原文发布时间:2010-04-22 14:20:16
作者:walh
联系方式:[email protected]
整理:乱马
这个案例是由一个用户在FMETalk用户组提出的问题引出的:
客户在一个目录下有大量的Shape格式的文件。所有这些文件都要被重投影到另一个坐标系。我们正考虑如何进行批量自动化的转换。可以预见的主要问题是,我不能就shape的属性结构进行统一。但是,转换不需要对属性做任何操作,只是将它们复制到目标文件。
能够处理未知属性对于FME2010的动态功能是一件容易的事情。然而,动态工作空间不会做的是重新创建目录结构。事实上,FME默认的行为把所有源数据合并成一个单一的输出数据集。
因此,本文介绍了如何在FME中集成动态和批处理工具。
源数据
本案例采用了FME的标准样例数据FME Sample Dataset。
在默认安装目录C:FMEDataData中,包括了系列的shp格式的数据。我们将会把这些数据重投影到C:FMEDataReprojectedData目录中。
创建工作空间
创建一个读取多源数据集的工作空间是非常简单的----同样容易的是,设置它来读取包含数目未知的数据集文件夹。
下图,创建工作空间:
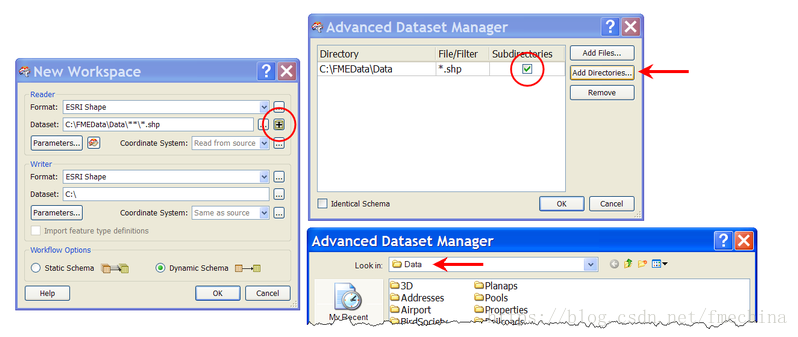
首先设置源数据和目标数据(都是Shape格式),然后选择“添加目录”图标:十字叉形状
在设置对话框中,通过选择所有子目录的选项,来选择所有源数据目录。
写数据集的参数并不重要- 而事实上它是可选的,所以我甚至不需要设置。最后,确认使用的是动态架构的工作流程,然后单击确定以创建工作空间。它看起来像这样
(下图):
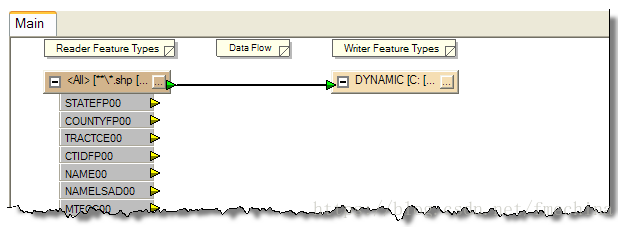
要注意的是,在目标要素上面没有任何属性,在动态工作空间中是不需要的。源数据要素类型合并了所有的属性到一个shape的数据集,这个对我们不重要。
获取源数据文件夹
我们需要知道所有源数据来自哪个目录,能够在写到目标数据的时候,写入相同的相对路径。可以通过设置要素的fme_dataset属性来进行,因此首先需要打开工作空间中的源要素类的属性定义对话框,选择Format Attributes选项页,选择fme_dataset属性,如下图:
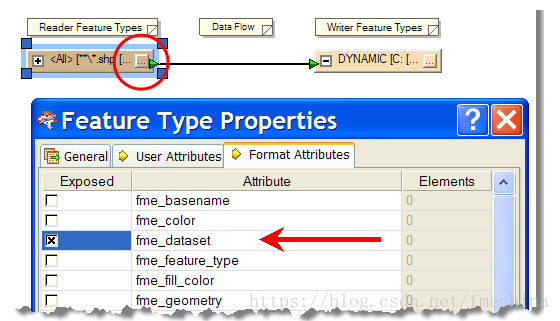
现在这个fme_dataset属性已经可以用了,但是我们需要的是文件夹名称,而不是文件夹+文件名的全名。所以使用FilenamePartExtractor转换器进行文件夹的提取,如下图:
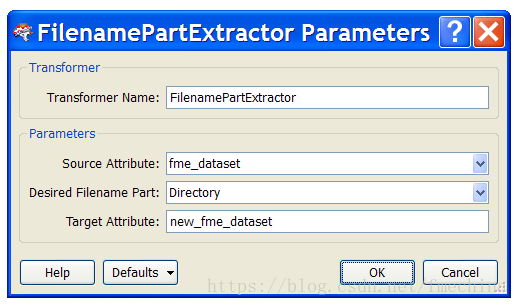
这里我们提取fme_dataset的目录名称,放到一个新的属性new_fme_dataset。
设置输出文件夹
在new_fme_data中,指向的目录为C:\FMEData\Data\xxxx,xxxx包含了源数据shp文件。首先需要替换“Data”到“ReprojectedData”,同时还需要去掉“C:\”,这个在下面将有描述。
使用StringReplacer转换器进行,如下图:
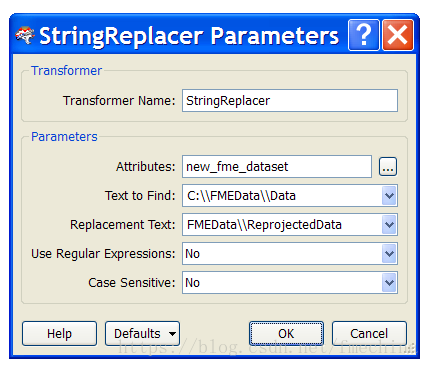
注意,在路径设置中,需要双斜杠,因为单斜杠是保留字符,因此需要使用转义字符来保留。现在new_fme_dataset指向了目录FMEData\ReprojectedData\xxxx。
设置扇出
现在进行数据集的扇出设置,对于数据集的扇出需要采用一个属性进行分类,这里采用new_fme_dataset作为扇出属性。
在导航窗体,找到shape写模块的设置中的Fanout参数,并双击它,如下图:
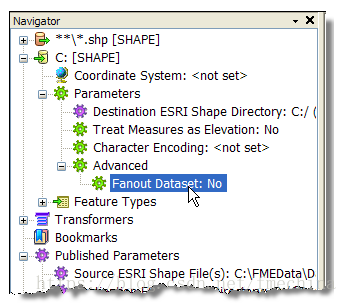
在对话框中来设置:
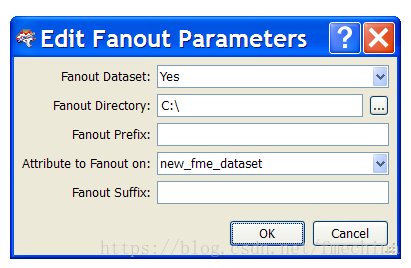
正如看到的所示,设置C盘根目录C:\为扇出目录(这就是为什么在上面移除C:\)。然后设置扇出的属性条件为new_fme_dataset。
转换数据
所有设置完成后,就可以进行任何我们需要的转换了。案例中进行的是重投影变换。如果shape格式的数据带有一个工程prj,我们就不需要设置读模块的坐标系参数,只是需要设置写模块(目标数据集)。
