手写数字识别
导包
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
#导入knn算法,决策树,逻辑斯蒂回归
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
from IPython.display import display
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
获取数据
#导入数字图片
#特征数据
X = []
#目标数据
y =[]
#一共有10个文件夹(数字0-9),每个有500张图片
#图片命名格式为:0_1.bmp
for i in range(10):
for j in range(1,501):
#读取图片
digit = plt.imread('./digits/%d/%d_%d.bmp'%(i,i,j))
X.append(digit)
y.append(i)
#把列表转成数组
X = np.array(X)
y = np.array(y)
#查看数组形状
X.shape
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
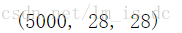
说明一共有5000张照片,像素为28*28。
#随机显示一张图片
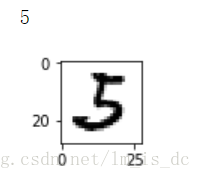
index = np.random.randint(0,5000,size=1)[0]
digit = X[index]
#设置画布宽为1,高为1
plt.figure(figsize=(1,1))
#显示颜色为gray
plt.imshow(digit,cmap='gray')
print(y[index])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
拆分数据
#拆分数据:训练数据和测试数据
from sklearn.model_selection import train_test_split
- 1
- 2
#测试数据占比为0.1
#一共有5000张照片,那么用来做测试的有500张
X_train,X_test,y_train,y_test = train_test_split(X,y,
test_size=0.1)
- 1
- 2
- 3
- 4
X_train.shape
- 1

使用knn算法
#使用knn算法
#使用5个点做比较
knn = KNeighborsClassifier(n_neighbors=5)
#训练数据要为二维数组
#如果不做转换会报如下错误,说3维数组不能做运算
#Found array with dim 3. Estimator expected <= 2
#训练模型
knn.fit(X_train.reshape(4500,-1),y_train)
#对训练后的模型进行评分
knn.score(X_test.reshape(500,-1),y_test)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
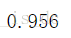
#预测
y_ = knn.predict(X_test.reshape(500,-1))
display(y_[:20],y_test[:20])
- 1
- 2
- 3

使用决策树
# 784个像素---->784个属性-----> 数字不一样
X.reshape(5000,-1).shape
- 1
- 2
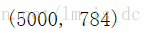
#使用决策树,深度为50
tree = DecisionTreeClassifier(max_depth=50)
#训练模型
tree.fit(X_train.reshape(4500,-1),y_train)
#对训练后的模型进行评分
tree.score(X_test.reshape(500,-1),y_test)
- 1
- 2
- 3
- 4
- 5
- 6
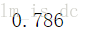
#使用决策树,深度为150
tree = DecisionTreeClassifier(max_depth=150)
#训练模型
tree.fit(X_train.reshape(4500,-1),y_train)
tree.score(X_test.reshape(500,-1),y_test)
- 1
- 2
- 3
- 4
- 5

使用逻辑斯蒂回归
#使用逻辑斯蒂回归
logistic = LogisticRegression()
logistic.fit(X_train.reshape(4500,-1),y_train)
logistic.score(X_test.reshape(500,-1),y_test)
- 1
- 2
- 3
- 4
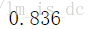
图像可视化
#可视化
#画布大小10行10列
#每行高为1,每列宽为1.5
plt.figure(figsize=(10*1,10*1.5))
for i in range(30):
#绘制子图
axes = plt.subplot(10,10,i+1)
#测试数据为500张,绘制其中的30张
axes.imshow(X_test[i],cmap='gray')
#添加标题
t = y_test[i]
p = y_[i]
axes.set_title('True:%d\nPred:%d'%(t,p))
#不显示坐标刻度
axes.axis('off')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16

手写数字识别
导包
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
#导入knn算法,决策树,逻辑斯蒂回归
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
from IPython.display import display
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
获取数据
#导入数字图片
#特征数据
X = []
#目标数据
y =[]
#一共有10个文件夹(数字0-9),每个有500张图片
#图片命名格式为:0_1.bmp
for i in range(10):
for j in range(1,501):
#读取图片
digit = plt.imread('./digits/%d/%d_%d.bmp'%(i,i,j))
X.append(digit)
y.append(i)
#把列表转成数组
X = np.array(X)
y = np.array(y)
#查看数组形状
X.shape
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
说明一共有5000张照片,像素为28*28。
#随机显示一张图片
index = np.random.randint(0,5000,size=1)[0]
digit = X[index]
#设置画布宽为1,高为1
plt.figure(figsize=(1,1))
#显示颜色为gray
plt.imshow(digit,cmap='gray')
print(y[index])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
拆分数据
#拆分数据:训练数据和测试数据
from sklearn.model_selection import train_test_split
- 1
- 2
#测试数据占比为0.1
#一共有5000张照片,那么用来做测试的有500张
X_train,X_test,y_train,y_test = train_test_split(X,y,
test_size=0.1)
- 1
- 2
- 3
- 4
X_train.shape
- 1
使用knn算法
#使用knn算法
#使用5个点做比较
knn = KNeighborsClassifier(n_neighbors=5)
#训练数据要为二维数组
#如果不做转换会报如下错误,说3维数组不能做运算
#Found array with dim 3. Estimator expected <= 2
#训练模型
knn.fit(X_train.reshape(4500,-1),y_train)
#对训练后的模型进行评分
knn.score(X_test.reshape(500,-1),y_test)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
#预测
y_ = knn.predict(X_test.reshape(500,-1))
display(y_[:20],y_test[:20])
- 1
- 2
- 3
使用决策树
# 784个像素---->784个属性-----> 数字不一样
X.reshape(5000,-1).shape
- 1
- 2
#使用决策树,深度为50
tree = DecisionTreeClassifier(max_depth=50)
#训练模型
tree.fit(X_train.reshape(4500,-1),y_train)
#对训练后的模型进行评分
tree.score(X_test.reshape(500,-1),y_test)
- 1
- 2
- 3
- 4
- 5
- 6
#使用决策树,深度为150
tree = DecisionTreeClassifier(max_depth=150)
#训练模型
tree.fit(X_train.reshape(4500,-1),y_train)
tree.score(X_test.reshape(500,-1),y_test)
- 1
- 2
- 3
- 4
- 5
使用逻辑斯蒂回归
#使用逻辑斯蒂回归
logistic = LogisticRegression()
logistic.fit(X_train.reshape(4500,-1),y_train)
logistic.score(X_test.reshape(500,-1),y_test)
- 1
- 2
- 3
- 4
图像可视化
#可视化
#画布大小10行10列
#每行高为1,每列宽为1.5
plt.figure(figsize=(10*1,10*1.5))
for i in range(30):
#绘制子图
axes = plt.subplot(10,10,i+1)
#测试数据为500张,绘制其中的30张
axes.imshow(X_test[i],cmap='gray')
#添加标题
t = y_test[i]
p = y_[i]
axes.set_title('True:%d\nPred:%d'%(t,p))
#不显示坐标刻度
axes.axis('off')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16