做爬虫,免不了将抓取下来的数据保存到数据库,但是如何保存到数据库呢,下面我通过我工作中抓取的一个网站来展示,代码有点多,但是逻辑很简单,此例是将view Details的链接保存在了mysql中,先看看网站是什么样子:

下边这个图是页码
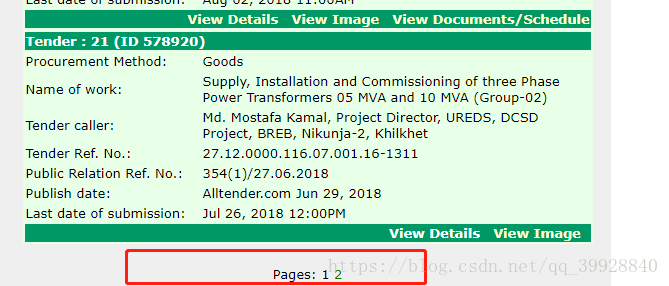
网站是这个样子,我在代码中有个判断,就是判断链接是否有三个,分别执行不同操作,就是根据图中标记来的
此次请求是get请求,不需要传参,只需要重新拼接url进行翻页即可
以下是代码全图:
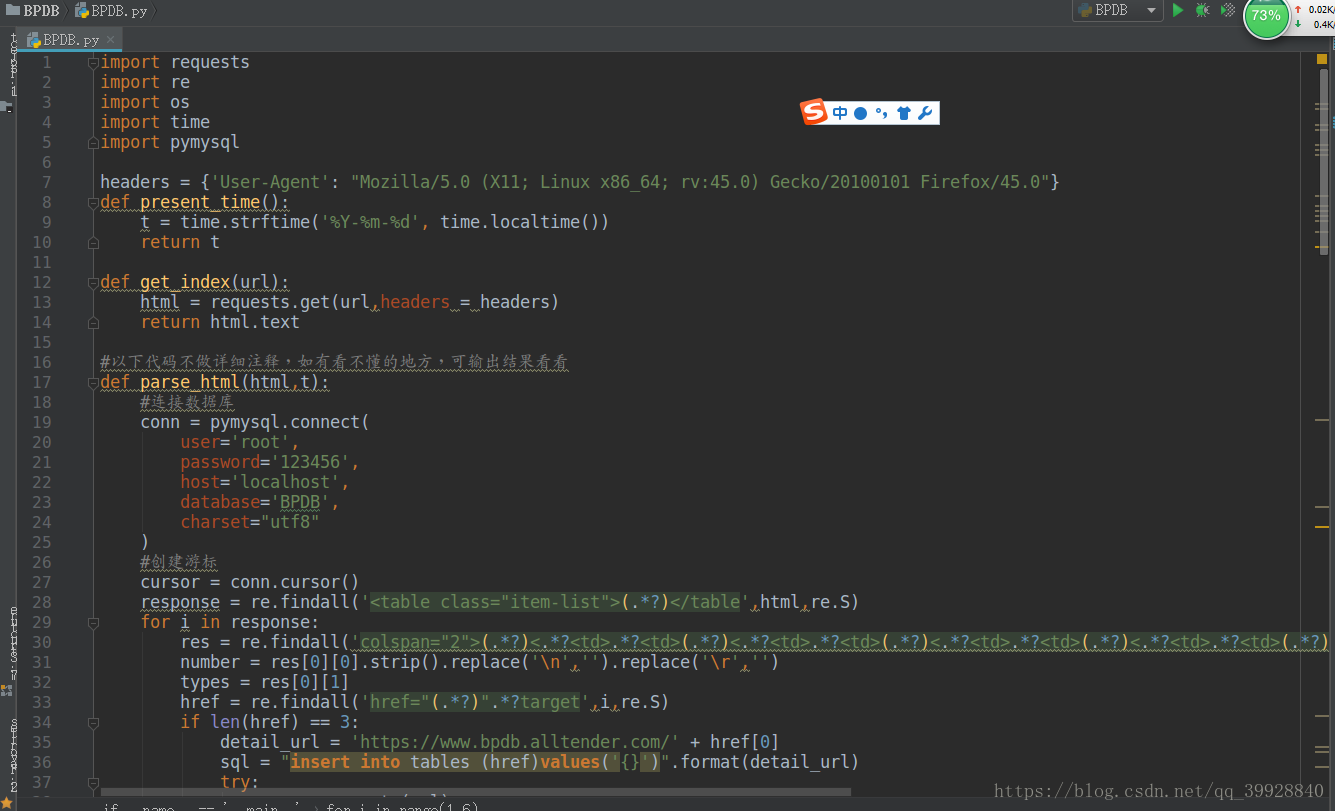
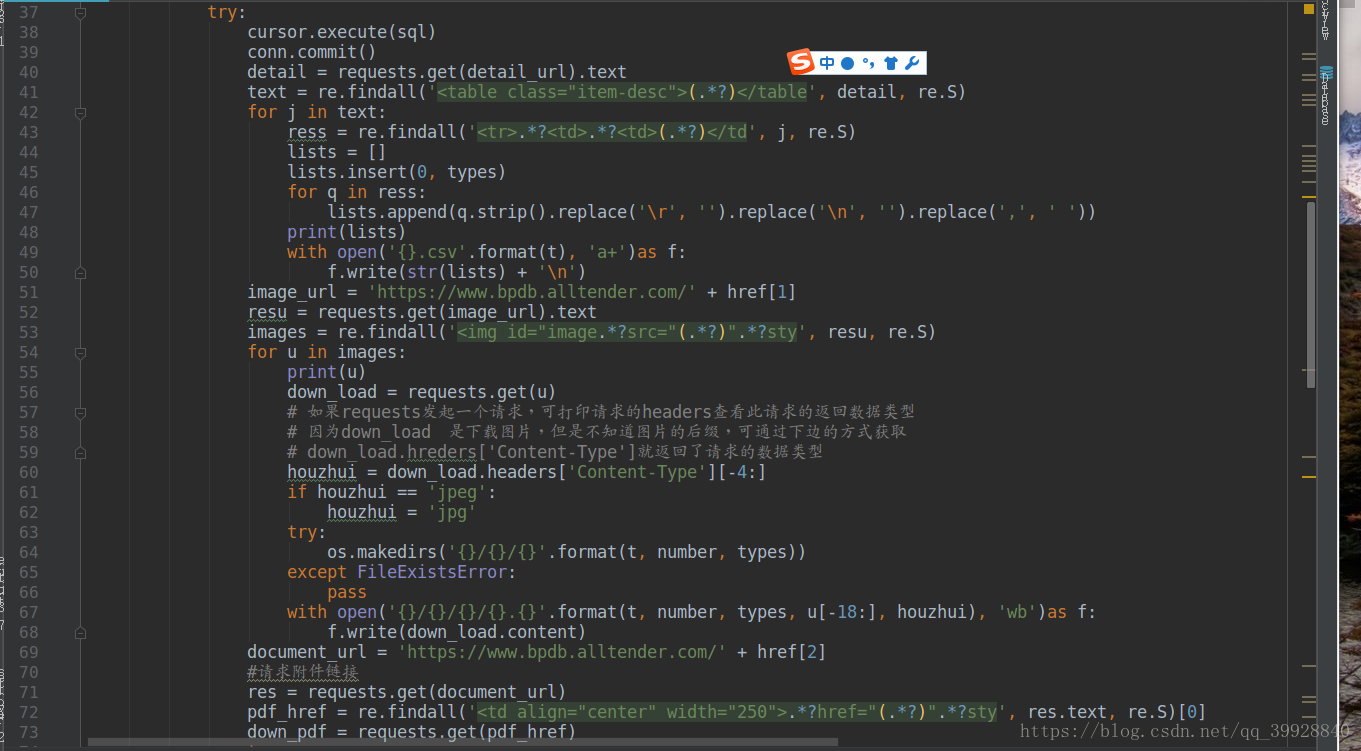
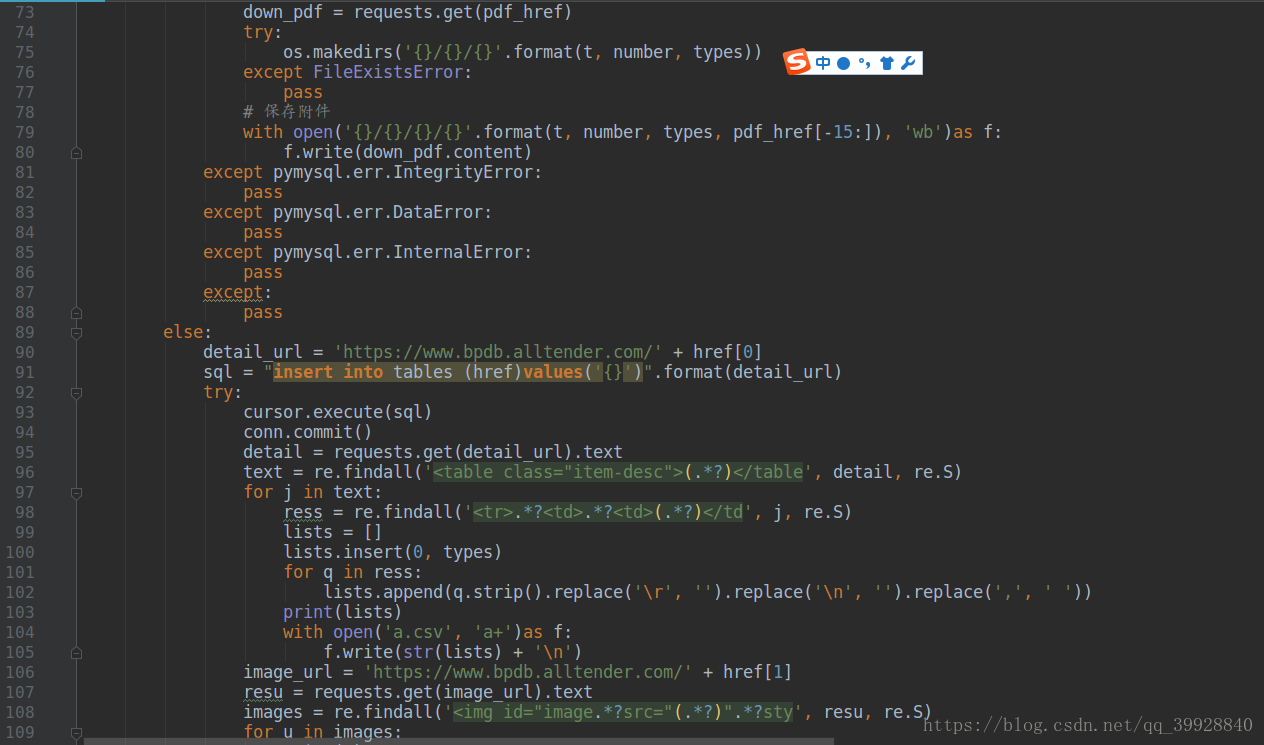
其中有注释的才是需要注意的地方,代码这么多,着重看吧!