正则表达式是处理字符串查找、匹配、替换的非常有效的工具,记录python中正则表达式模块re的常用方法。
1、re.compile(pattern[, flag])
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
参数:
pattern : 一个字符串形式的正则表达式
flags : 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为:
- re.I 忽略大小写
- re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
- re.M 多行模式
- re.S 即为 . 并且包括换行符在内的任意字符(. 不包括换行符)
- re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库
- re.X 为了增加可读性,忽略空格和 # 后面的注释
2、 re.match(pattern,string,flag=0)
从字符串的起始位置匹配一个模式(pattern),如果不是起始位置匹配成功的话,返回None
参数:
- pattern : 匹配的正则表达式
- string : 要匹配的字符串
- flag :标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见【1】中的flags
3、re.search(pattern,string,flags=0)
扫描整个字符串并返回第一个成功的匹配
参数:
- pattern : 匹配的正则表达式
- string : 要匹配的字符串
- flag :标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见【1】中的flags
re.match与re.search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
4、re.sub(pattern,repl,string,count=0,flags=0)
替换字符串中的匹配项
参数:
- pattern : 正则中的模式字符串。
- repl : 替换的字符串,也可为一个函数。
- string : 要被查找替换的原始字符串。
- count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
5、re.findall(string[,pos[,endpos]])
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回一个空列表
注意:match 和 search 是匹配一次 findall 匹配所有。
参数:
- string : 待匹配的字符串。
- pos : 可选参数,指定字符串的起始位置,默认为 0。
- endpos : 可选参数,指定字符串的结束位置,默认为字符串的长度。
6、re.finditer(pattern,string,flags=0)
和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。
参数:
- pattern : 匹配的正则表达式
- string : 要匹配的字符串
- flag :标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见【1】中的flags
7、re.split(pattern,string[ ,maxsplit=0,flag=0])
按照能够匹配的子串将字符串分割后返回列表
参数:
- pattern : 匹配的正则表达式
- string : 要匹配的字符串
- maxsplit : 分隔次数,maxsplit=1 分隔一次,默认为0,不限制次数
- flag :标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见【1】中的flags
python支持的正则表达式元字符和语法:
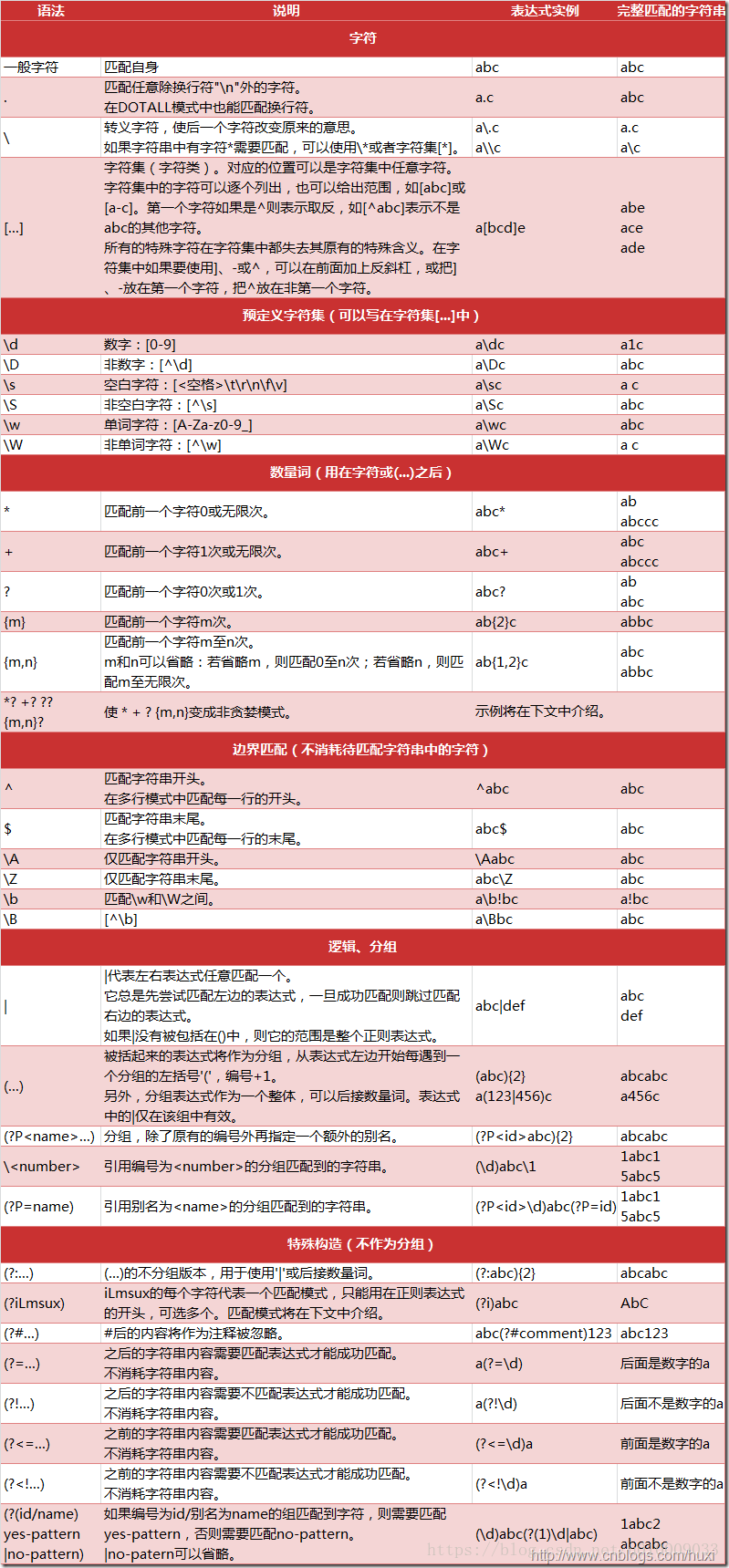
只整理了常用方法,后续更新更高级用法。
参考:
[1] http://www.runoob.com/python/python-reg-expressions.html#flags
[2] http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html