【0】README
0.1) 本文总结于 数据结构与算法分析+个人的学习心得体会,源代码均为原创;
0.2) 本文列出了数据结构中基本上所有的数据结构排序算法, 整理了相关的博文(源代码);
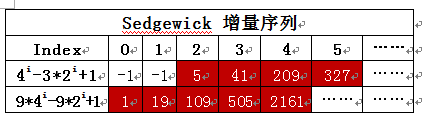
0.3)对于数据结构排序的遗憾是, 这个排序,哥子已经搞了整整1周了,搞乏了,所以没有实现 以 Sedgewick 增量序列 { 或者是 9*4^i - 9*2^i + 1或者是 4^i - 3*2^i + 1; 如,1, 5, 19, 41,……} 的希尔排序 源代码, 其时间复杂度为O(N^(7/6)),等有时间再来实现;其实也不难,因为我已经实现了希尔排序的 hibbard增量序列 {1, 3, …, 2^k-1},其时间复杂度为O(N^(3/2));所以还是有必要实现Sedgewick 增量序列 的希尔排序的(等心情好了,哈哈,心情好了,对的,就来实现它),哎,确实该换换口味了;
【1】总结(Conclusion):
C1)对于最一般的内部排序,选用的方法不是插入排序、希尔排序,就是快速排序,它们的选用主要是根据输入的大小来决定的; 下图显示了每个算法运行的时间对比:
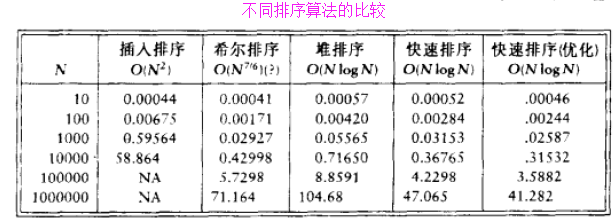
- (对上述图片的说明)(Declaration)
- D1)选择N个整数组成一些随机排序,而表中给出 的各项仅仅是 排序的实际时间;
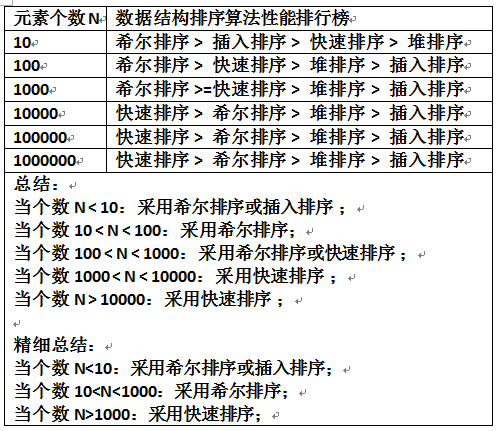
- D2)我们看到,快速排序的性能是比较高的(待排序元素个数大于10),其次是希尔排序, 然后插入排序(待排序元素个数小于10);
- D3)数据结构排序算法性能排行榜
C2)希尔排序: http://blog.csdn.net/pacosonswjtu/article/details/49660799
- C2.1)该程序如果改为使用 Sedgewick 增量 { 或者是 9*4^i - 9*2^i + 1或者是 4^i - 3*2^i + 1; 如,1, 5, 19, 41,109, …… } 运行,基于数以百万次计排序的话, 大小从100~ 25 000 000 不等, 使用这种增量的希尔排序预计的运行时间估计为 O(N^(7/6));(而如果使用 hibbard增量序列 的话, 最坏情况是 Ω(N^(3/2)) )
- C2.2)对输入数据随机的假设是不安全的。如果你不想过多考虑这个问题,那么你就使用希尔排序。希尔排序的最坏情况也只不过是 O(N^(4/3));
C3)堆排序: 堆排序要比希尔排序慢, 尽管它是一个带有明显紧凑内循环的 O(NlogN)算法。对该算法的深入考察揭示出, 为了移动数据,堆排序需要进行两次比较; http://blog.csdn.net/pacosonswjtu/article/details/49660909
C4)快速排序:注意它选取枢纽元 时 所使用的方法是 三数中值分割法,截止范围为10(也就是,如果排序的数组个数小于10, 就不选择快速排序, 而是选择其他排序方法, 如希尔排序或插入排序); http://blog.csdn.net/pacosonswjtu/article/details/48879419
- C4.1)快速排序的改进算法仍然有 O(N^2)的最坏情况, 但是,这种最坏情况出现的机会是如此地微不足道,以至于并不影响算法的性能;
- C4.2)切记,永远不要图省事,把第一个元素作为枢纽元(而是采用三数中值分割法);
- C4.3) 而且由 快速排序,我们还引入 了 快速选择算法,参见: http://blog.csdn.net/pacosonswjtu/article/details/48915197
C5)插入排序:插入排序只用在小的或是非常接近排好序的输入数据上。 http://blog.csdn.net/pacosonswjtu/article/details/48879263
C6)归并排序:我们并没有包含进来归并排序, 因为它的性能对于主存排序不如快速排序那么好, 而且他的编程一点也不省事; http://blog.csdn.net/pacosonswjtu/article/details/49661005
C7)外部排序:合并是外部排序 的思想;
C8)桶排序+基数排序: 在某些特殊情况下以线性时间运行仍然是可能的,比如桶排序或者 基数排序(等同于多次桶排序);
http://blog.csdn.net/pacosonswjtu/article/details/49687193 + http://blog.csdn.net/pacosonswjtu/article/details/49685749