1 HTML基础
1.1 HTML结构
HTML是超文本标记语言,被web浏览器进行解析查看。它的文档制作简单,功能强大 ,支持很多其他格式文件的嵌入。”超文本“文档主要由头部(head)和主体(body )两部分组成
<head> 定义了文档的信息
<title> 定义了文档的标题
<base> 定义了页面链接标签的默认链接地址
<link> 定义了一个文档和外部资源之间的关系
<meta> 定义了HTML文档中的元数据
<script> 定义了客户端的脚本文件
<style> 定义了HTML文档的样式文件1.2 HTML各标签结构
- div是标签名
- id是为该标签设置的唯一标识
- class是该标签的样式类
- attr是设置的其他属性
- content是的标签的文本内容
1.3 HTML样式
- id选择器:#id_name,选择id=id_name的所有元素
- 类选择器:.cls_name,选择class=cls_name的所有元素
- 标签选择:lable,选择标签名为lable的所有元素,用逗号隔开可选择多个标签
- 全部选择:*,选择所有的元素
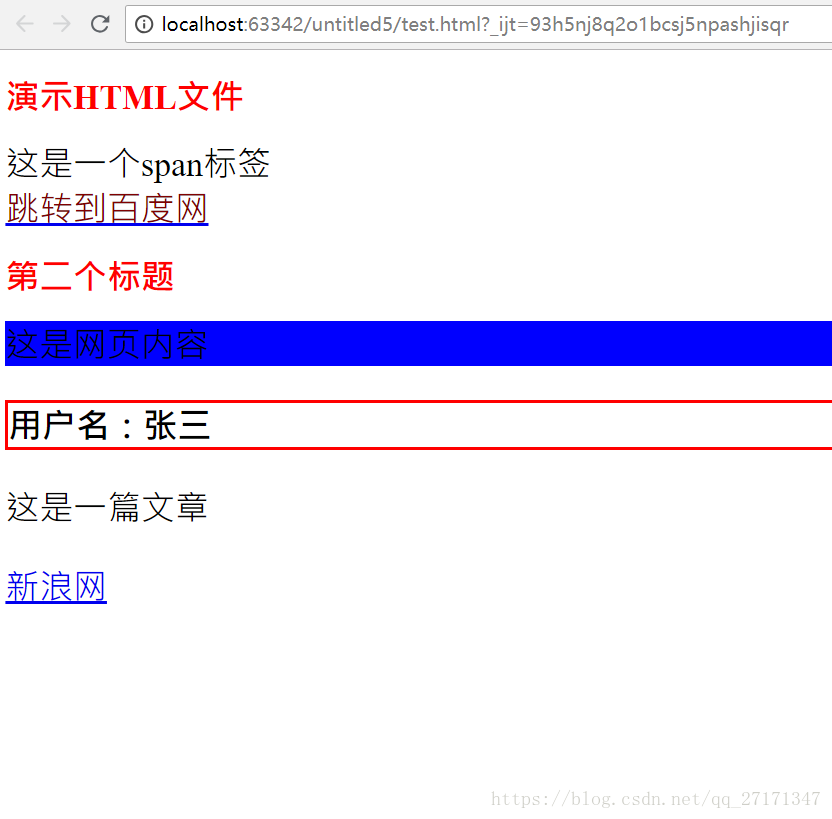
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>网页标题</title>
<style>
*{ /*通配符*/
font-size:50px;
}
h1{ /*标签选择器*/
color:red;
}
div.content{ /*类选择器,不唯一,可以多个标签使用同一个class名*/
background-color:blue;
}
#name{ /*id选择器*/
border: 4px solid red;
}
a span{ /*选中a标签内的所有span标签*/
color:maroon;
}
a>span{ /*只选中a标签的第一级子标签中的span*/
}
a[title="新浪"]{
}
</style>
</head>
<body>
<h1>演示HTML文件</h1>
<span>这是一个span标签</span>
<a href="http://www.baidu.com">
<div>
<span>跳转到百度网</span>
</div>
</a>
<h1>第二个标题</h1>
<div class="content">这是网页内容</div>
<h3 id="name">用户名:张三</h3>
<p class="content">这是一篇文章</p>
<a href="http://www.sina.com" title="新浪">新浪网</a>
</body>
</html>运行结果:
2.正则表达式
正则表达式(或 RE)是一种小型的、高度专业化的编程语言,(在Python中)它内嵌在Python中,并通过 re 模块实现。正则表达式模式被编译成一系列的字节码,然后由用 C 编写的匹配引擎执行。
字符匹配(普通字符,元字符):
1 普通字符:大多数字符和字母都会和自身匹配
re.findall('alvin','yuanaleSxalexwupeiqi')
#['alvin'] 2 元字符:. ^ $ * + ? { } [ ] | ( ) \
2.1 元字符
2.1.1 元字符之. ^ $ * + ? { }
import re
ret=re.findall('a..in','helloalvin')
print(ret)#['alvin']
ret=re.findall('^a...n','alvinhelloawwwn')
print(ret)#['alvin']
ret=re.findall('a...n$','alvinhelloawwwn')
print(ret)#['awwwn']
ret=re.findall('a...n$','alvinhelloawwwn')
print(ret)#['awwwn']
ret=re.findall('abc*','abcccc')#贪婪匹配[0,+oo]
print(ret)#['abcccc']
ret=re.findall('abc+','abccc')#[1,+oo]
print(ret)#['abccc']
ret=re.findall('abc?','abccc')#[0,1]
print(ret)#['abc']
ret=re.findall('abc{1,4}','abccc')
print(ret)#['abccc'] 贪婪匹配
#前面的*,+,?等都是贪婪匹配,也就是尽可能匹配,后面加?号使其变成惰性匹配
ret=re.findall('abc*?','abcccccc')
print(ret)#['ab']2.1.2 元字符之字符集[]
ret=re.findall('a[bc]d','acd')
print(ret)#['acd']
ret=re.findall('[a-z]','acd')
print(ret)#['a', 'c', 'd']
ret=re.findall('[.*+]','a.cd+')
print(ret)#['.', '+']
#在字符集里有功能的符号: - ^ \
ret=re.findall('[1-9]','45dha3')
print(ret)#['4', '5', '3']
ret=re.findall('[^ab]','45bdha3')
print(ret)#['4', '5', 'd', 'h', '3']
ret=re.findall('[\d]','45bdha3')
print(ret)#['4', '5', '3']2.1.3 元字符之转义符 \
反斜杠后边跟元字符去除特殊功能,比如.
反斜杠后边跟普通字符实现特殊功能,比如\d
- \d 匹配任何十进制数;它相当于类 [0-9]。
