看图说话(Image Caption),就是让计算机对图像进行文字描述,是结合CV和NLP两个领域的一种比较综合的任务,Image Caption模型的输入是一幅图像,输出是对该幅图像进行描述的一段文字。这项任务要求模型可以识别图片中的物体、理解物体间的关系,并用一句自然语言表达出来。
论文:
《Show and Tell: A Neural Image Caption Generator》(arXiv:1411.4555)
《Show and Tell: Lessons learned from the 2015 MSCOCO Image Captioning Challenge》(arXiv:1609.06647)
算法理解:
对于训练集的一张图片 I ,其对应的描述为序列 S={S1,S2,...}(其中 Si 代表句子中的词)。对于模型 θ,给定输入图片I ,模型生成序列 S的概率为
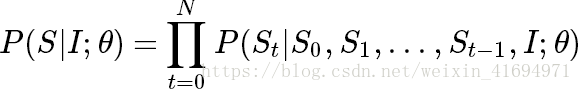
拆解成连乘的形式后,问题就变成了建模条件概率 P(St|S0,S1,...,St−1,I;θ)。通常来说,RNN是当仁不让的第一选择,因为理论上它可以保留全部上文信息(对于“长时依赖”问题,使用LSTM来缓解),而不像 n-gram 或者 CNN 那样只能取一个窗口。
将似然函数取对数,得到对数似然函数:
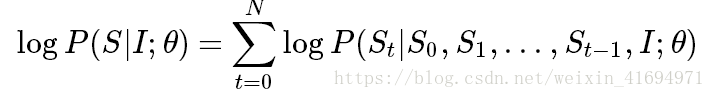
模型的训练目标就是最大化全部训练样本的对数似然之和:

式中 (I,S) 为训练样本。这种极大似然估计的方式等价于使用对数损失函数的经验风险最小化。
训练好模型后,对于生成过程,则是根据输入的一张图片 I,推断出最可能的序列来输出:

当然,计算全部序列的概率然后选出概率最大的序列当然是不可行的,因为每个位置都有词表规模的词作为候选,搜索规模会随序列的长度而指数级增长,所以需要用beam search来缩小搜索空间。这时自然就会联系到自然语言翻译,encoder-decoder架构。
模型结构:

借鉴机器翻译的encoder-decoder:RNN-RNN结构,
encoder采用CNN提取图片特征,预训练模型inceptionV3,将softmax前的固定512维的特征向量取出。成为image-embedding
decoder采用LSTM模型,初始时刻输入image-embedding的特征向量,输入序列S={S1,S2,...}经word-embedding后形成512维词向量。输入LSTM中512个units。目标序列为输入序列右移一个位置。
beam search:搜索局部最优序列算法。减少运算量,可增加描述的丰富性。inference时应用beam search算法,beam size =3
训练:先单训LSTM,到loss在2以下时候,趋于稳定后,再联合CNN一起训练。困惑度(perplexity)来指导调参
代码实现:基于tesorflow/model中的im2txt模型,
数据集使用flickr8k,flickr30k,mscoco数据集,格式要求:tfrecord
数据生成和模型训练,注意config的修改
注意tensorflow不同版本的差异
尝试优化器,steps
inference结果示例:
