首先这个项目如题所示把CSDN博客做成app,主要是通过Jsoup网络爬虫的方法获取网页数据,并不是通过get、put那样的接口,因为CSDN博客网站的网页结构比较稳定,所以适合使用爬虫技术做成app。
1.app界面
输入博客地址界面
浏览博客文章目录,附带回到顶部按钮

浏览博客详情,附带返回按钮

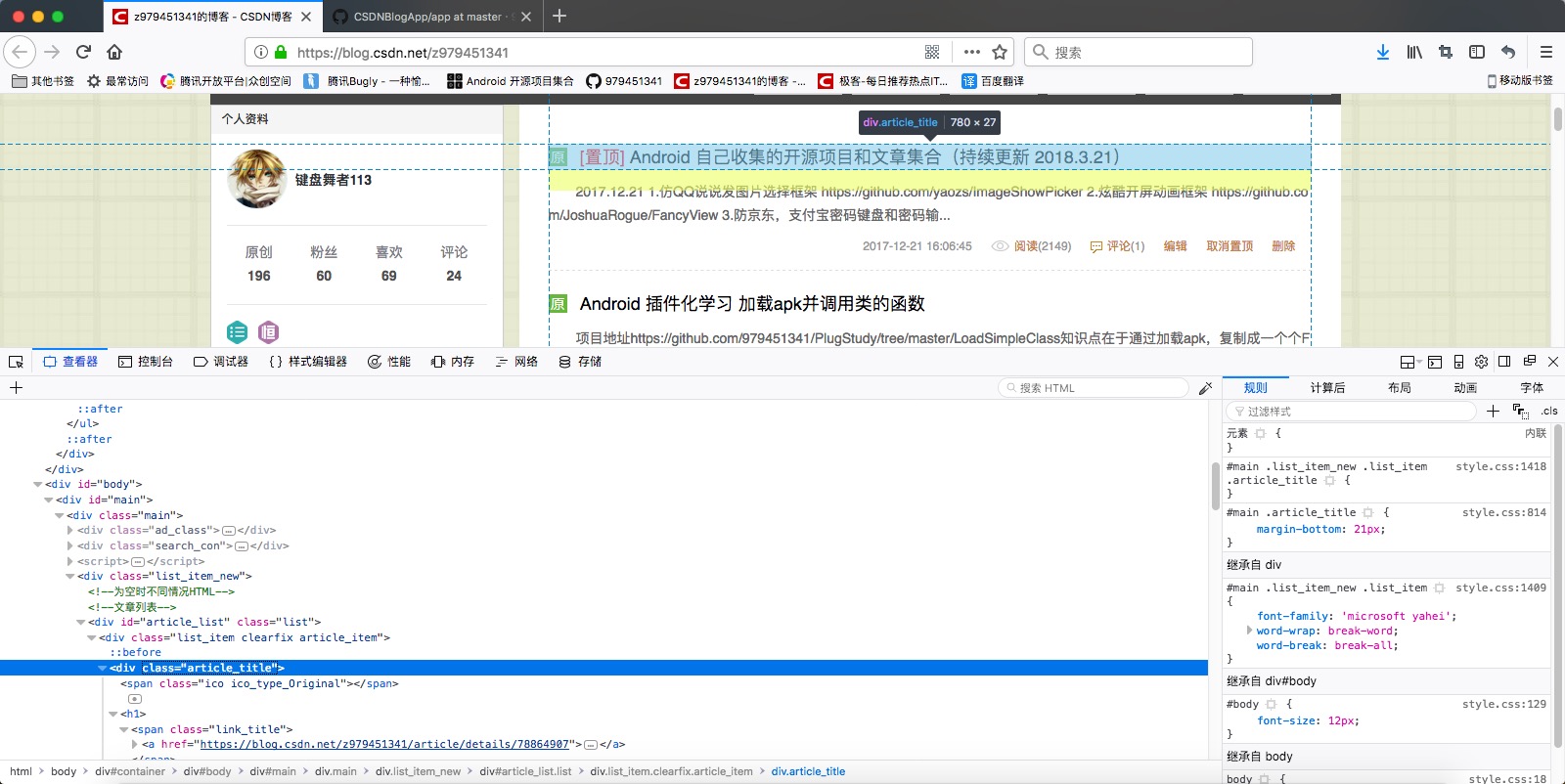
2.实现核心,主要使用Jsoup框架一层一层的剥落网页层次,直到剩下博客标题列表
public class BlogTitleThread extends Thread {
private ArrayList<BlogTitleBean> dataList = new ArrayList<>();
private Handler handler;
public int page;
public BlogTitleThread(Handler handler, int page){
super();
this.handler = handler;
this.page = page;
}
@Override
public void run() {
dataList.clear();
String url = Constants.blog_address+Constants.article+page;
Connection conn = Jsoup.connect(url);
// 修改http包中的header,伪装成浏览器进行抓取
conn.header("User-Agent", "Mozilla/5.0 (X11; Linux x86_64; rv:32.0) Gecko/ 20170929 Firefox/32.0");
Document doc = null;
try {
doc = conn.get();
} catch (IOException e) {
e.printStackTrace();
}
Element body = doc.body();
Element container = body.getElementById("mainBox");
Element cMain = container.tagName("main");
Document doccMain = Jsoup.parse(cMain.toString());
Elements list_item_new = doccMain.getElementsByClass("article-list");
String old = "";
for (Element item : list_item_new) {
Elements links = item.getElementsByTag("a");
for (Element link : links) {
String linkHref = link.attr("href");
String linkText = link.text();
if (TextUtils.isEmpty(linkHref) || TextUtils.isEmpty(linkText)) {
continue;
}
BlogTitleBean bean = new BlogTitleBean();
bean.setTitle(linkText);
bean.setUrl(linkHref);
dataList.add(bean);
}
}
Message message = handler.obtainMessage();
message.what = MainActivity.msg_blog_title;
Bundle bundle = new Bundle();
bundle.putParcelableArrayList(MainActivity.bundle_blog_title, dataList );
message.setData(bundle);
handler.sendMessage(message);
}
}