本博文系转载
https://blog.csdn.net/yhily2008/article/details/80272245
一、概述
TensorFlow最基本的一次计算流程通常是这样的:首先它接受n个固定格式的数据输入,通过特定的函数,将其转化为n个张量(Tensor)格式的输出。
一般来说,某次计算的输出很可能是下一次计算的(全部或部分)输入。整个计算过程其实是一个个Tensor 数据的流动过程。在这其中,TensorFlow将这一系列的计算流程抽象为了一张数据流图(Data Flow Graph)。简单来说,数据流图,就是在逻辑上描述一次机器学习计算的过程。下面我们以图11-26为例,来说明TensorFlow的几个重要概念。
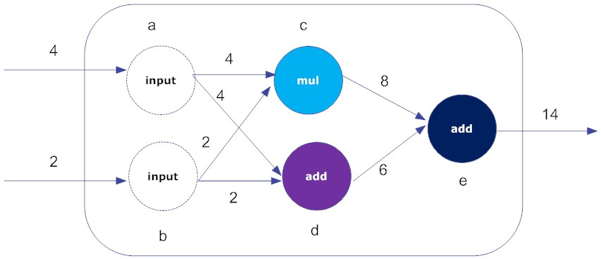
图11-26 TensorFlow的数据流图
构建数据流图时,需要两个基础元素:点(node)和边(edge)。
• 节点:在数据流图中,节点通常以圆、椭圆或方框表示,代表对数据的运算或某种操作。例如,在图11-26中,就有5个节点,分别表示输入(input)、乘法(mul)和加法(add)。
• 边:数据流图是一种有向图,“边”通常用带箭头线段表示,实际上,它是节点之间的连接。指向节点的边表示输入,从节点引出的边表示输出。输入可以是来自其他数据流图,也可以表示文件读取、用户输入。输出就是某个节点的“操作(Operation,下文简称Op)”结果。在图11-26中的例子中,节点c接受两个边的输入(2和4),输出乘法的(mul)结果8。
在本质上,TensorFlow的数据流图就是一系列链接在一起的函数构成,每个函数都会输出若干个值(0个或多个),以供其它函数使用。在图11-26中,a和b是两个输入节点(input)。这类节点并非可有可无,它的作用是传递输入值,并隐藏重复使用的细节,从而可对输入操作进行抽象描述。
除了上述两个概念之外,下面3个概念也很重要,在后面的章节会详细介绍,这里仅做简单介绍。
(1)Session(会话):根据上下文(context),会话负责管理协调整个数据流图的计算过程。光有数据流图还不够,如果想执行数据流图所描述的计算,还得配备一个专门的会话,来负责图计算。
(2)Op(操作):就是数据流图中的一个节点,代表一次基本的操作过程。
(3)Tensor(张量):在TensorFlow 中,所有计算数据的格式,都是一个n维数组,如 t = [[1, 2, 3], [4, 5, 6], [7, 8, 9]],就是一个2维张量。
二、构建第一个TensorFlow数据流
通过前面的介绍,下面我们就可以构建一个与图11-26相匹配的数据流程图,具体代码如下所示:
【范例11-1】TensorFlow数据流图(feed_dict.py)
-
import tensorflow as tf -
a = tf.constant(4, name = "input_a") -
b = tf.constant(2, name = "input_b") -
c = tf.multiply(a,b, name ="mul_c") -
d = tf.add(a,b, name = "add_d") -
e = tf.add(c,d, name = "add_e") -
sess = tf.Session() -
print(sess.run(e)) -
sess.close()
在Jupyter Notebook按Shift + Enter键,结果如图11-27所示。

图11-27 数据流程图计算结果
整体来说,TensorFlow的程序由两大部分构成:
(1) 构建计算流图(如范例11-1的第03~07行)。
(2)运行计算流图(如范例11-1的第09~11行)。
下面我们来详细解析上述代码。
第01行代码是Python的经典用法,它的作用是导入TensorFlow库,并给它取一个简短的别名tf,方便后面引用。
第03和04行代码定义了两个输入节点a和b,在TensorFlow中,它要以数据流图的形式完成计算,所以不能像Python一样直接赋值。比如a = 4或b = 2,在TensorFlow计算中都是错误的,必须通过一个“操作(Operation,简称Op)”,使其变成一个数据流图的节点。tf.constant( )就是要创建一个常量Op,constant( )函数本身有多个参数,其函数原型如下:
-
constant( -
value, -
dtype=None, -
shape=None, -
name='Const', -
verify_shape=False -
)
第1个参数是常量数值(value),第2个参数是数据类型(dtype),指定返回张量的数据类型。第3个参数shape是可选项,表明设置张量的形状(即张量的维度),第4个参数是name,是可选项,用于指定这个操作(Op)的名称,默认值为“Const”,在本范例代码中,我们给出特定的名称,这是为在后期绘制流程图方便。第5个参数是一个布尔值,它表明是否要验证张量形状,默认值为“False”,不验证。这5个参数除了第一个参数外,都有默认值,用户可以根据自己的需要指定第2~5个参数的值。
第05行代码实施乘法操作。与前面介绍的类似,在TensorFlow中,乘法也是一个标准的Op,multiply()函数原型为:
-
multiply( -
x, -
y, -
name=None -
)
在参数中,x和y都是两个标准的张量(可以是下列类型的任何一种,half, float32, float64, uint8, int8, uint16, int16, int32, int64, complex64, complex128),返回值是x*y的值,对这个Op也可以取一个名称name,默认值是“None”。在本范例中,我们取名为mul_c。
这里需要说明一点的是,在TensorFlow 1.0(2017年2月发布)以后,tf.mul,(乘法)、tf.sub(减法)和tf.neg(取负值)等API都已过时,分别被tf.multiply, tf.subtract 和tf.negative取代。
由于TensorFlow的社区非常活跃,用户提交了很多有价值的代码,因此它的版本迭代速度非常快,“不是我不明白,是你变化太快”,所以如果读者朋友在看到本书时,发现部分API过时了,版本号不是最新的,无需惊讶,因为这就是TensorFlow的调性。对于此类情况,多多查看TensorFlow的官方文档。(https://www.tensorflow.org/api_guides/python/),把握最新动态,才是正道。
第06~07行,表明加法操作,add( )函数的原型为:
-
add( -
x, -
y, -
name=None -
)
参数的含义和乘法类似,这里不再赘述。
当整个数据流图构建完毕后,虽然它在语法上不报错,但TensorFlow并不会实质性地去执行数据流图描述的计算。这是因为,我们还需要给这个数据流图添加一个会话(Session)。
第09行,就是定义一个会话。Session可理解为数据流图的运行环境。
第10行就是把数据流图的终点e作为会话运行run( )的参数,然后利用print打印run()的返回值。
由于开启一个会话,可能会耗费部分系统资源,一个良好的编程习惯就是用完一个会话之后,要关闭它,第11行干的就是这个工作。
当然,我们可以利用“with”上下文管理器在用完之后,自动关闭它,第09~11行代码可变更为:
-
with tf.Session() as sess: -
print(sess.run(e))
现在我们总结一下TensorFlow的工作流程,实际上它体现出来的是一个“惰性”方法论。
(1)构建一个计算图。图中的节点可以是TensorFlow支持的任何数学操作。
(2)初始化变量。将前期定义的变量赋初值。
(3)创建一个会话。这才是图计算开始的地方,也是体现它“惰性”的地方,也就是说,仅仅构建一个图,这些图不会自动执行计算操作,而是还要显式提交到一个会话去执行,也就是说,它的执行,是滞后的。
(4)在会话中运行图的计算。把编译通过的合法计算流图传递给会话,这时张量(tensor)才真正“流动(flow)”起来。
(5)关闭会话。当整个图无需再计算时,则关闭会话,以回收系统资源。
节选自 张玉宏《深度学习之美》部分章节,电子工业出版社,博文视点,2018年6月出版
To be continued~~~