journal
journal 是 MongoDB 存储引擎层的概念,目前 MongoDB主要支持 mmapv1、wiredtiger、mongorocks 等存储引擎,都支持配置journal。
MongoDB 所有的数据写入、读取最终都是调存储引擎层的接口来存储、读取数据,journal 是存储引擎存储数据时的一种辅助机制。
以wiredtiger 为例,如果不配置 journal,写入 wiredtiger 的数据,并不会立即持久化存储;而是每分钟会做一次全量的checkpoint(storage.syncPeriodSecs配置项,默认为1分钟),将所有的数据持久化。如果中间出现宕机,那么数据只能恢复到最近的一次checkpoint,这样最多可能丢掉1分钟的数据。
所以建议「一定要开启journal」,开启 journal 后,每次写入会记录一条操作日志(通过journal可以重新构造出写入的数据)。这样即使出现宕机,启动时 Wiredtiger 会先将数据恢复到最近的一次checkpoint的点,然后重放后续的 journal 操作日志来恢复数据。
MongoDB 里的 journal 行为 主要由2个参数控制,storage.journal.enabled 决定是否开启journal,storage.journal.commitInternalMs 决定 journal 刷盘的间隔,默认为100ms,用户也可以通过写入时指定 writeConcern 为 {j: ture} 来每次写入时都确保 journal 刷盘。
oplog
oplog 是 MongoDB 主从复制层面的一个概念,通过 oplog 来实现复制集节点间数据同步,客户端将数据写入到 Primary,Primary 写入数据后会记录一条 oplog,Secondary 从 Primary(或其他 Secondary )拉取 oplog 并重放,来确保复制集里每个节点存储相同的数据。
oplog 在 MongoDB 里是一个普通的 capped collection,对于存储引擎来说,oplog只是一部分普通的数据而已。
MongoDB 的一次写入
MongoDB 复制集里写入一个文档时,需要修改如下数据
- 将文档数据写入对应的集合
- 更新集合的所有索引信息
- 写入一条oplog用于同步
上面3个修改操作,需要确保要么都成功,要么都失败,不能出现部分成功的情况,否则
- 如果数据写入成功,但索引写入失败,那么会出现某个数据,通过全表扫描能读取到,但通过索引就无法读取
- 如果数据、索引都写入成功,但 oplog 写入不成功,那么写入操作就不能正常的同步到备节点,出现主备数据不一致的情况
MongoDB 在写入数据时,会将上述3个操作放到一个 wiredtiger 的事务里,确保「原子性」。
beginTransaction();
writeDataToColleciton();
writeCollectionIndex();
writeOplog();
commitTransaction();
wiredtiger 提交事务时,会将所有修改操作应用,并将上述3个操作写入到一条 journal 操作日志里;后台会周期性的checkpoint,将修改持久化,并移除无用的journal。
从数据布局看,oplog 与 journal 的关系
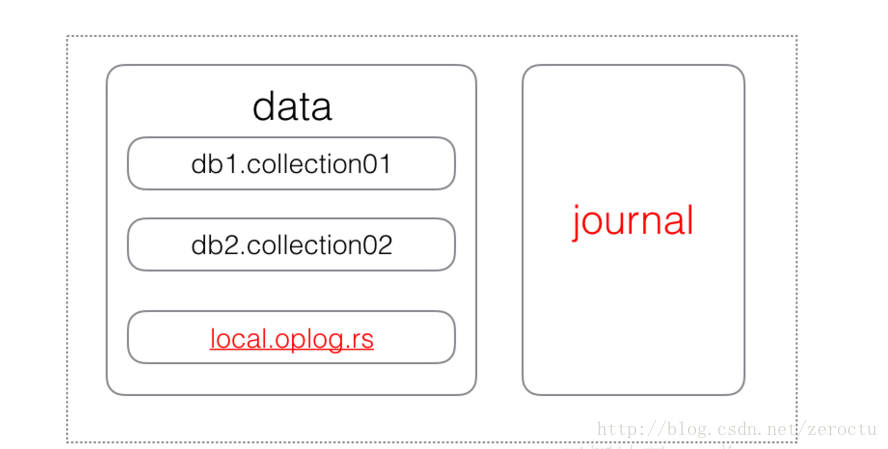
谁先写入??
- oplog 与 journal 是 MongoDB 里不同层次的概念,放在一起比先后本身是不合理的。
- oplog 在 MongoDB 里是一个普通的集合,所以 oplog 的写入与普通集合的写入并无区别。
- 一次写入,会对应数据、索引,oplog的修改,而这3个修改,会对应一条journal操作日志。