- \D 匹配任何非数字字符;它相当于类 [^0-9]。
- \s 匹配任何空白字符;它相当于类 [ \t\n\r\f\v]。
- \S 匹配任何非空白字符;它相当于类 [^ \t\n\r\f\v]。
- \w 匹配任何字母数字字符;它相当于类 [a-zA-Z0-9_]。
- \W 匹配任何非字母数字字符;它相当于类 [^a-zA-Z0-9_]
- \b 匹配一个特殊字符边界,比如空格 ,&,#等
ret=re.findall('I\b','I am LIST')
print(ret)#[]
ret=re.findall(r'I\b','I am LIST')
print(ret)#['I']
#-----------------------------eg1:
import re
ret=re.findall('c\l','abc\le')
print(ret)#[]
ret=re.findall('c\\l','abc\le')
print(ret)#[]
ret=re.findall('c\\\\l','abc\le')
print(ret)#['c\\l']
ret=re.findall(r'c\\l','abc\le')
print(ret)#['c\\l']
#-----------------------------eg2:
#之所以选择\b是因为\b在ASCII表中是有意义的
m = re.findall('\bblow', 'blow')
print(m)
m = re.findall(r'\bblow', 'blow')
print(m)2.1.4 元字符之分组()
m = re.findall(r'(ad)+', 'add')
print(m)
ret=re.search('(?P<id>\d{2})/(?P<name>\w{3})','23/com')
print(ret.group())#23/com
print(ret.group('id'))#23
2.1.4 元字符之|
ret=re.search('(ab)|\d','rabhdg8sd')
print(ret.group())#ab2.1.5 正则表达式模式总结
| 模式 | 描述 |
|---|---|
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的末尾。 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 |
| […] | 用来表示一组字符,单独列出:[amk] 匹配 ‘a’,’m’或’k’ |
| [^…] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
| re* | 匹配0个或多个的表达式。 |
| re+ | 匹配1个或多个的表达式。 |
| re? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
| re{ n} | 匹配n个前面表达式。例如,”o{2}”不能匹配”Bob”中的”o”,但是能匹配”food”中的两个o。 |
| re{ n,} | 精确匹配n个前面表达式。例如,”o{2,}”不能匹配”Bob”中的”o”,但能匹配”foooood”中的所有o。”o{1,}”等价于”o+”。”o{0,}”则等价于”o*”。 |
| re{ n, m} | 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
| aIb | 匹配a或b |
| (re) | G匹配括号内的表达式,也表示一个组 |
| (?imx) | 正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域。 |
| (?-imx) | 正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域。 |
| (?: re) | 类似 (…), 但是不表示一个组 |
| (?imx: re) | 在括号中使用i, m, 或 x 可选标志 |
| (?-imx: re) | 在括号中不使用i, m, 或 x 可选标志 |
| (?#…) | 注释. |
| (?= re) | 前向肯定界定符。如果所含正则表达式,以 … 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。 |
| (?! re) | 前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功。 |
| (?> re) | 匹配的独立模式,省去回溯。 |
| \w | 匹配数字字母下划线 |
| \W | 匹配非数字字母下划线 |
| \s | 匹配任意空白字符,等价于 [\t\n\r\f]。 |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字,等价于 [0-9]。 |
| \D | 匹配任意非数字 |
| \A | 匹配字符串开始 |
| \Z | 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。 |
| \z | 匹配字符串结束 |
| \G | 匹配最后匹配完成的位置。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, ‘er\b’ 可以匹配”never” 中的 ‘er’,但不能匹配 “verb” 中的 ‘er’。 |
| \B 匹配非单词边界。 | ‘er\B’ 能匹配 “verb” 中的 ‘er’,但不能匹配 “never” 中的 ‘er’。 |
| \n, \t, 等。 | 匹配一个换行符。匹配一个制表符, 等 |
| \1…\9 | 匹配第n个分组的内容。 |
