关于C/C++ stdin缓冲区以及对字符输入的一些经验和心得
在使用C/C++编写控制台应用或acm竞赛的时候,I/O方式无非是标准输入输出,特别是acm竞赛,就本人来说,由C语言入门,输入方式还只会scanf,自从学了C++,便深深地被 cin/cout输入输出流的简洁用法所吸引,相信有这种感觉的不止我一个人。
所以很长一段时间,日常的训练和各种线上比赛,再也没有使用过scanf,反手一个cin感觉很炫酷。然而好景不长,一次bestcoder的常规线上赛,前期发挥稳定,手感相当好,1001和1002快而准地ac,1003也很快来了思路(两年前的事情了,细节什么的早忘了),咔咔咔敲完代码提交ac,最后剩下充足的时间攻克1004,虽然到结束也没做出来,但是3题铁定涨分啊……
然而终判的结果让我大吃一鲸,T!L!E!,居然超时,百思不得其解之时(其实之前知道cin效率低,但是用着太顺手了就没在意),想到了会不会是数据太多?然后等着终判结束题目开放,抱着试一试的心态,把cin改成了scanf,然后……居然……秒过……
然后网上查阅资料(只说输入,输出大同小异),cin慢的原因很多,其中很重要的一点是为了使cin与scanf可以兼容混合使用,cin在内部实现的时候会同步输入缓冲区,也就是说,输入流会时刻与输入缓冲保持同步,这是一个很耗时的操作,所以就导致了在大量输入数据的时候,cin会比scanf慢很多,可以说,这个慢,是数量级上的差异。
如果你可以保证程序中不会出现标准输入与流输入混用的情况,可以在程序开始时使用ios::sync_with_stdio(false);关闭同步来提高速度,但是在大量数据面前输入速度仍显得乏力,相比scanf还是慢了一些(上面说的1003题我用cin关同步还是超时,只有scanf能过),个人认为原因在于对输入流对象的封装和>>这个符号的运算符重载导致执行时间变慢。
所以从那以后,在acm生涯里再也没有使用过cin……硬生生地改回了scanf的习惯。简洁和效率总要舍弃一个,对于算法竞赛来说,效率才是关键吧……
说了这么多cin与scanf的速度比较,接下来重点说一下scanf,用法不必多说,结合多年来竞赛经验,介绍一下格式符%c与其他格式符的区别和特定使用场景的注意事项。
%c是一个很奇葩的设定,单独读入一个字符,包括不可见的控制字符(换行等),而其他格式化符号(如%d %lld %f %lf %s等)会在读入未完成时将换行符、空格、制表符等空白字符统统舍弃忽略,直到读到了足够的数据或遇到文件结尾才结束。我们平时控制台输入时通常按行输入,也就是输入数据后要敲击回车才能被读取,这样就导致了换行符在%c与其他格式符号并存的程序中出现各种问题,例如无法获得理想输入数据,字符串错误错误导致程序崩溃等。
例如下面这段程序片段:
int a,b;
char c;
scanf("%d %d", &a, &b);
printf("a=%d b=%d\n", a, b);
scanf("%c", &c);
printf("char=%c\n", c);- 1
- 2
- 3
- 4
- 5
- 6
理想状态下,我们输入以下数据:
11 66
a- 1
- 2
输出结果应该与输入一致,也就是说输入11 66后敲下回车紧接着就会出现a=11 b=66,然后再输入a敲回车会出现char=a。但事实上输入11 66敲回车得到a=11 b=66以后,并不会再等待输入字符,而是在出现char=和一个空行之后,直接结束,如下图:
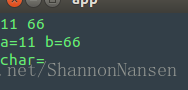
为什么会出现这种情况?我们先来想两个问题,为什么程序在遇到scanf等输入操作的时候,会停在那里发生阻塞?为什么我们输入完成后,还要敲一下回车才能有反应?
为什么发生阻塞?
