1、命令行
语法结构
hive [-hive conf x=y]* [<-i file name>]* [<-f file name>|<-equery-string>] [-S]
说明:
1、 -i 从文件初始化HQL。
2、 -e从命令行执行指定的HQL
3、 -f 执行HQL脚本
4、 -v 输出执行的HQL语句到控制台
5、 -p <port> connect to Hive Server onport number
6、 -hive conf x=y Use this to set hive/hadoopconfiguration variables.
具体实例
1、运行一个查询。

2、运行一个文件。
3、运行参数文件。

参数配置方式
Hive参数大全:
https://cwiki.apache.org/confluence/display/Hive/Configuration+Properties
举例为:

等等……………………
开发Hive应用时,不可避免地需要设定Hive的参数。设定Hive的参数可以调优HQL代码的执行效率,或帮助定位问题。然而实践中经常遇到的一个问题是,为什么设定的参数没有起作用?这通常是错误的设定方式导致的。
对于一般参数,有以下三种设定方式:
l 配置文件
l 命令行参数
l 参数声明
配置文件:Hive的配置文件包括
l 用户自定义配置文件:$HIVE_CONF_DIR/hive-site.xml
l 默认配置文件:$HIVE_CONF_DIR/hive-default.xml
用户自定义配置会覆盖默认配置。
另外,Hive也会读入Hadoop的配置,因为Hive是作为Hadoop的客户端启动的,Hive的配置会覆盖Hadoop的配置。
配置文件的设定对本机启动的所有Hive进程都有效。
命令行参数:启动Hive(客户端或Server方式)时,可以在命令行添加-hiveconf param=value来设定参数,例如:
bin/hive-hiveconf hive.root.logger=INFO,console
这一设定对本次启动的Session(对于Server方式启动,则是所有请求的Sessions)有效。
参数声明:可以在HQL中使用SET关键字设定参数,例如:
setmapred.reduce.tasks=100;
这一设定的作用域也是session级的。
上述三种设定方式的优先级依次递增。即参数声明覆盖命令行参数,命令行参数覆盖配置文件设定。注意某些系统级的参数,例如log4j相关的设定,必须用前两种方式设定,因为那些参数的读取在Session建立以前已经完成了。
2、函数
内置运算符
内容较多,见《Hive官方文档》
举例为:
A = B |
所有原始类型 |
如果A与B相等,返回TRUE,否则返回FALSE |
A == B |
无 |
失败,因为无效的语法。 SQL使用”=”,不使用”==”。 |
A <> B |
所有原始类型 |
如果A不等于B返回TRUE,否则返回FALSE。如果A或B值为”NULL”,结果返回”NULL”。 |
等……………………
内置函数
内容较多,见《Hive官方文档》
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
函数 |
类型 |
说明 |
map |
(key1, value1, key2, value2, …) |
通过指定的键/值对,创建一个map。 |
struct |
(val1, val2, val3, …) |
通过指定的字段值,创建一个结构。结构字段名称将COL1,COL2,… |
array |
(val1, val2, …) |
通过指定的元素,创建一个数组。 |
对复杂类型函数操作:
函数 |
类型 |
说明 |
A[n] |
A是一个数组,n为int型 |
返回数组A的第n个元素,第一个元素的索引为0。如果A数组为['foo','bar'],则A[0]返回’foo’和A[1]返回”bar”。 |
M[key] |
M是Map,关键K型 |
返回关键值对应的值,例如mapM为 \{‘f’ -> ‘foo’, ‘b’ -> ‘bar’, ‘all’ -> ‘foobar’\},则M['all'] 返回’foobar’。 |
S.x |
S为struct |
返回结构x字符串在结构S中的存储位置。如 foobar \{int foo, int bar\} foobar.foo的领域中存储的整数。 |
