大小端由来
在计算机内存中,通常是以字节(Byte),也就是 8 个位(Bit)为基本存储单元(也有以 16 位为基本存储单元的)。
对于像C++中的char这样的数据类型,占用一个字节的大小,不会产生什么问题。
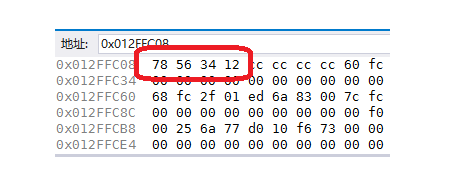
但是当数据类型为int,在32bit的系统中,它需要占用4个字节(32bit),这个时候就会产生这4个字节在寄存器中的存放顺序的问题。比如int maxHeight = 0x12345678,&maxHeight = 0x0042ffc4。具体的该怎么存放呢?这个时候就需要理解计算机的大小端的原理了。
大小端原理
大端:(Big-Endian):就是把数值的高位字节放在内存的低位地址上,把数值的低位字节放在内存的高位地址上。
小端:(Little-Endian):就是把数值的高位字节放在高位的地址上,低位字节放在低位地址上。
大端法和小端法指的是字节在内存中存储时的排列规则,而不是数据中的位的排列规则。也有以位序排列的机器,但很少见。另外,再次明确一下,大端法或小端法是数据在存储时的表现,而不是在寄存器中参与运算时的表现。
union test
{
int num;
char ch;
};
int main()
{
test s;
s.num = 0x12345678;
if (s.ch == 0x78)
cout << "大端机" << endl;
else
cout << "小端机" << endl;
return 0;
}
大小端优缺点
大端模式优点:
- 符号位在所表示的数据的内存的第一个字节中,便于快速判断数据的正负和大小
小端模式优点:
- 内存的低地址处存放低字节,所以在强制转换数据时不需要调整字节的内容(注解:比如把int的4字节强制转换成short的2字节时,就直接把int数据存储的前两个字节给short就行,因为其前两个字节刚好就是最低的两个字节,符合转换逻辑);
- CPU做数值运算时从内存中依顺序依次从低位到高位取数据进行运算,直到最后刷新最高位的符号位,这样的运算方式会更高效
网络通信中的大小端
网络传输中采用的大端标记法,也就是说先传比较高权值的数字, 就像 12一样,先传10,在传2,就算丢了后面一个,损失也不是太大。
如果系统是小端存储,就要通过转换成大端的方式,成为网络字节序。
C/C++中有如下四个常用的转换函数,这四个函数在小端系统中生效,大端系统由于和网络字节序相同,所以无需转换。
- htons —— 把unsigned short类型从主机序转成网络字节序
- ntohs —— 把unsigned short类型从网络字节序转成主机序
- htonl —— 把unsigned long类型从主机序转成网络字节序
- ntohl —— 把unsigned long类型从网络字节序转成主机序
// 头文件
#if defined(_LINUX) || defined(_DARWIN)
#include <netinet/in.h>
#endif
#ifdef WIN32
#include <WINSOCK2.H>
#endif