14年由MSRA的何凯明的Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition提出
这个方法主要有两个优点: (1) 输入可以是任意大小;(2)精度和速度提高
此外,多层次提取特征还增强了网络的鲁棒性,或许这是精度提高的原因之一
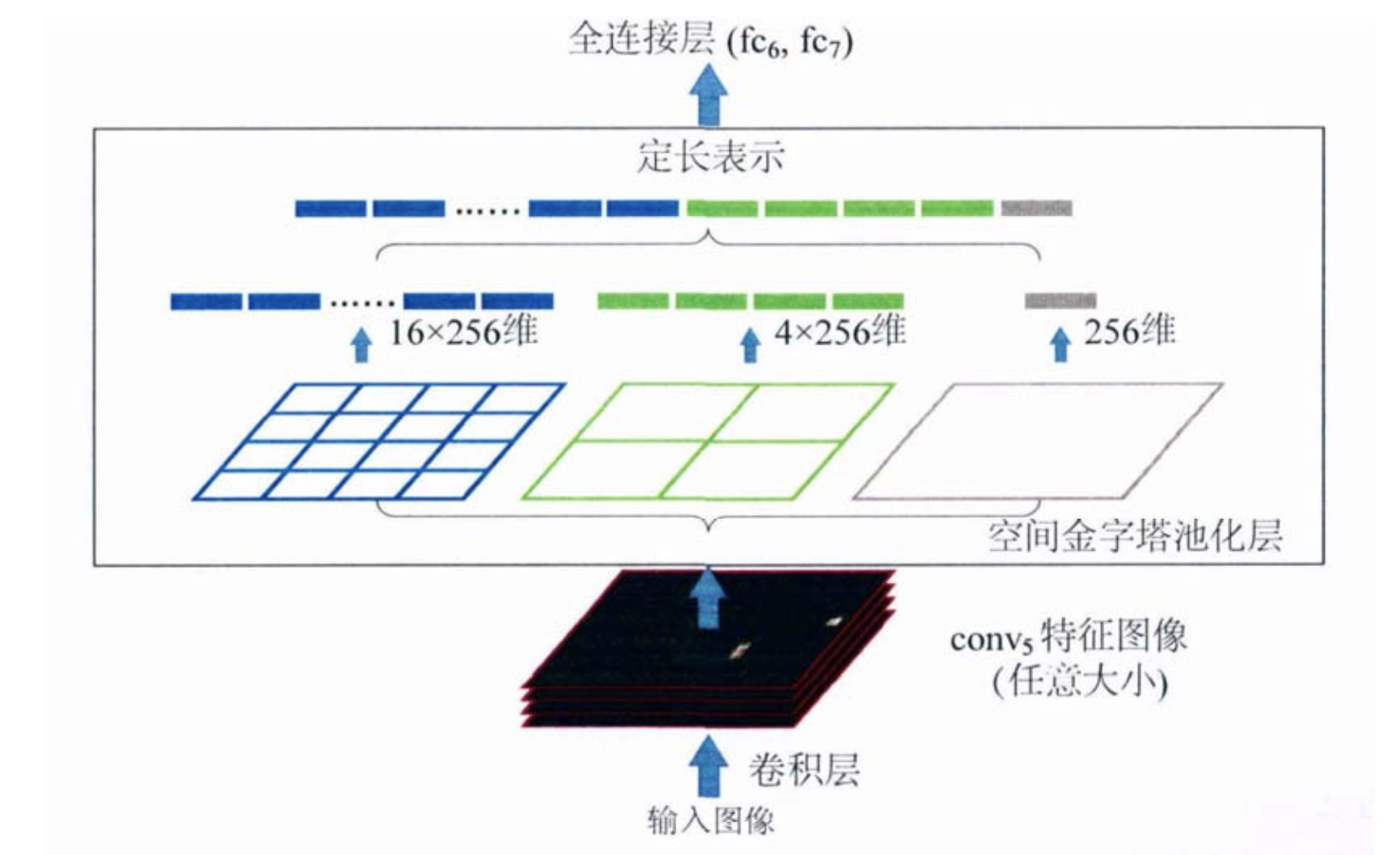
之所以过去的网络要求输入的图片大小是固定的,如R-CNN,是因为全连接层要求输入的特征数是固定的。而如上图的空间金字塔池化结构放在最后一层卷积层和全连接层之间就解决了这个问题。
比如最后的全连接层是21个特征数,那么如上图,我们对图片进行三种划分,分别划分成16块,4块和1块,16+4+1=21。
空间金字塔池化的精华就在于此:多尺度特征提取出固定大小的特征向量!
参考:
https://blog.csdn.net/hjimce/article/details/50187655