我的环境:
系统平台:Ubuntu14.04TLS(64位)
Hadoop环境:Hadoop2.8.3
Eclipse:Neon.2 Release(4.6.2)
Eclipse插件:hadoop-eclipse-plugin-2.8.3.jar
1.先确保已安装了jdk和hadoop,没有的可参考以下两篇文章,已经安装的跳过此步骤
2.安装eclipse,下载对应的hadoop eclipse pulgin插件
注意:Hadoop插件要跟自己安装的Hadoop版本相对应
eclispe官网下载地址
下载的是eclipse-installer文件,打开eclipse-inist,一般选择第一个(根据自己需求)
我的hadoop版本是hadoop2.8.3下载的是hadoop-eclipse-plugin-2.8.3.jar
链接:https://pan.baidu.com/s/1mE5DtURCYKdGUhs0fnhRJg 密码:4cbl
3.在eclipse上安装Hadoop插件并重启eclipse
4.在Eclipse中配置插件
在Eclipse软件中,单击【Windows】-【Preferences】,弹出Preferences对话框,若左侧出现【Hadoop Map/Reduce】选项,则表示插件放置成功。
单击【Hadoop Map/Reduce】选项,并在右侧设置Hadoop的安装目录。
【Windows】-【Open Perspective】-【Other】,弹出对话框,单击蓝色小象【Map/Reduce】,并确定
这时Eclipse下方输出窗口部分,出现【Map/Reduce Locations】选项卡,单击右上角的蓝色小象进行编辑
location name:名称随意填写
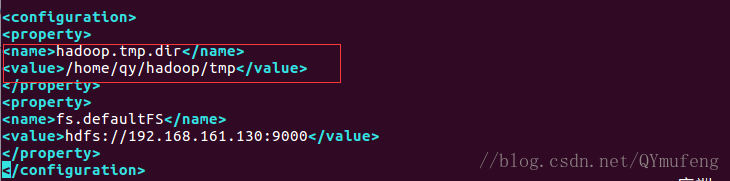
Host与core-site.xml文件里的配置保持一致:
port第一个是9001,第二个是9000
点击Advanced parameters,找到fs.defaultFS
添加fs.defaultFS路径,与core-site.xml文件配置保持一致
找到hadoop.tmp.dir,修改路径,和core-site.xml文件配置保持一致
配置完成之后,记得保存,点击finish
右键刷新hadoop,即可看到连接成功
5.创建hadoop项目,运行Wordcount实例
(1)创建hadoop项目,点击左上角file—>new—>other
(2)选择map/preduce下面的map/preduce project
(3)填写项目名称,点击finish
(4)导入jar包,新建一个文件夹hadoop_jar
将以下jar包直接复制粘贴到此文件夹内
hadoop-2.8.3/share/hadoop/mapreduce下的所有jar包(子文件夹下的jar包不用)
hadoop-2.8.3/share/hadoop/common下的hadoop-common-2.8.3.jar
hadoop-2.8.3/share/hadoop/common/lib下的commons-cli-1.2.jar(5)在项目名称上右键点击Build Path,点击Configure Build Path
(6)点击Libraries,第二步点击Add JARS
(7)选中hadoop_jar下的所有jar包,点击ok
(8)点击Apply and Close,应用并退出
(9)Referenced Libraries库里就多了刚刚添加的几个jar包
(10)新建WordCount类,
WordCount实例api
package lib_test1;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
} (11)上传需要单词计数的文件至hdfs
file1文件内容:
file2的文件内容:
(12)右键运行WordCount实例,选择Run configurations
(13)双击java Application,选择WordCount,点击Arguments,第一个是输入路径,第二个是输出路径(输出文件qy_output是自动创建的,运行实例之前不能有,不然报错),输入输出路径中间以一个空格隔开,点击Apply,最后点击run
(14)运行过程
(15)运行结果