简单点说,程序在scanf处发生了I/O请求,需要数据,而scanf需要从输入缓冲区读取数据,程序刚运行的时候,这个缓冲区是空的,所以scanf得不到数据,就会阻塞程序,一直等待缓冲区内出现数据,此时我们从控制台输入内容,敲下回车,输入的内容便会传送给程序输入缓冲区,被scanf阻塞的程序发现缓冲区里有内容了,就会让scanf继续执行,读入数据。
为什么要敲回车?
默认情况下,我们在控制台的输入内容是不会立刻同步到缓冲区的,也许是为了防止误输入或效率问题,只有敲下回车的时候,输入内容连同换行符才会被一起传送至缓冲区,但实际上,被传送至缓冲区的换行符通常是我们所不需要的,它只是我们从控制台输入内容时所要按下的一个键而已,并不是我们需要的数据。
当缓冲区内有了数据,scanf便开始按照设定的格式进行读取,除%c格式符以外,scanf会按照格式里的内容从左至右读取指定格式的数据。
我们回看之前的例子,单步解读程序,格式内容"%d %d",我们输入11 66敲回车后,输入缓冲区内容变为11 66\n(用\n代表换行符),scanf先尝试读取格式内容里的第一个%d,也就是读整数,从缓冲区里成功读到了11,此时缓冲区剩下66\n(注意开头有个空格),然后尝试读取第二个%d,由于此时缓冲区开头的内容是空格,%d不理睬 ,忽略开头若干空白字符,然后遇到66,成功读入,此时scanf没有别的要读的了,结束,函数返回2(读入的数量),此时缓冲区剩余\n,然后程序执行printf,再执行scanf("%c", &c);,由于此时缓冲区有内容\n,所以不阻塞,直接读取,开头说到%c会读取一切字符,所以换行符自然而然被读到了 ,所以变量c的内容是'\n',带入printf("char=%c\n", c);,就可以明白为什么会出现图示的现象了。
如何解决?方案就是在每次使用scanf之后,调用fflush(stdin);来清空输入缓冲区(也就是清掉那个恼人的换行符),然而这样做很麻烦并且几乎所有oj都拒绝这种危险的操作,所以一般使用getchar();来消除换行符(实际就是读入但不赋值给变量)。
getchar()与scanf("%c")一样,可以读入任意字符,所以我们每次要使用scanf("%c")时,不妨先检查在此之前是否有其他的输入行,如果有的话,记得在这两次输入之间加上getchar()来抵消敲击回车所产生的换行符。上例,修改后如下:
int a,b;
char c;
scanf("%d %d", &a, &b);
printf("a=%d b=%d\n", a, b);
getchar();
scanf("%c", &c);
printf("char=%c\n", c);- 1
- 2
- 3
- 4
- 5
- 6
- 7
运行,我们依次输入11 66,敲回车,输入a,敲回车,结果如下:
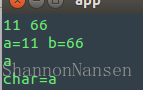
这下就正常了。
下面是一个典型的输入场景:
矩阵类字符输入
描述: 第一行输入两个整数n,m,接着n行,每行m个字符
样例:
2 3
abc
def- 1
- 2
- 3
分析:
我们先不考虑怎么一步步输的,假设把整个输入内容送到缓冲区,然后我们缓冲区内的字符序列是这样的:
2 3\nabc\ndef\n,观察这个序列,a,d前面都有换行,所以读取这两个字符时,换行会产生干扰,当然最后一个换行程序都快结束了留着也没什么卵用,所以我们需要抵消三个换行,分别在输完2 3以后和每行的字符输完以后。
实现1:
char a[10][10];
int n,m;
scanf("%d %d", &n, &m);
getchar(); // 接下来要读字符,而这里产生了额外的换行,吃掉
for(int i = 0 ; i < n ; i++)
{
for(int j = 0 ; j < m ; j++)
{
scanf("%c", &a[i][j]);
}
getchar(); // 读完了m个字符,也就是一行,产生了一个换行符,而接下来的外层循环要读下一行的字符,所以要吃掉它
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
实现2(输入不包含空格):
如果题目明确表示或暗示输入字符不包含空格,可以将每行字符作为一个不含空格的字符串输入,也就是使用scanf(“%s”),这样我们就不用考虑换行符的抵消问题了,因为前面说过,除了%c,其他格式符号都不会care换行符。
下面实现的前提是字符中不包含空格
char a[10][10];
int n,m;
scanf("%d %d", &n, &m);
for(int i = 0 ; i < n ; i++)
{
scanf("%s", a[i]);
// 这样相当于直接将abc按照顺序依次存入a[0][0],[0][1],[0][2],并自动在a[0][3]加入字符串结束标志'\0',方便调试。
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
实现3(包含空格但不想用scanf):
如果觉得
scanf太麻烦,而且输入的字符的确包含空格,那么可以用gets()函数,不过这个函数由于在设计时存在缓冲区溢出漏洞,C++标准里并不推荐使用,但是日常训练和竞赛只要稍加注意并不会出现溢出问题(只要字符数组够大就没事),所以这个函数也是很好用的。gets()函数会读入一行字符,它会一直读输入缓冲区内的字符序列直到遇到了'\n'才会停止,值得注意的是,gets()以换行符为界,并不会把换行符作为输入的一部分而读进字符串,但会消耗掉换行符,这点与scanf有所不同。
例如输入缓冲区内容为abc def gh 666\n233,gets函数从该缓冲区读取到的内容为abc def gh 666,而缓冲区剩余233,'\n'为gets函数做“路标”但惨遭gets函数“抛弃”。当然,如果缓冲区第一个字符就是换行符,则gets会读入一个空字符串并消耗掉缓冲区的这个换行符。上例代码:
char a[10][10];
int n,m;
scanf("%d %d", &n, &m);
getchar(); // 此时缓冲区第一个字符是换行符,不消除的话下一个gets会读到空字符串
for(int i = 0 ; i < n ; i++)
{
gets(a[i]);
// 这里不需要为下一次循环的gets做换行抵消,因为gets本身就会在本行输入结束时抵消换行符
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
总结来说,了解了缓冲区的作用和各种输入对于控制符的处理,再处理起字符类输入问题就得心应手了,acm生涯里不乏遇到各种姿势的变态输入格式,有的时候数据输入完了再输出来就变得不一样了,还有的时候输入数据复杂到整个题目的时间都用在了研究输入上,所以掌握好基本的数据输入才是ac的第一步。
今天做一道ACM题,数据比较大,刚开始用的cin,cout,
发现超时了,翻来覆去想不懂,于是找度娘,结果发现思路
都差不多,怎么别人能AC,我的就TLE呢?
比对来比对去只有输入输出上有差别,我用的cin,人家用的scanf,
之前,也知道cin,cout和scanf,printf速度上有差距,但应该不至于这么大吧?
结果,改过来发现AC了,内牛满面啊。
本来超时的,改一下输入输出就变成2437MS。
于是,想找一找速度差距到底有多少,马上就搜到了经过牛人测试的文章:
http://hi.baidu.com/i5love1you9/item/2b97cb3dd91f20b7134b14c5
总结下来就是:
①scanf至少要比cin快一倍左右
②cin慢的原因:默认情况,cin与stdin总是保持同步的,也就是说这两种方法可以混用,而不必担心文件指针混乱,同时cout和stdout也一样,两者混用不会输出顺序错乱。正因为这个兼容性的特性,导致cin有许多额外的开销。(解决:只需一个语句std::ios::sync_with_stdio(false);,这样就可以取消cin于stdin的同步了,此时的cin就与scanf差不多了)
③cin、cout是在编译期间就决定了读入变量的类型。而scanf()是在运行期决定的,编译器无法优化,而且还要识别字符串。理论上scanf比cin要慢很多,实际上快的原因是很多编译器对cin、cout的处理过于保守。
④同牛人建议,Acmer 尽量用scanf,printf来进行输入输出吧....
