Pandas模块是一个强大的数据分析和处理模块,能为复杂情形下的数据提供坚实的基础分析功能。
所谓的复杂情形,可能有以下三种:
①数据库表或Excel表,包含了多列不同数据类型的数据(如数字、文字)
②时间序列类型的数据,包括有序和无序的情形,甚至是频率不固定的情形
③任意的矩阵型、二维表、观测统计数据,允许独立的行或列带有标签
下面介绍Pandas模块中的基本的高级数据结构,以及Pandas模块中经典的数据分析和处理方法
一。pandas中的高级数据结构
- 序列(Series)
- 数据框(DataFrame)
有了它们,可以利用pandas在计算机内存中构建一个虚拟的数据库。
1. 数据框
| age | cash | id | |
| 0 | 18 | 10.53 | Jack |
| 1 | 35 | 500.70 | Sarah |
| 2 | 20 | 13.60 | Mike |
每列表示一个变量,每行是一次观测,行列交汇的某个单元格,对应该变量的某次具体的观测值。
数据框有行和列的索引(index),能快速地按索引访问数据框的某几行和某几列,在DataFrame里的面向行和面向列的操作大致是对称的。
(1)创建数据框:
常用的方法是用一个包含相等长度列表的字典或NumPy数组来创建。
注意:数据框创建时会根据内置的多种规则对数据进行排序,导致结果的行列位置可能不一样,但数据的对应关系不会出现任何错位。
import pandas as pd
data = {'id': ['Jack', 'Sarah', 'Mike'],
'age': [18, 35, 20],
'cash': [10.53, 500.7, 13.6]}
df = pd.DataFrame(data) # 调用构造函数并将结果赋值给df
print(df)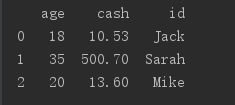
可以在pd.DataFrame中进行参数设置,显示地声明列名排序方式和行索引
df = pd.DataFrame(data, columns=['id', 'age', 'cash'], index=['one', 'two', 'three'])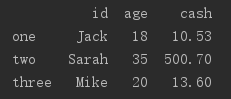
(2)获取数据框中某一列
获取数据框中某一列非常方便,只需要呼唤其名字即可
print(df['id'])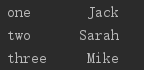
2.系列
系列是对同一属性进行多次观测后得到的一列结果。
用统计学语言说,他们服从某种分布。也可以认为是一种广义的一维数组。
默认情况下,系列的索引是自增的非负整数列(0, 1, 2, 3...)
特别注意的是,同个系列的数据共享一个列名,而数组不要求。
在时间序列的相关问题中,系列这一数据结构有宝贵的价值。
(1)创建系列
s = pd.Series({'a': 4, 'b': 9, 'c': 16}, name='number')
print(s)
(2)按下标访问
print(s[0])
print(s[:2])
(3)按索引访问
print(s['a'])
s['d'] = 25 # 如果系列中没有该键值,则会新增一行(类似字典)
print(s)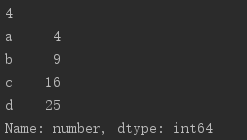
二。基础数据处理方法
作为一种高级数据结构,系列同样支持向量化操作。即能同时对一个系列的所有取值执行同样的操作,一致地应用某种方法。
(1)系列向量化操作
(2)数据框列的查、增、删
数据框可以被看作是一个字典,其中键为系列对应的名字(列名),值为系列所有的观测值,因此增删改查等操作大致相同。
import pandas as pd
data = {'id': ['Jack', 'Sarah', 'Mike'],
'age': [18, 35, 20],
'cash': [10.53, 500.7, 13.6]}
df = pd.DataFrame(data, columns=['id', 'age', 'cash'], index=['one', 'two', 'three']) # 调用构造函数并将结果赋值给df
# 数据框列的增删改查
print(df['id'])
df['rich'] = df['cash'] > 200.0
print(df)
del(df['rich'])
print(df)
此外,pandas还有很多方法,可以参考pandas官方文档。
下面列出pandas常用的方法清单:
