我们在对浏览界面做操作时,比如点击按钮,搜索框输入内容。都需要把鼠标挪过去,然后再点击,或者输入内容。在selenium操作时也是一样的。需要先对元素进行定位,然后才能进行操作。可以借助浏览器的开发者工具(浏览器F12打开)来查看网页对应的html代码。然后进行定位。可以稍微学习HTML基础,更容易理解。
定位方式有八种,这八种各有两个方法,一个是find_element_by_方式,这是定位单个元素的。一个是find_elements_by_方式,这是用来定位多个元素的。
使用name属性定位
打开谷歌浏览器,打开百度首页,F12呼出开发者工具
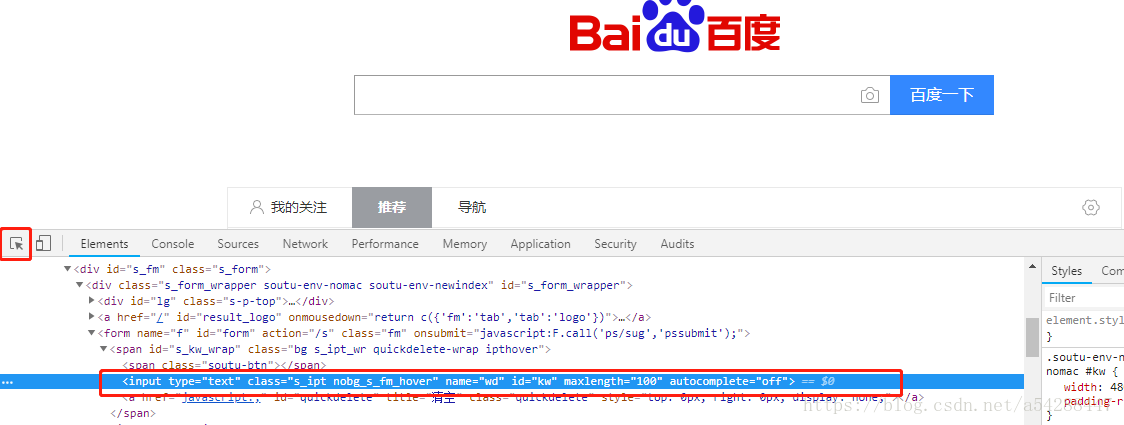
使用左边这个按钮,点击百度搜索框,会自动显示对应HTML代码,可以看到name=‘wd’
from selenium import webdriver
dr = webdriver.Chrome()#初始化chrome浏览器实例
dr.maximize_window()#浏览器最大化
dr.get('https://www.baidu.com')#打开百度首页
test = dr.find_element_by_name('wd')#通过name属性定位输入框
test.send_keys('测试一下')#输入测试一下使用id属性定位
还是以上面百度搜索框为例,id=‘kw’
from selenium import webdriver
dr = webdriver.Chrome()#初始化chrome浏览器实例
dr.maximize_window()#浏览器最大化
dr.get('https://www.baidu.com')#打开百度首页
test = dr.find_element_by_id('kw')#通过id属性定位输入框
test.send_keys('测试一下')#输入测试一下通过id和name是比较常用和容易的定位方式。因为一般id和name元素在一个HTML文件中基本是唯一的。不过有时候前端开发也可能不写这两个属性。
使用class定位
还是使用百度搜索框,class='s_ipt'
from selenium import webdriver
dr = webdriver.Chrome()#初始化chrome浏览器实例
dr.maximize_window()#浏览器最大化
dr.get('https://www.baidu.com')#打开百度首页
test = dr.find_element_by_class_name('s_ipt')#通过classname属性定位输入框
test.send_keys('测试一下')#输入测试一下使用tagname定位

tagname其实就是HTML的标签。不过一个HTML文件里面相同的标签肯定很多,一般很少用到。基本都是定位父元素,然后父元素定位下面所有tagname元素。再根绝其他条件去操作。比如表格啥的。
使用link_text定位
这是用来定位文字超链接的,可以通过文字链接部分的文字描述,定位百度首页上的新闻按钮

from selenium import webdriver
dr = webdriver.Chrome()#初始化chrome浏览器实例
dr.maximize_window()#浏览器最大化
dr.get('https://www.baidu.com')#打开百度首页
test = dr.find_element_by_link_text('新闻')#通过link_text定位新闻跳转按钮
test.click()#点击按钮使用partial_link_text定位
这个也是用来定位文字超链接的,和link_text区别在于,这个相当于模糊搜索,只输入部分文字描述就可以了
from selenium import webdriver
dr = webdriver.Chrome()#初始化chrome浏览器实例
dr.maximize_window()#浏览器最大化
dr.get('https://www.baidu.com')#打开百度首页
test = dr.find_element_by_partial_link_text('新')#通过partial_link_text定位新闻跳转按钮
test.click()#点击按钮使用xpath定位
这个百分百可以定位到,通过层级来的,感兴趣可以学习下xpath的语法,不会也没关系。还是以百度搜索框为例

对着直接右键-copy-copy xpath
from selenium import webdriver
dr = webdriver.Chrome()#初始化chrome浏览器实例
dr.maximize_window()#浏览器最大化
dr.get('https://www.baidu.com')#打开百度首页
test = dr.find_element_by_xpath('//*[@id="kw"]')#通过xpath定位搜索框
test.send_keys('测试一下')#输入测试一下使用css定位
和xpath一样,拷贝的时候选上面的copy-selector就行
from selenium import webdriver
dr = webdriver.Chrome()#初始化chrome浏览器实例
dr.maximize_window()#浏览器最大化
dr.get('https://www.baidu.com')#打开百度首页
test = dr.find_element_by_css_selector('#kw')#通过xpath定位搜索框
test.send_keys('测试一下')#输入测试一下