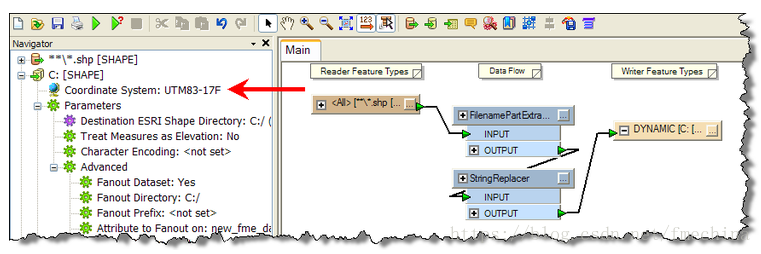
运行工作空间
进行转换,日志文件就会记录读入多少要素,写出多少要素,如下图:
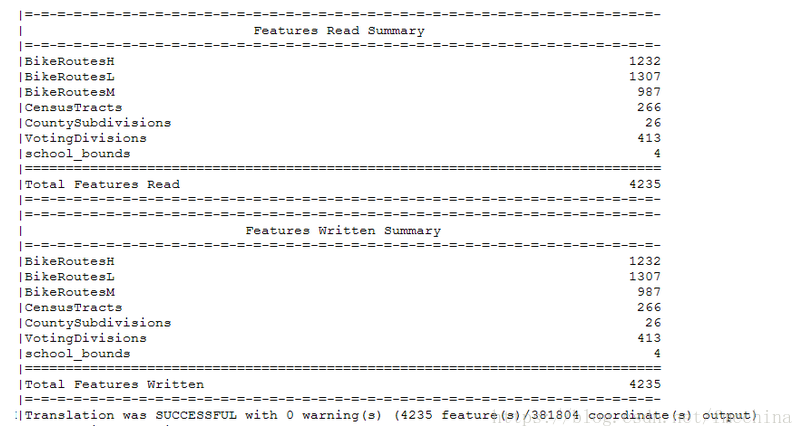
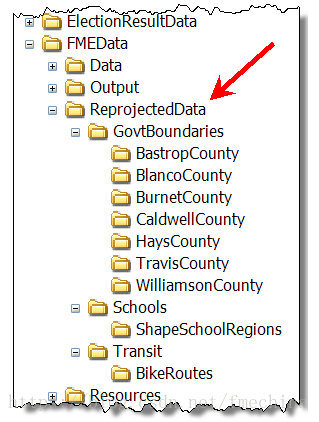
通过windows资源管理器,可以查看转换后的结果目录:
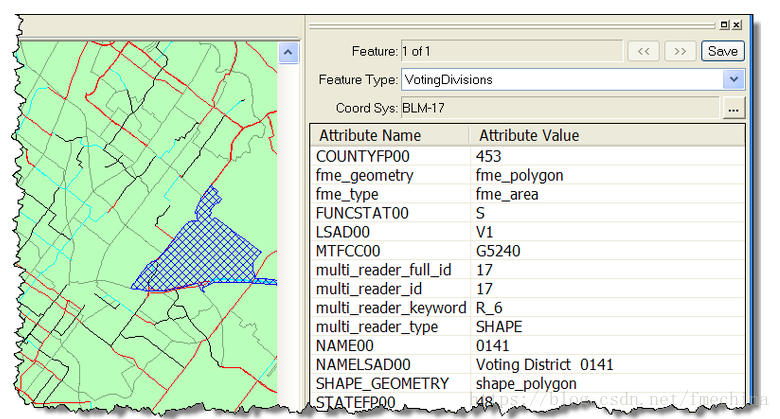
利用FME Viewer可以查看转换后的数据,属性没有任何变化,只是坐标系发生了改变:
更多的考虑
能够从文件夹和子文件夹中读取一组数据集是非常有用,其中任何文件可以在任何目录位置。更重要的是,这个功能是动态的,在这个意义上讲,在运行时,它才去搜索数据集,不是在创建工作空间的时候。所以,你可以添加和删除任何文件,在转换开始前的准备阶段。扇出是另外一个方法对于多目标输出(或者批处理)。也可以在Worbench中使用菜单File->Batch Deploy的功能,或者组合使用FilePath Reader(文件路径读模块)和WorkspaceRunner函数来运行工作空间,并传递源数据参数到这个工作空间。
你所有的源数据越多,扇出的功能发挥的越好,因为所有的数据都会读入并缓存到一个单独的转换过程。采用其它的方法,你将会降低性能,因为每个源数据都是单独处理的。
FME Server实施
尽管我们没有使用一个Web服务来运行数据转换,但是这个方案有可能利用FME Server来完成。因为FME Server的构架是可伸缩的,所以对于海量数据的处理效果会更好。
在这个案例中,你可以定义使用WorkspaceRunner方法(更多的情况下是FMEServerJobSubmitter方法),因为每个数据集,在批处理过程中,可以在单独的FME转换引擎(FME Engine)上运行,这样可以极大的提高性能和使用系统资源。
我们希望这个案例你能感兴趣,这个能说明动态工作空间为什么重要,同样演示了其他任务,比如批处理中使用扇出功能。