数学函数:
返回类型 |
函数 |
说明 |
BIGINT |
round(double a) |
四舍五入 |
DOUBLE |
round(double a, int d) |
小数部分d位之后数字四舍五入,例如round(21.263,2),返回21.26 |
BIGINT |
floor(double a) |
对给定数据进行向下舍入最接近的整数。例如floor(21.2),返回21。 |
BIGINT |
ceil(double a), ceiling(double a) |
将参数向上舍入为最接近的整数。例如ceil(21.2),返回23. |
double |
rand(), rand(int seed) |
返回大于或等于0且小于1的平均分布随机数(依重新计算而变) |
double |
exp(double a) |
返回e的n次方 |
double |
ln(double a) |
返回给定数值的自然对数 |
double |
log10(double a) |
返回给定数值的以10为底自然对数 |
double |
log2(double a) |
返回给定数值的以2为底自然对数 |
double |
log(double base, double a) |
返回给定底数及指数返回自然对数 |
double |
pow(double a, double p) power(double a, double p) |
返回某数的乘幂 |
double |
sqrt(double a) |
返回数值的平方根 |
|
abs(double a) |
取绝对值 |
收集函数
返回类型 |
函数 |
说明 |
int |
size(Map) |
返回的map类型的元素的数量 |
int |
size(Array) |
返回数组类型的元素数量 |
类型转换函数
返回类型 |
函数 |
说明 |
指定 “type” |
cast(expr as ) |
类型转换。例如将字符”1″转换为整数:cast(’1′ as bigint),如果转换失败返回NULL。 |
等等……………………
测试各种内置函数的快捷方法:
1、创建一个dual表
create table dual(id string);
2、load一个文件(一行,一个空格)到dual表
3、select substr('angelababy',2,3) from dual;
自定义函数和Transform
当Hive提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数(UDF:user-defined function)。
自定义函数类别
UDF:作用于单个数据行,产生一个数据行作为输出。(数学函数,字符串函数)
UDAF(用户定义聚集函数):接收多个输入数据行,并产生一个输出数据行。(count,max)
UDF开发实例:
l 简单UDF示例
先开发一个java类,继承UDF,并重载evaluate方法,此处所说UDF为Temporary的function,所以需要hive版本在0.4.0以上才可以。
package com.hrj.hive.udf;
importorg.apache.hadoop.hive.ql.exec.UDF;
publicclass helloUDF extends UDF {
publicString evaluate(String str) {
try{
return"HelloWorld " + str;
}catch (Exception e) {
returnnull;
}
}
}
将该java文件编译成helloudf.jar
hive>add jar helloudf.jar;
hive>create temporary function helloworld as 'com.hrj.hive.udf.helloUDF';
hive>select helloworld(t.col1) from t limit 10;
hive>drop temporary function helloworld;
注:
1.helloworld为临时的函数,所以每次进入hive都需要add jar以及create temporary操作
2.UDF只能实现一进一出的操作,如果需要实现多进一出,则需要实现UDAF
UDF的几个案例:
输入一个phoneNo返回手机号以及对应的地址;
首先:建一个表,将数据导入到hive的表中:

然后:传入编写完成的重载了evaluate的相应的jar包到hive中;
packagecn.itcast.bigdata.udf;
importjava.util.HashMap;
importorg.apache.hadoop.hive.ql.exec.UDF;
publicclass ToLowerCase extends UDF {
public static HashMap<String,String> provinceMap
= new HashMap<String,String>();
static {
provinceMap.put("136","beijing");
provinceMap.put("137","shanghai");
provinceMap.put("138","shenzhen");
}
// 必须是public
public String evaluate(String field) {
String result = field.toLowerCase();
return result;
}
public String evaluate(int phonenbr) {
String pnb =String.valueOf(phonenbr);
returnprovinceMap.get(pnb.substring(0, 3))
== null? "huoxing":provinceMap.get(pnb.substring(0,3));
}
}
其三:创建函数的映射,然后查询即可:

解析Json数据:现在的工作为将下面的json变成一个表(有四个字段):
数据集样式为:

首先:创建一个hive的基础表并将数据导入到hive表中:

其次:创建新的函数,并打包传到hive的lib中:
packagecn.itcast.bigdata.udf;
importorg.apache.hadoop.hive.ql.exec.UDF;
importparquet.org.codehaus.jackson.map.ObjectMapper;
publicclass JsonParser extends UDF {
public String evaluate(String jsonLine) {
ObjectMapper objectMapper = newObjectMapper();
try {
//将json串转化成一个个bean:将jsonline解析为movieratebean类型;
MovieRateBean bean
=objectMapper.readValue(jsonLine, MovieRateBean.class);
return bean.toString();
} catch (Exception e) {
}
return "";
}
}
对应的java的Bean为:
packagecn.itcast.bigdata.udf;
//{"movie":"1721","rate":"3","timeStamp":"965440048","uid":"5114"}
publicclass MovieRateBean {
private String movie;
private String rate;
private String timeStamp;
private String uid;
public String getMovie() {
return movie;
}
public void setMovie(String movie) {
this.movie = movie;
}
public String getRate() {
return rate;
}
public void setRate(String rate) {
this.rate = rate;
}
public String getTimeStamp() {
return timeStamp;
}
public void setTimeStamp(String timeStamp){
this.timeStamp = timeStamp;
}
public String getUid() {
return uid;
}
public void setUid(String uid) {
this.uid = uid;
}
@Override
public String toString() {
return movie + "\t" + rate+ "\t" + timeStamp + "\t" + uid;
}
}
其三:创建临时函数进行查询:

运行之后会解析出一个只有一个字段的表:

为了形成四个字段,需要用到下一条语句:

此时就会形成含有四个字段的表:
UDAF的实现:
开发通用UDAF有两个步骤,第一个是编写resolver类,第二个是编写evaluator类。resolver负责类型检查,操作符重载。evaluator真正实现UDAF的逻辑。通常来说,顶层UDAF类继承org.apache.hadoop.hive.ql.udf.GenericUDAFResolver2,里面编写嵌套类evaluator 实现UDAF的逻辑。
本文以Hive的内置UDAF sum函数的源代码作为示例讲解。
实现 resolver
resolver通常继承org.apache.hadoop.hive.ql.udf.GenericUDAFResolver2,但是我们更建议继承AbstractGenericUDAFResolver,隔离将来hive接口的变化。
GenericUDAFResolver和GenericUDAFResolver2接口的区别是,后面的允许evaluator实现可以访问更多的信息,例如DISTINCT限定符,通配符FUNCTION(*)。
public class GenericUDAFSum extends AbstractGenericUDAFResolver {
static final Log LOG = LogFactory.getLog(GenericUDAFSum.class.getName());
@Override
public GenericUDAFEvaluator getEvaluator(TypeInfo[] parameters)
throws SemanticException {
// Type-checking goes here!
return new GenericUDAFSumLong(); } public static class GenericUDAFSumLong extends GenericUDAFEvaluator {
// UDAF logic goes here!
}
}
这个就是UDAF的代码骨架,第一行创建LOG对象,用来写入警告和错误到hive的log。GenericUDAFResolver只需要重写一个方法:getEvaluator,它根据SQL传入的参数类型,返回正确的evaluator。这里最主要是实现操作符的重载。
getEvaluator的完整代码如下:
public GenericUDAFEvaluator getEvaluator(TypeInfo[] parameters)
throws SemanticException {
if (parameters.length != 1) {
throw new UDFArgumentTypeException(parameters.length - 1,
"Exactly one argument is expected.");
}
if (parameters[0].getCategory() != ObjectInspector.Category.PRIMITIVE) {
throw new UDFArgumentTypeException(0,
"Only primitive type arguments are accepted but "
+ parameters[0].getTypeName() + " is passed.");
}
switch (((PrimitiveTypeInfo) parameters[0]).getPrimitiveCategory()) {
case BYTE:
case SHORT:
case INT:
case LONG:
case TIMESTAMP:
return new GenericUDAFSumLong();
case FLOAT:
case DOUBLE:
case STRING:
return new GenericUDAFSumDouble();
case BOOLEAN:
default:
throw new UDFArgumentTypeException(0,
"Only numeric or string type arguments are accepted but "
+ parameters[0].getTypeName() + " is passed.");
}
这里做了类型检查,如果不是原生类型(即符合类型,array,map此类),则抛出异常,还实现了操作符重载,对于整数类型,使用GenericUDAFSumLong实现UDAF的逻辑,对于浮点类型,使用GenericUDAFSumDouble实现UDAF的逻辑。
实现evaluator
所有evaluators必须继承抽象类org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator。子类必须实现它的一些抽象方法,实现UDAF的逻辑。
GenericUDAFEvaluator有一个嵌套类Mode,这个类很重要,它表示了udaf在mapreduce的各个阶段,理解Mode的含义,就可以理解了hive的UDAF的运行流程。
public static enum Mode {
/**
* PARTIAL1: 这个是mapreduce的map阶段:从原始数据到部分数据聚合
* 将会调用iterate()和terminatePartial()
*/
PARTIAL1,
/**
* PARTIAL2: 这个是mapreduce的map端的Combiner阶段,负责在map端合并map的数据::从部分数据聚合到部分数据聚合:
* 将会调用merge() 和 terminatePartial()
*/
PARTIAL2,
/**
* FINAL: mapreduce的reduce阶段:从部分数据的聚合到完全聚合
* 将会调用merge()和terminate()
*/
FINAL,
/**
* COMPLETE: 如果出现了这个阶段,表示mapreduce只有map,没有reduce,所以map端就直接出结果了:从原始数据直接到完全聚合
* 将会调用 iterate()和terminate()
*/
COMPLETE
};
一般情况下,完整的UDAF逻辑是一个mapreduce过程,如果有mapper和reducer,就会经历PARTIAL1(mapper),FINAL(reducer),如果还有combiner,那就会经历PARTIAL1(mapper),PARTIAL2(combiner),FINAL(reducer)。
而有一些情况下的mapreduce,只有mapper,而没有reducer,所以就会只有COMPLETE阶段,这个阶段直接输入原始数据,出结果。
下面以GenericUDAFSumLong的evaluator实现讲解
public static class GenericUDAFSumLong extends GenericUDAFEvaluator {
private PrimitiveObjectInspector inputOI;
private LongWritable result;
//这个方法返回了UDAF的返回类型,这里确定了sum自定义函数的返回类型是Long类型
@Override
public ObjectInspector init(Mode m, ObjectInspector[] parameters) throws HiveException {
