基于昨天的内容,今天继续对这个小爬虫在功能方面进行扩充,经过今天的改进,爬虫在功能方面已经基本成型,可以做到对ins上个人账号中的图片、视频、图片集进行批量获取。
part 4 不足和值得改进之处(接昨天内容)
昨天的小爬虫虽然已经能够爬到ins上面的简单图片,但是在功能方面存在不少欠缺,比如ins上面还有很多短视频,ins详情页中还有图片集,而我们昨天的代码只能爬取页面的第一张图片。
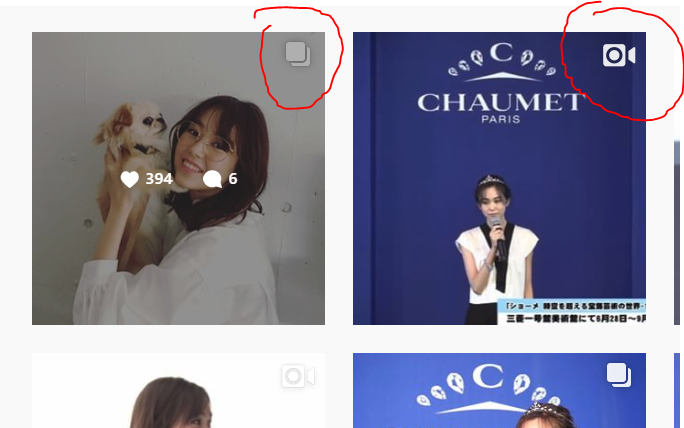
ins中的多图和视频
今天我们所需要达到的目标就是使得爬虫能够分析出多图以及视频页面然后对其进行相应的下载。在分析过程中我们还能看到有更多信息能够从ins详情页中获取(如果想要分析更多数据的话)。
part 5 多图页面分析
昨天我们只是从单一图片的页面找到了图片URL,今天由于需要分析多图的存在情况,并且需要对视频和图片进行分离,我们更加需要对图片详情页的网页源代码进行分析。
通过对比单图页面和多图页面的区别,一段js代码使我看到了解决问题的希望:
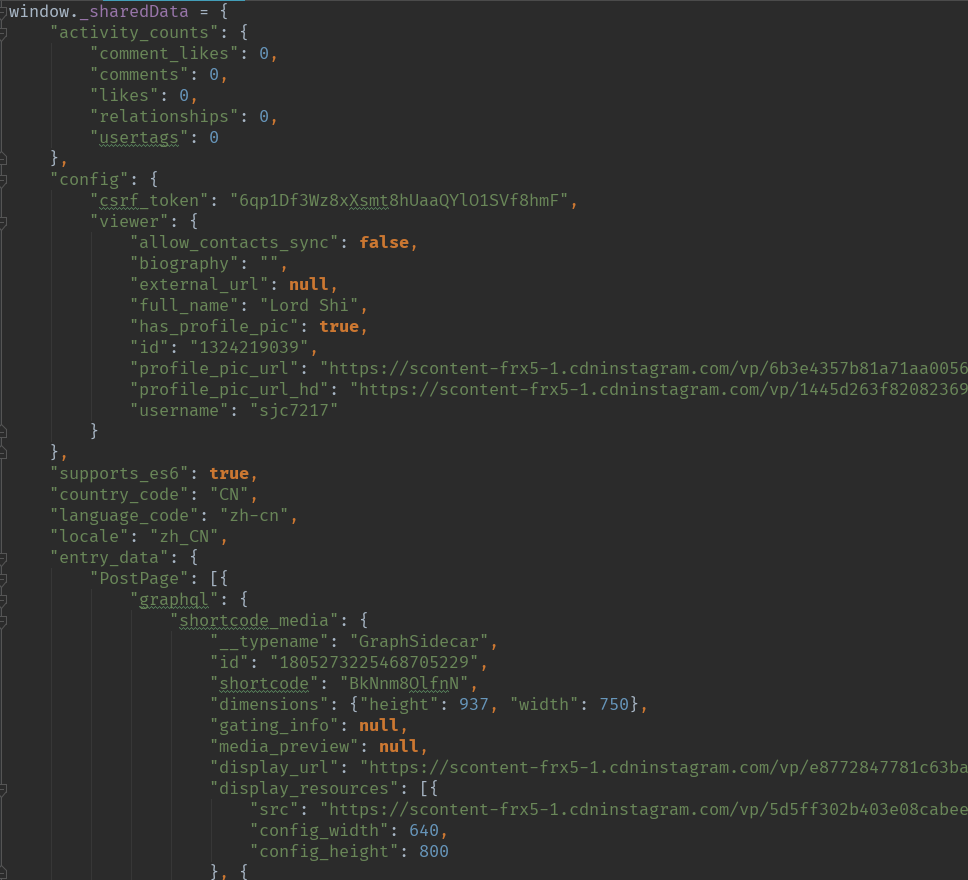
经过格式化的详情页js代码
这段js代码所在的位置用xpath表示为'/html/body/script[1]'。这个名为window._sharedData的js变量就保存了我们所需要的所有信息,而且我们可以很方便的通过requests获取到它。通过使用json格式化这段字符串,我们能够找到当前页面的所有信息,包括页面资源类型,当前访问用户,各种资源URL,以及当前资源上的许多其他信息。
从上图中就可以看到其中的一个‘__typename’字段就表示了当前资源的类型,当前是‘GraphSidecar’表示当前页面有多个资源。‘GraphImage’表示单一图片,‘GraphVideo’表示视频。
接下来我们需要做的自然就是通过这个json对象获得我们所需要的资源信息,然后下载啦。
part 6 代码与一些注意事项
在写代码时需要注意对于资源类型的判断,有些多图页面同样包含视频资源,注意鉴别。
import requests import time import os import json import sys import time from lxml import etree from selenium import webdriver from selenium.webdriver.common.keys import Keys from selenium.webdriver.common.action_chains import ActionChains options = webdriver.ChromeOptions() options.add_argument('lang=zh_CN.UTF-8') driver = webdriver.Chrome(chrome_options = options) target = 'https://www.instagram.com/mirei.kiritani/' url_set = set([]) driver.get(target) url_set=set([]) url_set_size = 0 save_dir = './pic_test/' if not os.path.exists(save_dir): os.mkdir(save_dir) header = { 'accept': '*/*', 'accept-encoding': 'gzip, deflate, br', 'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-US;q=0.7', 'cookie': 'shbid=4419; rur=PRN; mcd=3; mid=W1E7cAALAAES6GY5Dyuvmzfbywic; csrftoken=uVspLzRYlxjToqSoTlf09JVaA9thPkD0; urlgen="{\"time\": 1532050288\054 \"2001:da8:e000:1618:e4b8:8a3d:8932:2621\": 23910\054 \"2001:da8:e000:1618:6c15:ccda:34b8:5dc8\": 23910}:1fgVTv:SfLAhpEZmvEcJn0037FXFMLJr0Y"', 'referer': 'https://www.instagram.com/', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36', } while(True): divs = driver.find_elements_by_class_name('v1Nh3') for u in divs: url_set.add(u.find_element_by_tag_name('a').get_attribute('href')) if len(url_set) == url_set_size or len(url_set) > 30: #测试 break url_set_size = len(url_set) ActionChains(driver).send_keys(Keys.PAGE_DOWN).perform() ActionChains(driver).send_keys(Keys.PAGE_DOWN).perform() ActionChains(driver).send_keys(Keys.PAGE_DOWN).perform() time.sleep(3) def resource_download(u_download): rec = requests.get(u_download, headers = header) selector = etree.HTML(rec.content) script = selector.xpath('/html/body/script[1]')[0] #获得页面js脚本,用于分析页面资源情况 scr_json = script.text[21:-1] try: json_res = json.loads(scr_json) #获得相应页面json信息 except: print("Get page resource failed,can't convert to json! Failed URL:" + u_download) sys.exit() media_info = json_res['entry_data']["PostPage"][0]["graphql"]["shortcode_media"] if media_info["__typename"] == "GraphImage": download_single_pic(media_info) elif media_info["__typename"] == "GraphSidecar": download_multi_media(media_info) elif media_info["__typename"] == "GraphVideo": download_single_video(media_info) def download_single_pic(media_info, filename = None): #单图下载函数,注意单图来源(单一页面;多图页面内部调用) pic_url = media_info['display_url'].strip() #优化扩展名获取方式 ext = pic_url.split('.')[-1] if filename == None: timestamp = media_info['taken_at_timestamp'] localtime = time.localtime(timestamp) pic_name = save_dir + 'mirei_' + time.strftime("%Y-%m-%d_%H%M%S",localtime) + '.' + ext #根据图片时间命名本地文件 else: pic_name = filename f = open(pic_name,'wb') pic_bin = requests.get(pic_url).content f.write(pic_bin) f.close() def download_multi_media(media_info): #download_single_pic(media_info) pics_url = media_info['edge_sidecar_to_children']['edges'] pic_count = len(pics_url) timestamp = media_info['taken_at_timestamp'] localtime = time.localtime(timestamp) for i in range(pic_count): node = pics_url[i]['node'] if node['__typename'] == 'GraphImage': #多图页面需要判断资源类型 pic_url = node['display_url'].strip() ext = pic_url.split('.')[-1] pic_name = save_dir + 'mirei_' + time.strftime("%Y-%m-%d_%H%M%S",localtime) + '_' +str(i) + '.' + ext download_single_pic(node, pic_name) elif node['__typename'] == 'GraphVideo': video_url = node['video_url'].strip() ext = video_url.split('.')[-1] video_name = save_dir + 'mirei_' + time.strftime("%Y-%m-%d_%H%M%S",localtime) + '_' +str(i) + '.' + ext download_single_video(node, video_name) else: pass def download_single_video(media_info, filename = None): video_url = media_info['video_url'].strip() ext = video_url.split('.')[-1] if filename == None: timestamp = media_info['taken_at_timestamp'] localtime = time.localtime(timestamp) video_name = save_dir + 'mirei_' + time.strftime("%Y-%m-%d_%H%M%S",localtime) + '.' + ext else: video_name = filename f = open(video_name,'wb') video_bin = requests.get(video_url).content f.write(video_bin) f.close() for url_ in url_set: resource_download(url_)
参考:https://blog.csdn.net/google19890102/article/details/51355282
http://www.runoob.com/python/python-json.html