摘要: 本文将介绍如何利用阿里云云监控服务提供的自定义监控实现GPU云服务器的GPU监控和报警的可视化,从而达到对GPU使用情况实时掌握的目的。

1 背景
NVIDIA提供了nvidia-smi命令工具用于查询和监控GPU的相关数据,但是对于使用者来说,每次手动查看很不方便,无法做到实时监控,而且也无法可视化,不直观。
本文将会介绍如何利用阿里云云监控服务提供的自定义监控功能来实现GPU云服务器的GPU监控和报警的可视化。
2 自定义监控和报警
阿里云云监控服务提供了自定义监控功能,用户可以利用它实现自定义的数据监控和报警。
我们利用自定义监控提供的API或者SDK,可以将GPU云主机内采集的GPU数据上报,在云监控控制台上添加相应的GPU监控项,就可以实现对指定GPU实例内指定GPU的相应数据进行监控,对相应监控项设置相应数据的报警规则,就能实现监控数据的自动报警。
比如可以对GPU利用率、显存利用率、显存占用、功率、温度等关键信息进行监控和报警。
详见:创建自定义监控项和报警规则
3 监控数据上报
自定义监控提供的SDK支持Python和bash,通过编写脚本调用SDK的接口,可以实现相应监控数据的上报。
通过定时调度脚本,按创建监控项时定义的上报周期上报数据。Linux环境可以使用Crontab,Windows环境可以使用quartz.net。
详见:监控数据上报
4 GPU数据采集
NVDIA驱动安装时提供了NVIDIA Management Library (NVML),该库提供了采集GPU数据的接口,并基于NVML提供了nvidia-smi命令用于采集GPU相关数据。NVML提供了Perl 和Python语言的官方支持,考虑到自定义监控上报SDK支持Python,我们可以下载NVML的Python bindings,编写Python脚本采集GPU数据。
5 示例
5.1 创建自定义监控项
在云监控控制台创建自定义监控项,如下图:
5.2 查看监控项数据
在云监控控制台查看监控项,如下图:
某实例GPU 0的GPU利用率(单位:Persent):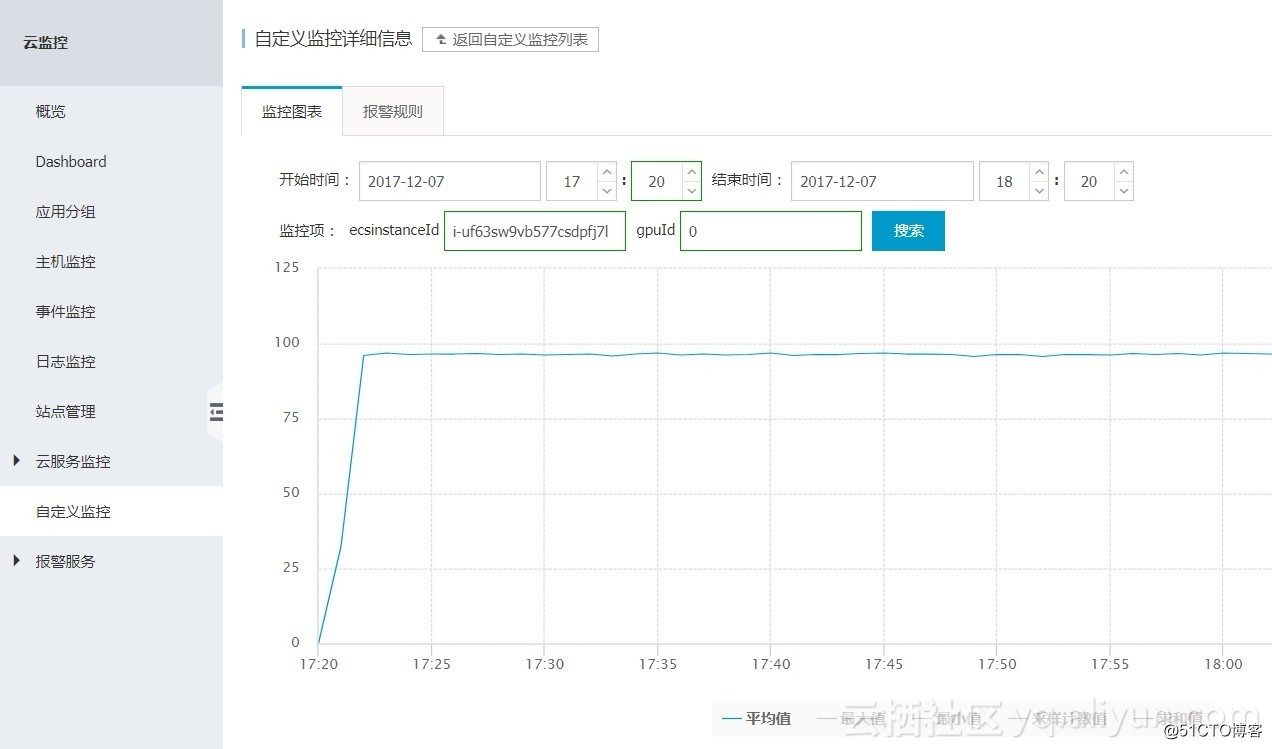
某实例GPU 0的显存利用率(单位:Persent):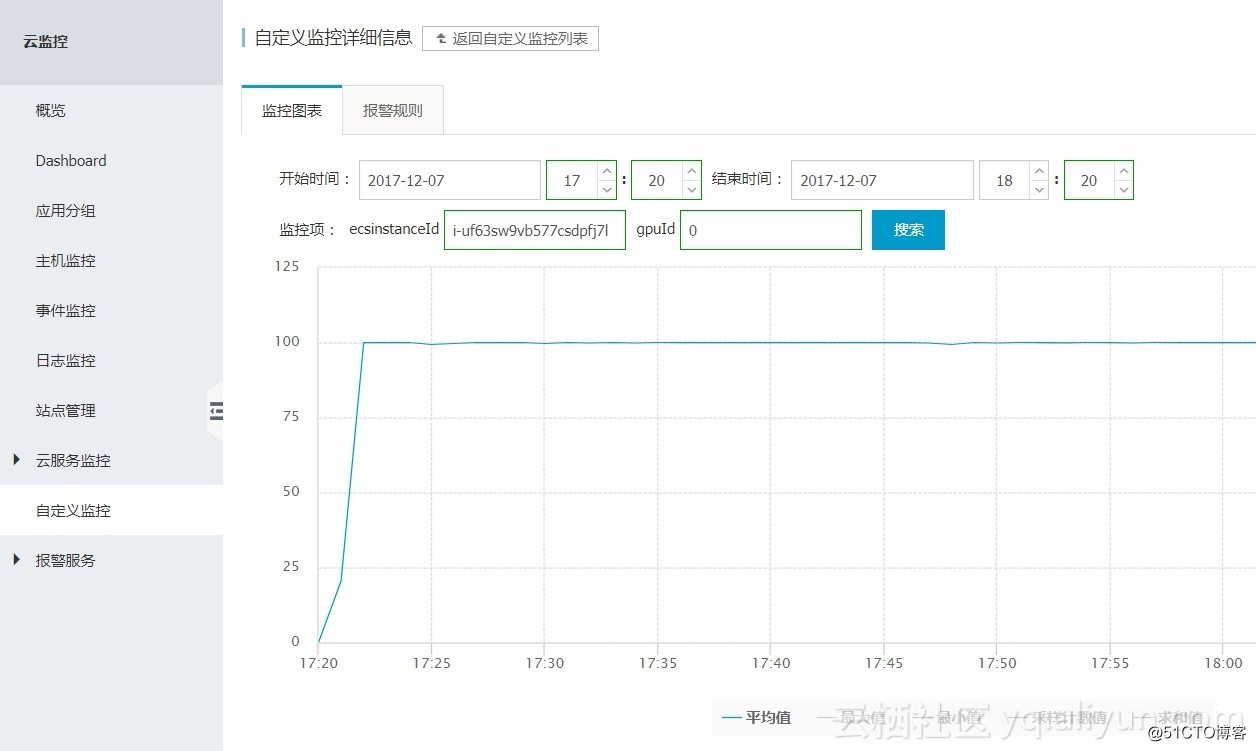
某实例GPU 0的内存占用量(单位:Megabytes):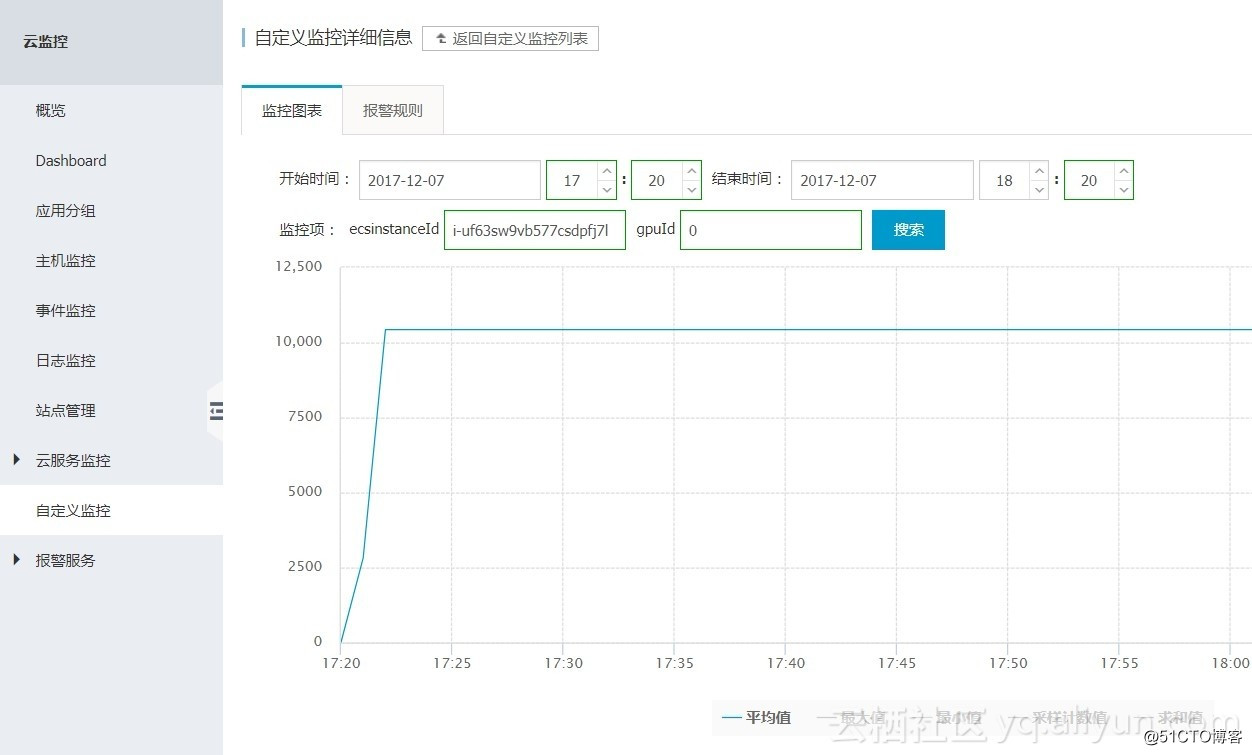
某实例GPU 1的功率(单位:Watt):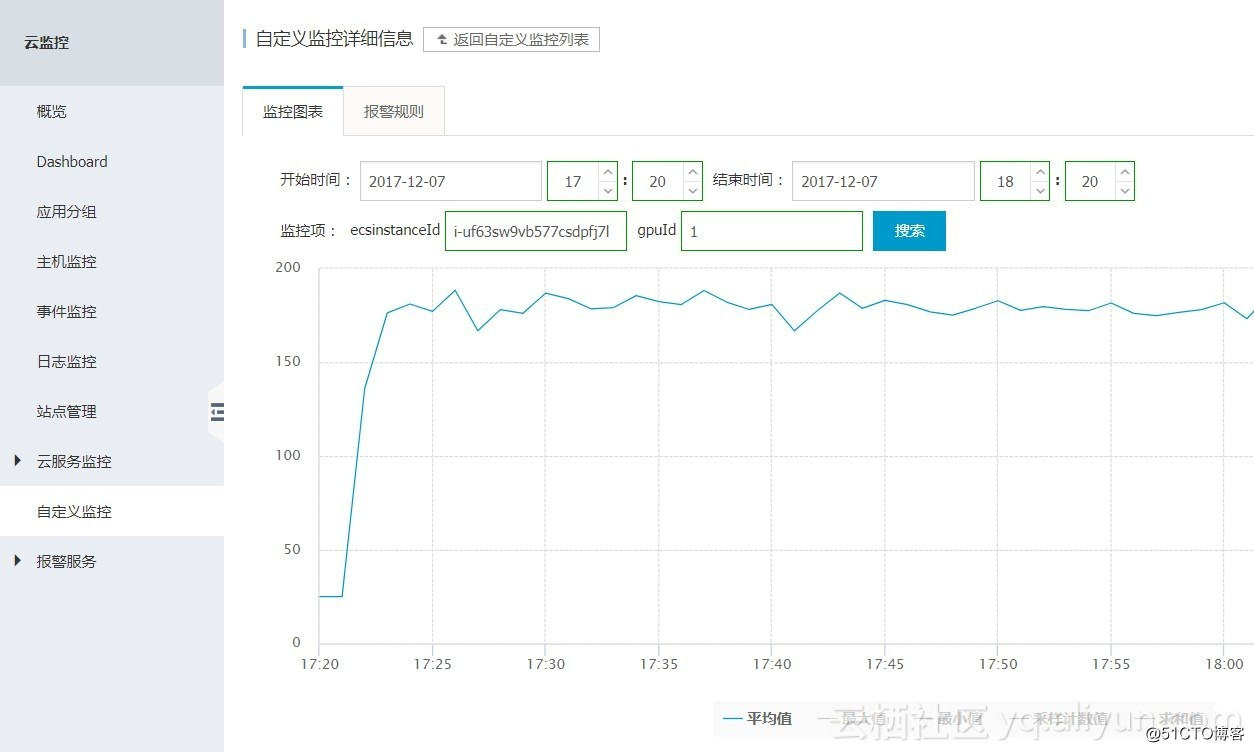
某实例GPU 1 的温度(单位:摄氏度):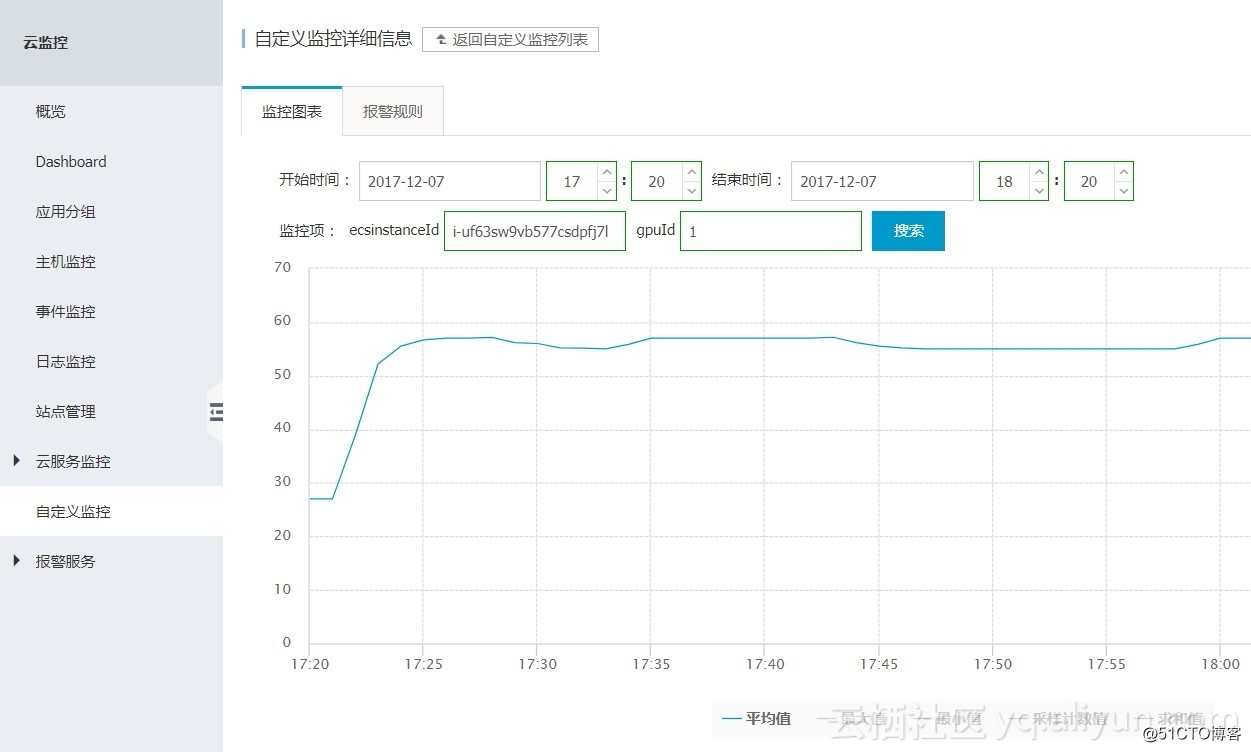
5.3 设置报警规则
在温度监控项上点击报警管理:
设置温度报警规则: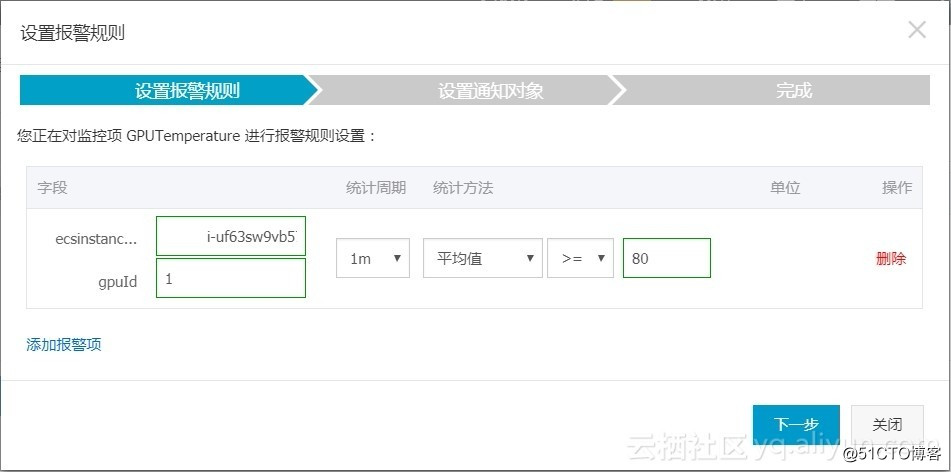
设置通知对象: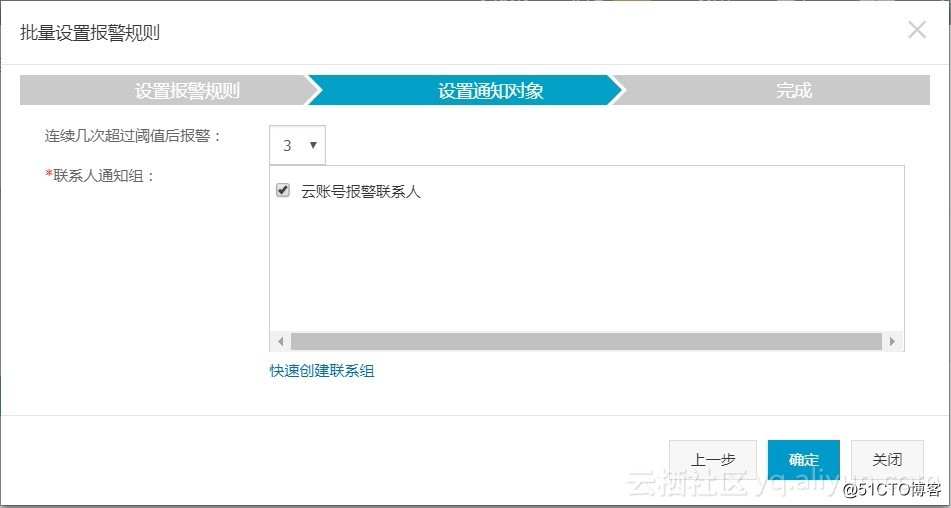
完成设置: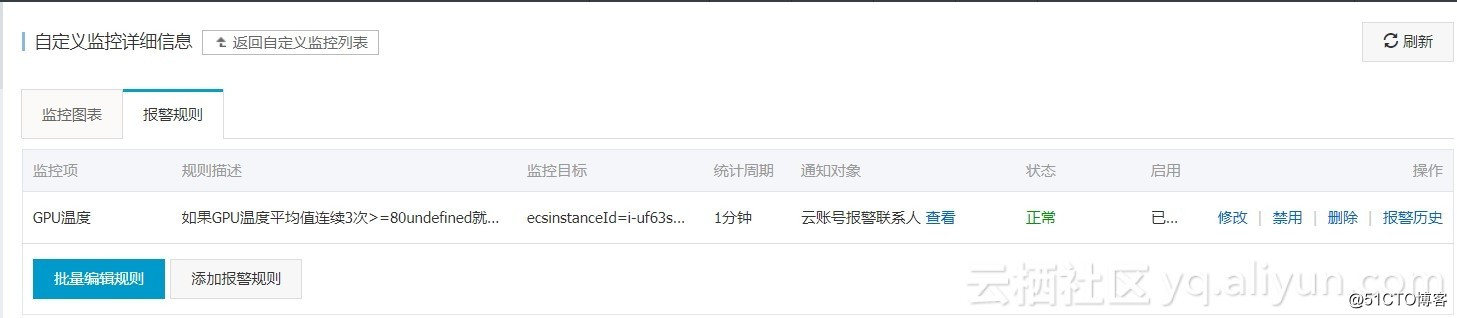
6 参考代码
数据采集:
def get_gpu_information():
nvmlInit()
deviceCount = nvmlDeviceGetCount()
util_list = []
for i in range(0, deviceCount):
handle = nvmlDeviceGetHandleByIndex(i)
util_list.append(nvmlDeviceGetUtilizationRates(handle))
nvmlShutdown()
return deviceCount, util_list信息上报:
for i in range(0, GPU_Count):
gpuid = i
cms_post.post(userid,"GPUUtilization",util_list[i].gpu,"Percent",s.format(ecsid=ecsid, gpuid=gpuid))原文链接
本文为云栖社区原创内容,未经允许不得转载。