assert (parameters.length == 1);
super.init(m, parameters);
result = new LongWritable(0);
inputOI = (PrimitiveObjectInspector) parameters[0];
return PrimitiveObjectInspectorFactory.writableLongObjectInspector;
}
/** 存储sum的值的类 */
static class SumLongAgg implements AggregationBuffer {
boolean empty;
long sum;
}
//创建新的聚合计算的需要的内存,用来存储mapper,combiner,reducer运算过程中的相加总和。
@Override
public AggregationBuffer getNewAggregationBuffer() throws HiveException {
SumLongAgg result = new SumLongAgg();
reset(result);
return result;
}
//mapreduce支持mapper和reducer的重用,所以为了兼容,也需要做内存的重用。
@Override
public void reset(AggregationBuffer agg) throws HiveException {
SumLongAgg myagg = (SumLongAgg) agg;
myagg.empty = true;
myagg.sum = 0;
}
private boolean warned = false;
//map阶段调用,只要把保存当前和的对象agg,再加上输入的参数,就可以了。
@Override
public void iterate(AggregationBuffer agg, Object[] parameters) throws HiveException {
assert (parameters.length == 1);
try {
merge(agg, parameters[0]);
} catch (NumberFormatException e) {
if (!warned) {
warned = true;
LOG.warn(getClass().getSimpleName() + " "
+ StringUtils.stringifyException(e));
}
}
}
//mapper结束要返回的结果,还有combiner结束返回的结果
@Override
public Object terminatePartial(AggregationBuffer agg) throws HiveException {
return terminate(agg);
}
//combiner合并map返回的结果,还有reducer合并mapper或combiner返回的结果。
@Override
public void merge(AggregationBuffer agg, Object partial) throws HiveException {
if (partial != null) {
SumLongAgg myagg = (SumLongAgg) agg;
myagg.sum += PrimitiveObjectInspectorUtils.getLong(partial, inputOI);
myagg.empty = false;
}
}
//reducer返回结果,或者是只有mapper,没有reducer时,在mapper端返回结果。
@Override
public Object terminate(AggregationBuffer agg) throws HiveException {
SumLongAgg myagg = (SumLongAgg) agg;
if (myagg.empty) {
return null;
}
result.set(myagg.sum);
return result;
}
}
除了GenericUDAFSumLong,还有重载的GenericUDAFSumDouble,以上代码都在hive的源码:org.apache.hadoop.hive.ql.udf.generic.GenericUDAFSum。
1.将java文件编译成Sum_Sample.jar
2.进入hive
hive> add jarSum_sample.jar;
hive> create temporaryfunction sum_test as 'com.hrj.hive.udf.UDAFSum_Sample';
hive> select sum_test(t.num)from t;
hive> drop temporaryfunction sum_test;
hive> quit;
关于UDAF开发注意点:
1.需要import org.apache.hadoop.hive.ql.exec.UDAF以及org.apache.hadoop.hive.ql.exec.UDAFEvaluator,这两个包都是必须的
2.函数类需要继承UDAF类,内部类Evaluator实现UDAFEvaluator接口
3.Evaluator需要实现 init、iterate、terminatePartial、merge、terminate这几个函数
1)init函数类似于构造函数,用于UDAF的初始化
2)iterate接收传入的参数,并进行内部的轮转。其返回类型为boolean (在map机器上执行)
3)terminatePartial无参数,其为iterate函数轮转结束后,返回乱转数据,iterate和terminatePartial类似于hadoop的Combiner (一个map上的所有iterate结束后执行函数terminatePartial)。
4)merge接收terminatePartial的返回结果,进行数据merge操作,其返回类型为boolean (在reduce上执行)
5)terminate返回最终的聚集函数结果
Transform实现
Hive的TRANSFORM关键字提供了在SQL中调用自写脚本的功能
适合实现Hive中没有的功能又不想写UDF的情况
使用示例1:下面这句sql就是借用了weekday_mapper.py对数据进行了处理.
首先创建一个空表:
CREATE TABLE u_data_new (
movieid INT,
rating INT,
weekday INT,
useridINT)
ROW FORMAT DELIMITED FIELDS TERMINATED BY'\t';
设计一个py的脚本:
add FILE /home/Hadoop/weekday_mapper.py;
查询的时候使用transform:
INSERT OVERWRITE TABLE u_data_new
SELECT
TRANSFORM (movieid ,rate, timestring,uid) //老表里的字段;
USING 'python weekday_mapper.py'
AS(movieid, rating, weekday,userid)//新表的字段;
FROM t_rating;
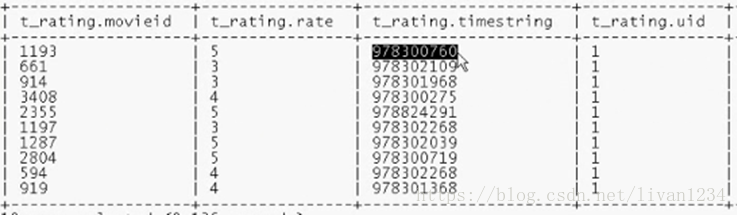
老表为t_rating:

将第三个字段给转化成星期几的样式:
主要是将老字段用using进行转换,形成新表中的内容:

其中weekday_mapper.py内容如下
#!/bin/python import sys import datetime for line in sys.stdin: line = line.strip() movieid, rating, unixtime,userid = line.split('\t') weekday = datetime.datetime.fromtimestamp(float(unixtime)).isoweekday() print('\t'.join([movieid, rating, str(weekday),userid])) |
实战
1)Hive实战案例1——数据ETL
需求:
ü 对web点击流日志基础数据表进行etl(按照仓库模型设计)
ü 按各时间维度统计来源域名top10
已有数据表“t_orgin_weblog” :
+------------------+------------+----------+--+ | col_name | data_type | comment | +------------------+------------+----------+--+ | valid | string | | | remote_addr | string | | | remote_user | string | | | time_local | string | | | request | string | | | status | string | | | body_bytes_sent | string | | | http_referer | string | | | http_user_agent | string | | +------------------+------------+----------+--+ |
数据示例:
| true|1.162.203.134| - | 18/Sep/2013:13:47:35| /images/my.jpg | 200| 19939 | "http://www.angularjs.cn/A0d9" | "Mozilla/5.0 (Windows | | true|1.202.186.37 | - | 18/Sep/2013:15:39:11| /wp-content/uploads/2013/08/windjs.png| 200| 34613 | "http://cnodejs.org/topic/521a30d4bee8d3cb1272ac0f" | "Mozilla/5.0 (Macintosh;| |
实现步骤:
1)对原始数据进行抽取转换
--将来访url分离出host path query query id
drop table if exists t_etl_referurl; create table t_etl_referurl as SELECT a.*,b.* FROM t_orgin_weblog a LATERAL VIEW parse_url_tuple(regexp_replace(http_referer, "\"", ""), 'HOST', 'PATH','QUERY', 'QUERY:id') b as host, path, query, query_id |
2)从前述步骤进一步分离出日期时间形成ETL明细表“t_etl_detail” day tm
drop table if exists t_etl_detail; create table t_etl_detail as select b.*,substring(time_local,0,11) as daystr, substring(time_local,13) as tmstr, substring(time_local,4,3) as month, substring(time_local,0,2) as day, substring(time_local,13,2) as hour from t_etl_referurl b; |
3)对etl数据进行分区(包含所有数据的结构化信息)
drop table t_etl_detail_prt; create table t_etl_detail_prt( valid string, remote_addr string, remote_user string, time_local string, request string, status string, body_bytes_sent string, http_referer string, http_user_agent string, host string, path string, query string, query_id string, daystr string, tmstr string, month string, day string, hour string) partitioned by (mm string,dd string); |
导入数据
insert into table t_etl_detail_prt partition(mm='Sep',dd='18') select * from t_etl_detail where daystr='18/Sep/2013'; insert into table t_etl_detail_prt partition(mm='Sep',dd='19') select * from t_etl_detail where daystr='19/Sep/2013'; |
分个时间维度统计各referer_host的访问次数并排序
create table t_refer_host_visit_top_tmp as select referer_host,count(*) as counts,mm,dd,hh from t_display_referer_counts group by hh,dd,mm,referer_host order by hh asc,dd asc,mm asc,counts desc; |
4)来源访问次数topn各时间维度URL
取各时间维度的referer_host访问次数topn
select * from (select referer_host,counts,concat(hh,dd),row_number() over (partition by concat(hh,dd) order by concat(hh,dd) asc) as od from t_refer_host_visit_top_tmp) t where od<=3; |
实战案例2——访问时长统计
需求:
从web日志中统计每日访客平均停留时间
实现步骤:
1)由于要从大量请求中分辨出用户的各次访问,逻辑相对复杂,通过hive直接实现有困难,因此编写一个mr程序来求出访客访问信息(详见代码)
启动mr程序获取结果:
[hadoop@hdp-node-01 ~]$ hadoop jar weblog.jar cn.itcast.bigdata.hive.mr.UserStayTime /weblog/input /weblog/stayout |
2)将mr的处理结果导入hive表
drop table t_display_access_info_tmp; create table t_display_access_info_tmp(remote_addr string,firt_req_time string,last_req_time string,stay_long bigint) row format delimited fields terminated by '\t'; load data inpath '/weblog/stayout4' into table t_display_access_info_tmp; |
3)得出访客访问信息表"t_display_access_info"
由于有一些访问记录是单条记录,mr程序处理处的结果给的时长是0,所以考虑给单次请求的停留时间一个默认市场30秒
drop table t_display_access_info; create table t_display_access_info as select remote_addr,firt_req_time,last_req_time, case stay_long when 0 then 30000 else stay_long end as stay_long from t_display_access_info_tmp; |
4)统计所有用户停留时间平均值
select avg(stay_long) fromt_display_access_info;
实战案例3——级联求和
需求:
有如下访客访问次数统计表 t_access_times
访客 |
月份 |
访问次数 |
A |
2015-01 |
5 |
A |
2015-01 |
15 |
B |
2015-01 |
5 |
A |
2015-01 |
8 |
B |
2015-01 |
25 |
A |
2015-01 |
5 |
A |
2015-02 |
4 |
A |
2015-02 |
6 |
B |
2015-02 |
10 |
B |
2015-02 |
5 |
…… |
…… |
…… |
需要输出报表:t_access_times_accumulate
访客 |
月份 |
月访问总计 |
累计访问总计 |
A |
2015-01 |
33 |
33 |
A |
2015-02 |
10 |
43 |
……. |
……. |
……. |
……. |
B |
2015-01 |
30 |
30 |
B |
2015-02 |
15 |
45 |
……. |
……. |
……. |
……. |
实现步骤:
可以用一个hql语句即可实现:
select A.username,A.month,max(A.salary) as salary,sum(B.salary) as accumulate from (select username,month,sum(salary) as salary from t_access_times group by username,month) A inner join (select username,month,sum(salary) as salary from t_access_times group by username,month) B on A.username=B.username where B.month <= A.month group by A.username,A.month order by A.username,A.month; |
解读为:
第一步:先求各用户的月总金额:
select username,month,sum(salary) as salaryfrom t_access_times group by username,month

