HashMap 和 Hashtabl 都是 Map 接口的实现类,存储的是 Key - value 对。
相同点
1. 它们都是存储键值对(key - value)的散列表,而且都是采用链地址法 实现的。
存储思想:通过 table 数组存储,table 数组是 Entry 类型的,每个table 数组最终都存储的是一个单向链表,链表中的每个节点都存储的键值对(key - value)。
2. 添加键值对:通过 key 计算出哈希值,再计算出数组的索引,根据索引去遍历单链表,如果链表中已经存在这个key 值,则覆盖原来的value,否则,加入新的节点。
3. 删除键值对: 通过 key 计算出哈希值,再计算出数组的索引,根据索引去遍历单链表,从单链表中删除这个键值对。
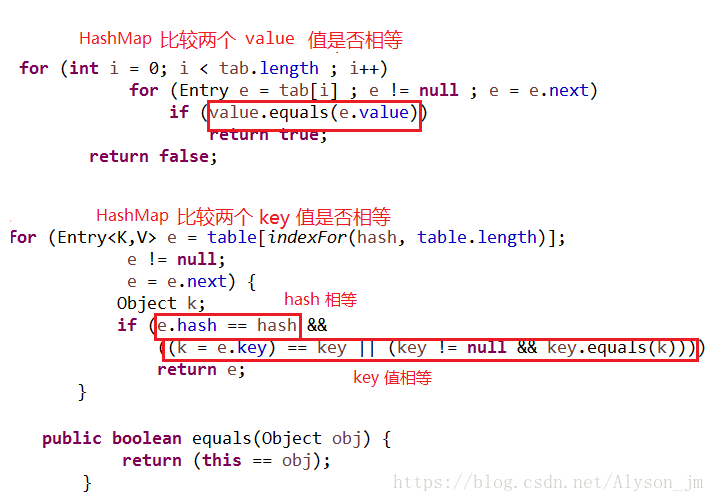
HashMap 和 HashTable 判断两个 key 和 value 相等的标准相同。

不同点
1. 继承的父类不同,实现的接口也不全相同 。
HashMap 定义
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, SerializableHashtable 定义
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable Dictionary 是一个抽象类,直接继承自 Object 类,Dictionary 一般是通过 Enumeration(枚举类)去遍历,Hashtable 还实现了Map 接口, 所以 Hashtable 也可以通过 Iterator 去遍历,HashMap 只支持迭代器遍历。
2. 默认的初始容量不同,HashMap 为 16,Hashtable 为 11
HashMap 初始容量
/**
* 默认容量
*/
static final int DEFAULT_INITIAL_CAPACITY = 16;Hashtable 初始容量
public Hashtable() {
this(11, 0.75f);
}3. 扩容方式不同
HashMap 二倍扩容
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length); //扩容
}
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];//新的容量,此处为2 * table.length
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
Hashtable 二倍 加 1
protected void rehash() {
int oldCapacity = table.length;
Entry[] oldMap = table;
int newCapacity = oldCapacity * 2 + 1;//扩容,原来的2倍加1
Entry[] newMap = new Entry[newCapacity];
modCount++;
threshold = (int)(newCapacity * loadFactor);
table = newMap;
4. Hashtable 是线程安全的,HashMap 不是线程安全的
Hashtable 大部分函数都是同步的,支持多线程。
HashMap 函数不同步,它是线程不安全的。
5. HashMap 允许 key 和 value 为空,Hashtable 允许 key 为空。
HashMap
public V put(K key, V value) {
//当 key 为 null
if (key == null)
return putForNullKey(value);
//得到 hash 值
int hash = hash(key.hashCode());
//获得索引
int i = indexFor(hash, table.length);
//遍历索引位置的链表
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//如果链表中已经存在当前的key,覆盖即可
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//如果当前链表没有就增加这个键值对到集合中
addEntry(hash, key, value, i);
return null;
}Hashtable
public synchronized V put(K key, V value) {
//确保 value 不为空,value 为空时抛异常
if (value == null) {
throw new NullPointerException();
}
Entry tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
V old = e.value;
e.value = value;
return old;
}
}
modCount++;
if (count >= threshold)
rehash();
tab = table;
index = (hash & 0x7FFFFFFF) % tab.length;
}从上面的代码可以看出来,HashMap 中的 key 可以为 null,当 key 为 null 时,将key 放在 0 号位置,Hashtable 中 key 和 value 都不能为null,否则会抛异常。
6. HashMap 和 Hashtable 的 hash 处理不同
HashMap
//得到 hash 值
int hash = hash(key.hashCode());Hashtable
//得到 hash 值
int hash = key.hashCode();HashMap 是采用自定的哈希算法,Hashtable 采用 key 的 hashCode 算法
7. 迭代的方式不同
HashMap是“从前向后”的遍历数组;再对数组具体某一项对应的链表,从表头开始进行遍历。
Hashtabl是“从后往前”的遍历数组;再对数组具体某一项对应的链表,从表头开始进行遍历。