很早就知道,c的scanf(printf)比c++的快。刷题时尤其明显,在这上面超时是常有的事儿。
但,这是别人告诉我的,c快。
为什么快?
从网上借鉴一个例子做个简单测试:
1.cpp //向一个文件里输入1000000个随机数
#include<iostream>
#include<fstream>
#include<cstdlib>
using namespace std;
const int num=1000000;
int main()
{
ofstream file("data");
for(int i=0;i<num;i++)
{
file<<rand()<<' ';
if((i+1)%20==0)
file<<endl;
}
return 0;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
2.cpp //用cin读取这1000000个随机数
#include<iostream>
#include<ctime>
#include<cstdio>
#include<windows.h>
using namespace std;
const int num=1000000;
int main()
{
freopen("data","r",stdin);
int i,n,start,end;
start=clock();
for(i=0;i<num-2;i++)
cin>>n;
end=clock();
cout<<double(end-start)/CLOCKS_PER_SEC<<endl;
Sleep(5000);
system("pause");
return 0;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
结果: 耗时 5.281秒
3.cpp //用scanf读取这1000000个数
#include<ctime>
#include<cstdio>
#include<stdlib.h>
#include<windows.h>
#include<iostream>
using namespace std;
const int num=1000000;
int main()
{
freopen("data","r",stdin);
int i,n,start,end;
start=clock();
for(i=0;i<num;i++)
scanf("%d",&n);
end=clock();
//cout<<double(end-start)/CLOCKS_PER_SEC<<endl;
printf("%f\n",double(end-start)/CLOCKS_PER_SEC);
system("pause");
Sleep(5000);
return 0;
} - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
结果: 耗时 0.437秒
结论:scanf真的比cin快。竟快10倍。
运行环境,xp,DEV-C++。
比较合理的解释:默认情况,cin与stdin总是保持同步的,也就是说这两种方法可以混用,而不必担心文件指针混乱,同时cout和stdout也一样,两者混用不会输 出顺序错乱。正因为这个兼容性的特性,导致cin有许多额外的开销,如何禁用这个特性呢?只需一个语句 std::iOS::sync_with_stdio(false);,这样就可以取消cin于stdin的同步了,此时的cin就与scanf差不多 了。
另一种解释: cout在输出时总是要先将输出的存入缓存区。而printf直接调用系统进行IO,它是非缓存的。所以cout比printf慢。(这种解释,我没有验证)
补充1:
[待验证]
在g++中,cout通常比printf的性能高。
影响cout的性能通常有两个因素,一是某些实现例如VS用printf实现cout,当然printf比cout快;二是iostream默认情况下是与stdio关联在一起的,就是cout在运行时,会刷新stdio,这个操作会拖慢cout的性能。但g++的cout并不是用printf实现的,即使不去掉与stdio的关联,cout已经比printf要快,在我的三星7寸笔记本中,通常要快三分一左右,如果通过std::ios_base::sync_with_stdio( false )去掉与stdio的关联,甚至比printf快几乎十倍。
补充2:
流输入输出的有点:
1.流输入输出对于基本类型来说使用很方便,不用手写格式控制字符串。
2.对于标准库的一些class来说,显然重载操作符也比自己写格式控制字符串要方便很多。
3.对于复杂的格式可以进行自定义操作符。
4.可读性更好(这个很多人有不同意见,见仁见智了)。
其实原理上来说:流操作的效率比printf/scanf函数族更高,因为是在编译期确定操作数类型和调用的输出函数,不用在运行期解析格式控制字符串带来额外开销。不过标准流对象cin/cout为了普适性,继承体系很复杂,所以在对象的构造等方面会影响效率,因此总体效率比较低。如果根据特定的场景进行优化,效率可以更高一点。