字符串类型(str)
-
字符串说明
-
转义字符
-
字符串运算符
-
字符串格式化
-
字符串内置的函数
一.字符串说明
字符串是 Python 中最常用的数据类型。我们可以使用引号('或")来创建字符串。
创建字符串,只需要为变量赋值即可,如:Str = "hello world"
访问字符串中的值:
Python 不支持单字符类型,单字符在 Python 中也是作为一个字符串使用。
>>> print("hello world") hello world
字符串更新:
可以截取字符串的一部分并与其他字段拼接,如下实例:
>>> print("hello world" + " 你好,中国") hello world 你好,中国
二.转义字符
在需要在字符中使用特殊字符时,python用反斜杠(\)转义字符。如下表:
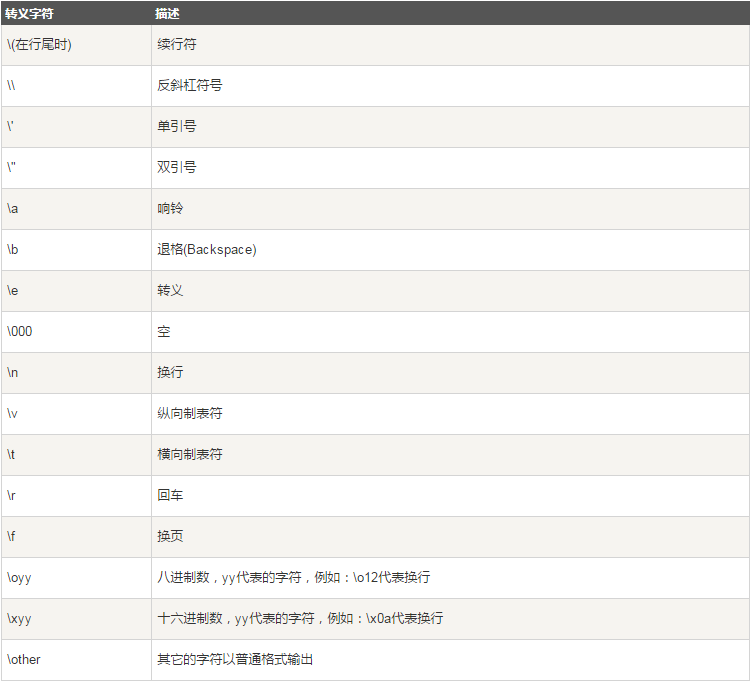
三.字符串运算符
下表实例变量a值为字符串 "Hello",b变量值为 "Python":

四.字符串格式化
Python 支持格式化字符串的输出 。尽管这样可能会用到非常复杂的表达式,但最基本的用法是将一个值插入到一个有字符串格式符 %s 的字符串中。
在 Python 中,字符串格式化使用与 C 中 sprintf 函数一样的语法。
>>> print("中国的首都是%s" % ("北京")) 中国的首都是北京
python字符串格式化符号:
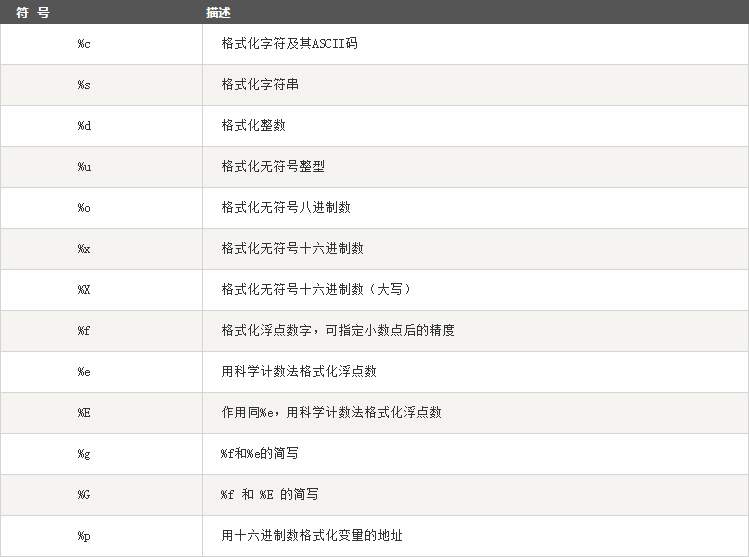
格式化操作符辅助指令:
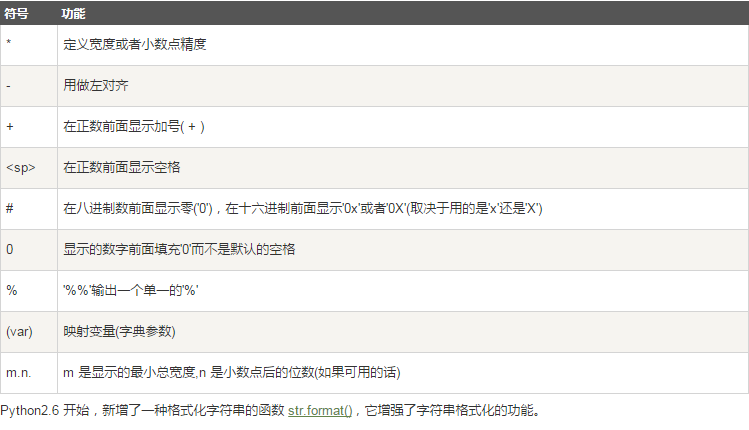
五.字符串内置的函数
1.capitalize(self)
说明:将字符串的第一个字符转换为大写,其他字母变成小写;注意的是并不会改变原字符串内容;
语法:str.capitalize()
返回值:该方法返回一个首字母大写的字符串;
实例:
>>> S = "hello WoRld" >>> print(S.capitalize()) Hello world
2.casefold(self)
说明:将字符串中的所有大写字符转换为小写字符;注意的是并不会改变原字符串内容;
语法:str.casefold()
返回值:返回将字符串中所有大写字符转换为小写后生成的字符串;
实例:
>>> S = "hello WoRld" >>> print(S.casefold()) hello world
3.center(self, width, fillchar=None)
说明:返回一个指定的宽度width且居中的字符串,fillchar为填充的字符,默认为空格;
语法:str.center(width,fillchar)
返回值:返回一个指定的宽度 width 居中的字符串,如果 width 小于字符串宽度直接返回字符串,否则使用 fillchar 去填充。
实例:
>>> print("今日头条".center(40,"*")) ******************今日头条******************
4.count(self, sub, start=None, end=None)
说明:用于统计字符串里某个字符出现的次数。可选参数为在字符串搜索的开始与结束位置。
语法:str.count(sub,start=None, end=None)
参数:sub -----> 要搜索的子字符串;
start -----> 字符串开始搜索的位置。默认为第一个字符,第一个字符索引值为0;
end ------> 字符串中结束搜索的位置。字符中第一个字符的索引为 0。默认为字符串的最后一个位置;
返回值:返回子字符串在字符串中出现的次数;
实例:
>>> print(ss.count("a")) 2 >>> print(ss.count("a",0,8)) 1
5.encode(self, encoding='utf-8', errors='strict')
说明:以指定的编码格式来编码字符串。errors参数可以指定不同的错误处理方案。
语法:str.encode(encoding='utf-8', errors='strict')
参数:encoding -----> 要使用的编码,如:UTF-8
errors -----> 设置不同错误的处理方案。默认为 'strict',意为编码错误引起一个UnicodeError。 其他可能得值有 'ignore', 'replace', 'xmlcharrefreplace', 'backslashreplace' 以及通过 codecs.register_error() 注册的任何值。
返回值:返回编码后的字符串,是一个 bytes 对象
实例:
>>> abc = "灯火阑珊" >>> abc_utf8 = abc.encode("UTF-8") >>> abc_gbk = abc.encode("GBK") >>> print(abc) 灯火阑珊 >>> print(abc_utf8) b'\xe7\x81\xaf\xe7\x81\xab\xe9\x98\x91\xe7\x8f\x8a' >>> print(abc_gbk) b'\xb5\xc6\xbb\xf0\xc0\xbb\xc9\xba'
6.decode(self, decoding='utf-8', errors='strict')
说明:以指定的编码格式来解码字符串。errors参数可以指定不同的错误处理方案。
语法:bytes.decode(encoding="utf-8", errors="strict")
参数:encoding -----> 要使用的编码,如:UTF-8
errors -----> 设置不同错误的处理方案。默认为 'strict',意为编码错误引起一个UnicodeError。 其他可能得值有 'ignore', 'replace', 'xmlcharrefreplace', 'backslashreplace' 以及通过 codecs.register_error() 注册的任何值。
返回值:返回解码后的字符串;
实例:
>>> print(abc_gbk.decode("GBK")) 灯火阑珊 >>> print(abc_utf8.decode("UTF-8")) 灯火阑珊
7.endswith(self, suffix, start=None, end=None)
说明:用于判断字符串是否以指定后缀结尾,如果以指定后缀结尾返回True,否则返回False;
语法:str.endswith(suffix,start=None, end=None)
参数:suffix -----> 该参数可以是一个字符串或者是一个元素;
start ------> 字符串中的开始位置;
end ------> 字符中结束位置
返回值:如果字符串含有指定的后缀返回True,否则返回False;
实例:
>>> end = "hello world" >>> print(end.endswith("ld")) True >>> print(end.endswith("ld",0,10)) False
8.expandtabs(self, tabsize=8)
说明:把字符串中的 tab 符号('\t')转为空格,tab 符号('\t')默认的空格数是 8;
语法:str.expandtabs(tabsize=8)
参数:tabszie -----> 指定转换字符串中的 tab 符号('\t')转为空格的字符数;
返回值:返回字符串中的 tab 符号('\t')转为空格后生成的新字符串;
实例:
>>> ss = "this is \tstring example" >>> print(ss) this is string example >>> print(ss.expandtabs(0)) this is string example >>> print(ss.expandtabs(20)) this is string example
9.find(self, sub, start=None, end=None)
说明:检测字符串中是否包含子字符串 sub ,如果指定 start(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,如果指定范围内如果包含指定索引值,返回的是索引值在字符串中的起始位置。如果不包含索引值,返回-1。
语法:str.find(sub, start=None, end=None)
参数:sub ------> 指定检索的字符串;
start -----> 指定开始索引位置,默认为0
end -----> 指定结束索引位置,默认为字符串长度,len(str)
返回值:如果包含子字符串返回开始的索引值,否则返回-1;
实例:
>>> str1 = "Life is too short for python" >>> print(str1.find("short")) 12 >>> print(str1.find("short",5,19)) 12
>>> print(str1.find("short",17,19))
-1
10.format(self, *args, **kwargs)
说明: