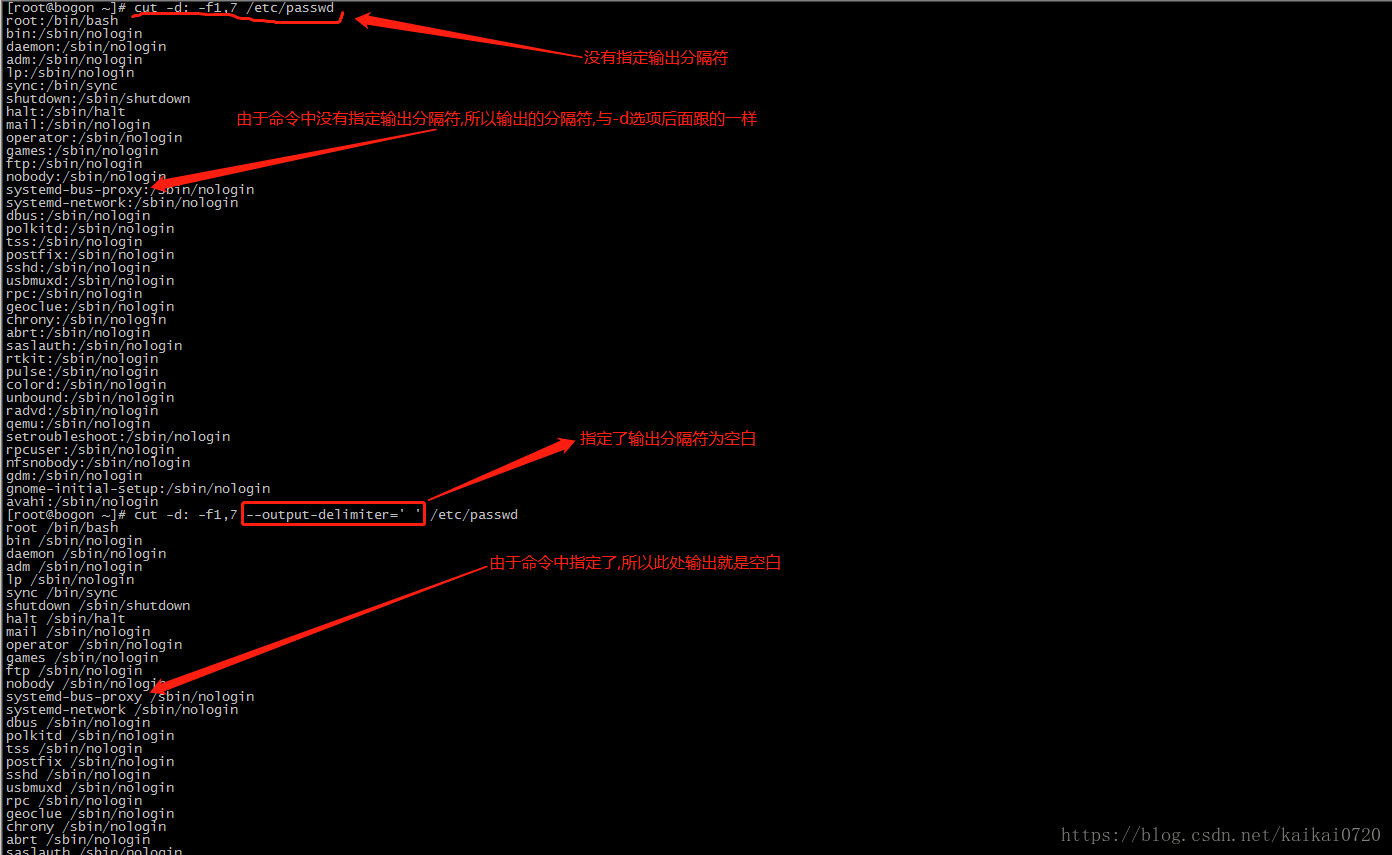
2 [root@bogon ~]# cut -d: -f1 /etc/passwd #指定":"为分隔符,并取出第一列
-f1,7 #取出第一列和第七列,输出时的分隔符跟指定的一样
-f1,7 --output-delimiter=' ' #取出第一列和第七列,指定输出分隔符为"空白"
sort命令:
常用选项:
-r:逆序方法排序
-f:忽略字符大小写
-k:以第几个字段为标准排序
-t:指明字段分隔符
-n:以数值大小排序
-u:排序后去重显示
例子:
1 sort /etc/passwd #默认显示出的结果是以每一行的字母"a-z"排序
2 sort -t: -k3 /etc/passwd #指定":"为分隔符,以第三列为标准排序,如图,看完图之后肯定很疑惑,为什么有数
值小的在数值大的下面,其实已经排序了,只不过这里面是以"ASCII"表中字符排的
序,也就是说,把第三列的数字都看成了字符来进行排的序,第二张图是"ascii"表
如果想以数值大小排列,再加一个"-n"选项即可
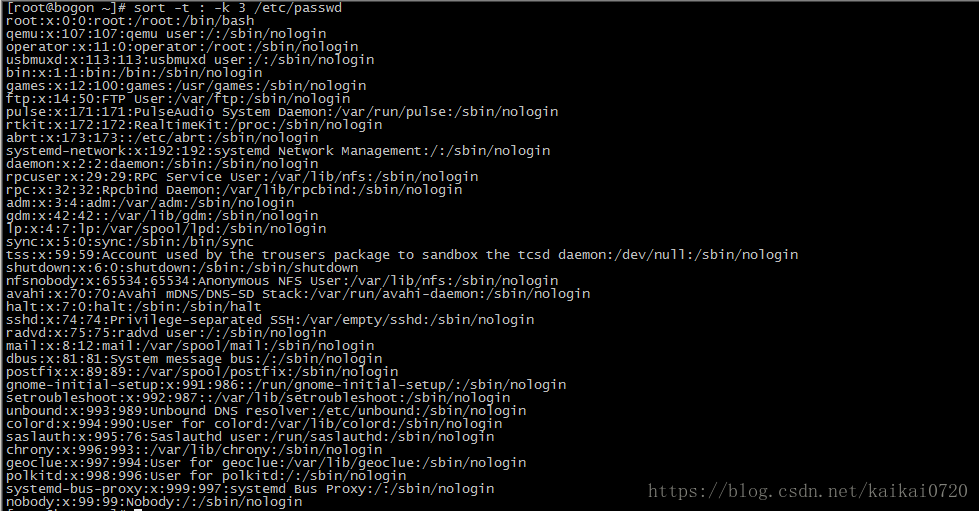
uniq命令:
uniq [OPTION]... [FILE]...
Note:连续且完全相同方位重复
常用选项:
-c:显示每行重复出现的次数
-d:仅显示重复过的行
-u:仅显示未重复过的行
练习
以冒号分隔,取出/etc/passwd文件中的第6至第10行,并将这些信息按第三个字段的数值大小进行排序,最后仅显示各自的第一个
字段?
解:sed -n 6,10p /etc/passwd | sort -n -t: -k3 | cut -d: -f1
#sed命令后面还会在讲,此处你只要知道"sed"能打印出第6行到第10行就ok了,然后标准输出到"sort"命令,来对第三个字段
排序进行,再标准输出到"cut"命令来剪切出第一个字段