最近需要一些车辆的图片,找了一些和车辆有关的网站,找来找去还是这个网站还不错。
http://www.xcar.com.cn/做的很用心了感谢~
最开始设计程序就像网上给的那样,想要修改网址,就在代码上直接改,可是做着做着发现,容易出错,所以考虑做一款GUI的爬虫程序。
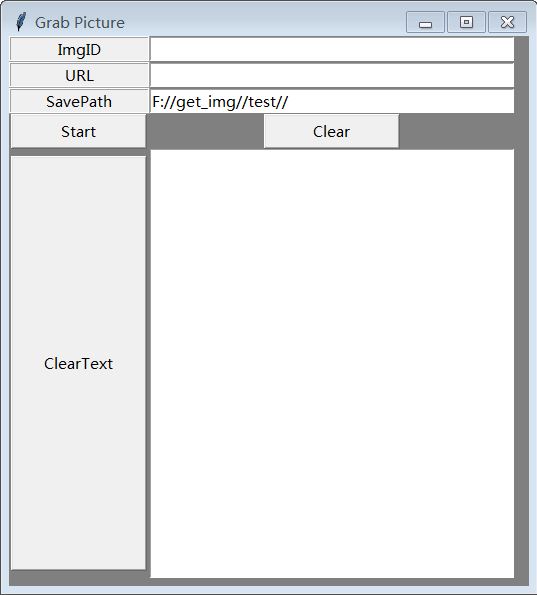
这里的ImgID就是汽车的类型号
URL就是网址
最下面的就是保存的路径
其实整个GUI的代码很简单,基本上涉及很浅的Tkinter知识,也没有多线程,所以这是最大的缺陷了,爬多了就会卡死,可能我以后有时间再做多线程吧,最近事太多。
entryVar1 = StringVar()
entry1 = Entry(window, textvariable=entryVar1, width=40)
entry1.grid(row=0, column=1)
entryVar2 = StringVar()
entry2 = Entry(window, textvariable=entryVar2, width=40)
entry2.grid(row=1, column=1)
text_result = Text(window, width=40, height=25)
text_result.grid(row=4, column=1)
entryVar3 = StringVar()
entry3 = Entry(window, textvariable=entryVar3, width=40)
entry3.grid(row=2, column=1)
entryVar3.set('F://get_img//test//')这是定义的文本框和label。默认的保存到F://get_img//test//ImgID下
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html.decode('GBK')
def getImg(html):
reg = r'src="(.+?\.jpg)" width="?"'
imgre = re.compile(reg)
imglist = imgre.findall(html)
x = 0
m_path = str(entryVar3.get()) + str(entryVar1.get())
if not os.path.isdir(m_path):
os.makedirs(m_path)
m_paths = m_path + '//'
for imgurl in imglist:
picName = '{0}' + str(entryVar1.get()) + '_{1}.jpg'
urllib.request.urlretrieve(imgurl, picName.format(m_paths, x))
x = x + 1
# result='Downloading The ' + str(x) + ' of ' + str(entryVar1.get()) + ' Car'
# print(result)
return imglist
def hitMe():
html = getHtml(str(entryVar2.get()))
(getImg(html))
# print('The'+str(entryVar1.get())+'Mission is over!')
m_result = 'The ' + str(entryVar1.get()) + ' Mission is over!'
text_result.insert(1.0, m_result + '\n')
def hitClear():
# entryVar1.set('')
entryVar2.set('')
def hitClearText():
text_result.delete(1.0, END)这是定义的子函数,整体来说还是挺省事的,比之前的操作更快更简洁友好。
完整的代码我已经放在Github上Grab_Images