第二步:将查询的表自连接:
(selectusername,month,sum(salary) as salary from t_access_times group byusername,month) A
inner join
(selectusername,month,sum(salary) as salary from t_access_times group byusername,month) B
on
A.username=B.username
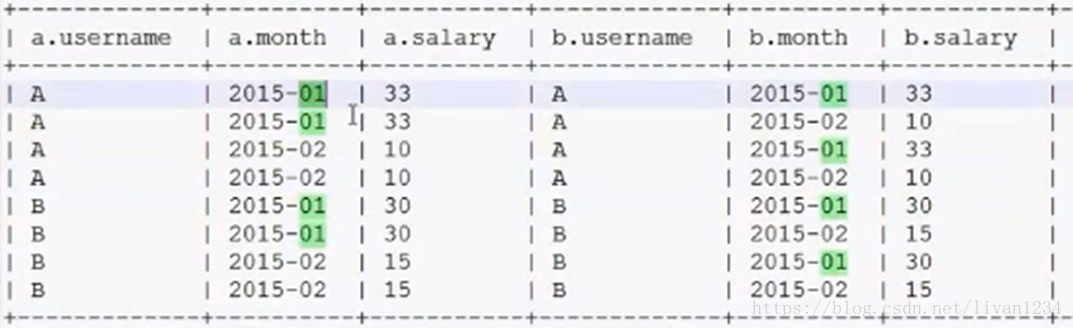
第三步:从上一步的结果中
进行分组查询,分组的字段是a.usernamea.month
求月累计值:将b.month <=a.month的所有b.salary求和即可
select A.username,A.month,max(A.salary)as salary,sum(B.salary) as accumulate
from
(select username,month,sum(salary) assalary from t_access_times group by username,month) A
inner join
(select username,month,sum(salary) assalary from t_access_times group by username,month) B
on
A.username=B.username
where B.month <= A.month
group by A.username,A.month
order by A.username,A.month;