| \10 | 匹配第n个分组的内容,如果它经匹配。否则指的是八进制字符码的表达式。 |
2.2 re模块下的常用方法
import re
#1
re.findall('a','alvin yuan') #返回所有满足匹配条件的结果,放在列表里
#2
re.search('a','alvin yuan').group() #函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以
# 通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。
#3
re.match('a','abc').group() #同search,不过尽在字符串开始处进行匹配
#4
ret=re.split('[ab]','abcd') #先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割
print(ret)#['', '', 'cd']
#5
ret=re.sub('\d','abc','alvin5yuan6',1)
print(ret)#alvinabcyuan6
ret=re.subn('\d','abc','alvin5yuan6')
print(ret)#('alvinabcyuanabc', 2)
#6
obj=re.compile('\d{3}')
ret=obj.search('abc123eeee')
print(ret.group())#123
ort re
ret=re.finditer('\d','ds3sy4784a')
print(ret) #<callable_iterator object at 0x10195f940>
print(next(ret).group())
print(next(ret).group())
#注意:
import re
ret=re.findall('www.(baidu|oldboy).com','www.oldboy.com')
print(ret)#['oldboy'] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可
ret=re.findall('www.(?:baidu|oldboy).com','www.oldboy.com')
print(ret)#['www.oldboy.com']爬虫案例 1
爬取51job爬虫所爬取的职位信息数据,并将数据保存进excel中
import re
import requests
import xlwt
url = "https://search.51job.com/list/020000,000000,0000,00,9,99,python,2,{}.html?lang=c&stype=1&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare="
# 爬取第一页数据
firstpage = url.format(1)
response = requests.get(firstpage)
# 转化成gbk编码
html = str(response.content, "gbk")
# print(html)
# 获取总页数
pattern = re.compile('<span class="td">共(.*?)页,到第</span>', re.S)
result = re.findall(pattern, html)
totalPage = int(result[0])
# print("总页数:{}".format(totalPage))
# 循环爬取所有数据
for page in range(1, 11):#这里仅爬取十页信息
# print("---------------正在爬取第{}页数据---------------".format(page))
# 组装当前页的页码
currentUrl = url.format(page)
# print(currentUrl[0:80])
response = requests.get(currentUrl)
html = str(response.content, "gbk")
reg = re.compile('class="t1 ">.*? <a target="_blank" title="(.*?)".*? <span class="t2"><a target="_blank" title="(.*?)".*?<span class="t3">(.*?)</span>.*?<span class="t4">(.*?)</span>.*? <span class="t5">(.*?)</span>',re.S) # 匹配换行符
#获取一页中所有的职位信息
onePage = re.findall(reg,html)
#循环输出一页中所有的职位信息
# for jobName, company, place, salary, postDate in onePage:
# pass
# print("名称:{},公司:{},地址:{},薪资:{},发布日期:{}".format(jobName, company, place, salary, postDate))
# print("******************************************************")
def excel_write(items,index):
for item in items:#职位信息
for i in range(0,5):
#print item[i]
ws.write(index,i,item[i])#行,列,数据
# print(index)
index += 1
newTable="51job.xls"#表格名称
wb = xlwt.Workbook(encoding='utf-8')#创建excel文件,声明编码
ws = wb.add_sheet('sheet1')#创建表格
headData = ['招聘职位','公司','地址','薪资','日期']#表头信息
for colnum in range(0, 5):
ws.write(0, colnum, headData[colnum], xlwt.easyxf('font: bold on')) # 行,列
for each in range(1,10):
index=(each-1)*50+1
excel_write(onePage,index)
wb.save(newTable)运行结果:

3 Beautiful Soup
3.1 创建 Beautiful Soup 对象并打印对象内容
import requests
from bs4 import BeautifulSoup as bs
html = requests.get("https://www.baidu.com").text
# print(html
soup = bs(html,"lxml") #html.parser/lxml/html5lib
#将html字符串数据美化输出
# print(soup.prettify())
print(soup.name)3.2 四大对象种类
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是 Python对象,所有对象可以归纳为4种:
- Tag
Tag:就是 HTML 中的一个个标签。 语法形式:soup.标签名 用来查找的是在所有内容中的第一个符合要求的标签 Tag 有两个属性,是 name 和 attrs。 soup 对象的 name 是输出的值便为标签本身的名称。 soup 对象的attrs是把标签的所有属性放在一个字典内
- NavigableString
获取标签内部的文字
soup.标签名.string - BeautifulSoup
- Comment
Comment 对象是一个特殊类型的 NavigableString 对象,其实输出的内容仍然不包 括注释符号
3.3常用方法
(1)find_all(name=None, attrs={}, recursive=True, text=None, limit=None, **kwargs) 搜索当前tag的所有tag子节点,并判断是否符合过滤器的条件
(2)find(name=None, attrs={}, recursive=True, text=None, **kwargs) 搜索当前tag的第一个tag子节点,并判断是否符合过滤器的条件
movieQuote = movieLi.find(‘span’, attrs={‘class’: ‘inq’})
(3)直接子节点:.contents .children属性
(4)所有子孙节点:.descendants属性
(5)获取文本:.string属性
(6)父节点:.parent .parents(迭代器)
(7)兄弟节点:.next_sibling .previous_sibling 加s同上
(8)下一个与上一个要解析的元素:.next_elements .previous_element
1)name 参数 name 参数可以查找所有名字为 name 的tag,字符串对象会被自动忽略掉
2)attrs 参数 注意:如果一个指定名字的参数不是搜索内置的参数名,搜索时会把该参数当作指定名字tag 的属性来搜索,如果包含一个名字为 id 的参数,Beautiful Soup会搜索每个tag的”id”属性
3)text 参数 通过 text 参数可以搜搜文档中的字符串内容.与 name 参数的可选值一样, text 参数接受 字 符串 , 正则表达式 , 列表, True
4)limit 参数 find_all() 方法返回全部的搜索结构,如果文档树很大那么搜索会很慢.如果我们不需要全部结 果,可以使用 limit 参数限制返回结果的数量.效果与SQL中的limit关键字类似,当搜索到的结果 数量达到 limit 的限制时,就停止搜索返回结果.
5)recursive 参数 调用tag的 find_all() 方法时,Beautiful Soup会检索当前tag的所有子孙节点,如果只想搜索 tag的直接子节点,可以使用参数 recursive=False .
代码实例
from bs4 import BeautifulSoup as bs
html = '''
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">jack</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Alice</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Mary</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
'''
soup = bs(html, "html.parser")
# print(soup.prettify())
# 获取Tag标签的属性
# print(soup.a["id"])
# print(soup.a.get("id"))
# print(soup.a.get("class"))
# 获取标签内的文字
# print(soup.a.string)
# print(soup.b.string)
# soup.find()只匹配第一个符合规则的Tag标签
# secondLink = soup.find("a",attrs={"class":"sister"})
# print(secondLink.string)
#soup.find_all()匹配所有符合规则的Tag标签
# links = soup.find_all("a",attrs={"class":"sister"})
# print(links[1].get("id"))
p = soup.find("p")
#在p标签内查找b标签
# b = p.find("b")
# print(b)
#获取父标签
# xTag = p.parent
# print(xTag.name)
#获取所有的父标签
for parent in p.parents:
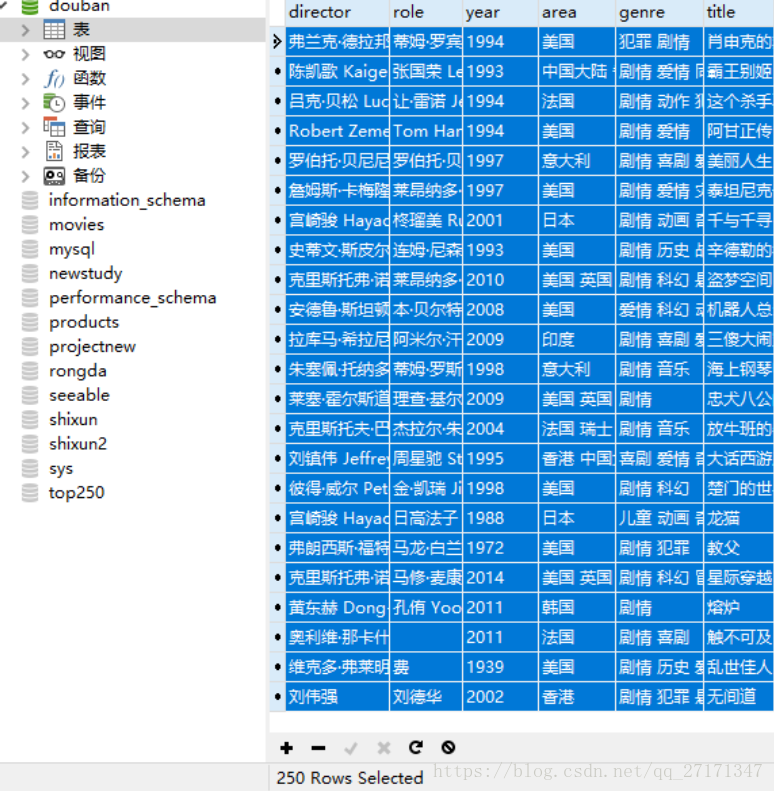
print(parent.name)爬虫案例 2
爬取豆瓣电影top250条电影数据,并存储进MySQL
import requests
from bs4 import BeautifulSoup as bs
import pymysql
movieInfos = [] # 用于保存所有的电影信息
baseUrl = 'https://movie.douban.com/top250?start={}&filter='
for startIndex in range(0, 226, 25):
url = baseUrl.format(startIndex)
# 爬取网页
r = requests.get(url)
# 获取html内容
htmlContent = r.text
# 用BeautifulSoup加载html文本内容进行处理
soup = bs(htmlContent, "lxml")
# 获取到页面中索引的class名为info的标签(应该有25个)
movieList = soup.find_all("div", attrs={"class": "info"})
# 遍历25条电影信息
for movieItem in movieList:
movieInfo = {} # 创建空字典,保存电影信息
# 获取到名为class名为hd的div标签内容
hd_div = movieItem.find("div", attrs={"class": "hd"})
# 通过bd_div获取到里面第一个span标签内容
hd_infos = hd_div.find("span").get_text().strip().split("\n")
# < span class ="title" > 天堂电影院 < / span >
movieInfo['title'] = hd_infos[0]
# 获取到class名为bd的div标签内容
bd_div = movieItem.find("div", attrs={"class": "bd"})
# print(bd_div)
# 通过bd_div获取到里面第一个p标签内容
infos = bd_div.find("p").get_text().strip().split("\n")
# print(infos) #包含了两行电影信息的列表
# 获取导演和主演
infos_1 = infos[0].split("\xa0\xa0\xa0")
if len(infos_1) == 2:
# 获取导演,只获取排在第一位的导演名字
director = infos_1[0][4:].rstrip("...").split("/")[0]
movieInfo['director'] = director
# 获取主演
role = infos_1[1][4:].rstrip("...").rstrip("/").split("/")[0]
movieInfo['role'] = role
else:
movieInfo['director'] = None
movieInfo['role'] = None
# 获取上映的时间/地区/电影类型
infos_2 = infos[1].lstrip().split("\xa0/\xa0")
# 获取上映时间
year = infos_2[0]
movieInfo['year'] = year
# 获取电影地区
area = infos_2[1]
movieInfo['area'] = area
# 获取类型
genre = infos_2[2]
movieInfo['genre'] = genre
print(movieInfo)
movieInfos.append(movieInfo)
conn = pymysql.connect(host='localhost', user='root', passwd='DevilKing27', db='douban',charset="utf8")
# 获取游标对象
cursor = conn.cursor()
# 查看结果
print('添加了{}条数据'.format(cursor.rowcount))
for movietiem in movieInfos:
director = movietiem['director']
role = movietiem['role']
year = movietiem['year']
area = movietiem['area']
genre = movietiem['genre']
title = movietiem['title']
sql = 'INSERT INTO top250 values("%s","%s","%s","%s","%s","%s")' % (director, role, year, area, genre, title)
# 执行sql
cursor.execute(sql)
# 提交
conn.commit()
print('添加了{}条数据'.format(cursor.rowcount))
结果: