上一章主要讲述以页为最小单位进行内存分配的伙伴管理算法,较大程度上避免了内存碎片问题。而实际上对内存的申请却不是每次都申请一个页面的(比如文件节点,任务描述符等结构体内存),通常是远小于一个内存页面的大小,此外更可能会频繁地申请释放这些内存。对于这种情况,每次分配小于一个页面的都统一分配一个页面的空间是过于浪费且不切实际的,因此必须充分利用未被使用的空闲空间,同时也要避免过多地访问操作页面分配。基于该问题的考虑,内核需要一个缓冲池对小块内存进行有效的管理起来,于是就有了slab内存分配算法。每次小块内存的分配优先来自于该内存分配器,小块内存的释放也是先缓存至该内存分配器,留作下次申请时进行分配,避免了频繁分配和释放小块内存所带来的额外负载。而这些被管理的小块内存在管理算法中被视之为“对象”
slab/slub/slob(本系统用了slub):
slab是基础,是最早从Sun OS那引进的;
slob是被改进的slab,占用资源少,使用内存较少的嵌入式设备
slub是在slab上进行的改进简化,在大型机上表现出色,并且能更好的适应largeNUMA系统;SLUB相对于SLAB有5%-10%的性能提升和减少50%的内存占用
slab分配器有三个基本目标:
A.减少伙伴系统分配小块内存时所产生的内部碎片
B.把进程使用的对象缓存起来,减少分配、初始化以及释放对象的时间开销
C.调整对象以更好的使用功能L1和L2硬件高速缓存
1、高速缓存
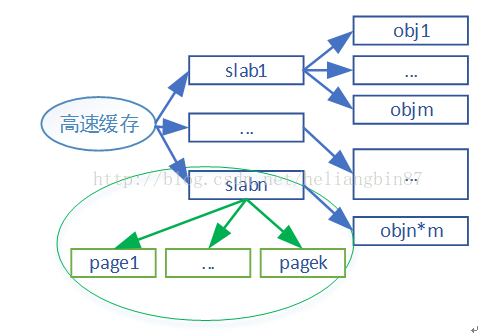
slab分配器形象得说就是先由伙伴算法申请部分空闲内存空间,然后slab按照同样数据类型大小对申请的内存进行分割,最后再用一些数据结构进行管理。这些进行分割后的内存称之为高速缓存。
每一种高速缓存存放相同类型的对象,不同高速缓存组成了slab的高速缓存组,通过链表的形式组织,链表头为slab_caches。通过/proc/slabinfo可以查看当前系统所有的高速缓存:
# name <active_objs><num_objs> <objsize> <objperslab> <pagesperslab> :tunables <limit> <batchcount> <sharedfactor> : slabdata<active_slabs> <num_slabs> <sharedavail>
kmalloc-8192 20 20 8192 4 8 : tunables 0 0 0 : slabdata 5 5 0
kmem_cache_node 192 192 64 64 1: tunables 0 0 0 : slabdata 3 3 0
kmem_cache 128 128 128 32 1 : tunables 0 0 0 : slabdata 4 4 0
name:高速缓存名字
active_objs:正在使用的对象数目
num_objs:总共对象数目
objsize:每个对象大小
objperslab:每个slab对象数目
pageperslab:每个slab需要的pages数目
active_slabs:活动的slab数目
num_slabs:slab数目
从上面可知,每种高速缓存由1个或多个slab组成,而每个slab又有一页或多页组成,最终被划分为n个对象。如图所示:
2、slab
(1)数据结构描述
从上面看高速缓存和slab划分很清晰,实际代码则比较模糊,主要通过kmem_cache的数据结构来描述每种slab。该结构定义如下(include/linux/slub_def.h):
struct kmem_cache {
struct kmem_cache_cpu __percpu *cpu_slab; //per CPU slab结构,用于各个CPU的缓存管理
/* Used for retriving partial slabs etc */
unsigned long flags;
unsigned long min_partial;
int size; /* 对象大小,包括metadata元数据 */
int object_size; /* slab对象纯大小 */
int offset; /* 空闲对象的指针偏移 */
int cpu_partial; /* 每个CPU持有量 */
struct kmem_cache_order_objects oo; //存放分配给slab页框的阶数(高16位)和slab中对象数量(低16位)
/* Allocation and freeing of slabs */
struct kmem_cache_order_objects max;
struct kmem_cache_order_objects min;
gfp_t allocflags; /* 申请页面时使用的GFP标识 */
int refcount; /* 缓冲区计数器,当用户请求创建新的缓冲区时SLUB分配器重用已创建的相似大小的缓冲区从而减少缓冲区个数 */
void (*ctor)(void *); //创建对象的回调函数
int inuse; /* 元数据meta data偏移量 */
int align; /* 对齐值 */
int reserved; /* Reservedbytes at the end of slabs */
const char *name; /* slab缓存名称 */
struct list_head list; /* slabcaches管理链表 */
#ifdef CONFIG_SYSFS
struct kobject kobj; /* Forsysfs */
#endif
struct kmem_cache_node *node[MAX_NUMNODES]; //各个内存管理节点的slub信息
};
其中cpu_slab的结构类型是kmem_cache_cpu,每个CPU类型数据,各个CPU都有自己独立的一个结构,用于管理本地的对象缓存。定义如下:
struct kmem_cache_cpu {
void **freelist; /* 空闲对象队列的指针 */
unsigned long tid; /* Globally unique transaction id 标识CPU,保证只有一个且在正确的CPU上申请 */
struct page *page; /* 指向slab对象来源的内存页面 */
struct page *partial; /* 指向曾分配完所有的对象,但当前已回收至少一个对象的page */
};
node用于管理节点所有对象的slab缓冲区,定义如下:
struct kmem_cache_node {
spinlock_t list_lock;
#ifdef CONFIG_SLUB
unsigned long nr_partial; //本节点的partial slab的数目
struct list_head partial; //partial slab的双向循环队列
#ifdef CONFIG_SLUB_DEBUG
atomic_long_t nr_slabs; //slab总数
atomic_long_t total_objects; //slab对象数目
struct list_head full; //slab full列表
#endif
#endif
};
Slub分配管理中,每个CPU都有自己的缓存管理(即kmem_cache_cpu数据结构管理);而每个node节点也有自己的缓存管理(即kmem_cache_node数据结构管理)。
分配对象:
A.当前CPU缓存有满足申请要求的对象时,将会首先从kmem_cache_cpu的空闲链表freelist将对象分配出去。
B.如果对象不够时,将会向伙伴管理算法中申请内存页面,申请来的页面将会先填充到node节点中,然后从node节点取出对象到CPU的缓存空闲链表中
C.如果原来申请的node节点A的对象,现在改为申请node节点B的,那么将会把node节点A的对象释放后再申请。
释放对象:
A.会先将对象释放到CPU上面,如果释放的对象恰好与CPU的缓存来自相同的页面,则直接添加到列表
B.如果释放的对象不是当前CPU缓存的页面,则会把当前的CPU缓存对象放到node节点上面,然后再把该对象释放到本地的cache中
为了避免过多的空闲对象缓存在管理框架中,slub设置的阈值,如果空闲对象个数达到了峰值,将会把当前缓存释放到node节点中,当node节点也过了阈值,将会把node节点的对象释放到伙伴管理算法中。
其实现框图如下:

(2)slab初始化
在start_kernel中mm_init的kmem_cache_init实现了slab的初始化,它是在实现伙伴算法之后进行初始化。kmem_cache_init在slab.c、slob.c和slub.c都有实现,不同算法其初始化各异,本系统主要用了slub分配算法,因此这里分析slub.c中的实现。其代码原型如下:
void __init kmem_cache_init(void)
{
static __initdata struct kmem_cache boot_kmem_cache,
boot_kmem_cache_node;
if (debug_guardpage_minorder())
slub_max_order = 0;
/*由于在这之前只是初始化好伙伴算法,因而无法使用slab分配高速缓存kmem_cache结构体。这里使用定义了一个静态变量变量boot_kmem_cache_node和boot_kmem_cache来临时管理slab。kmem_cache:主要用于kmem_cache_create创建高速缓存时,从该高速缓存分配对象kmem_cache,描述待创建的高速缓存 */
kmem_cache_node = &boot_kmem_cache_node;
kmem_cache = &boot_kmem_cache;
/* 函数用于创建分配算法缓存,主要是把上面两个变量结构初始化 */
create_boot_cache(kmem_cache_node, "kmem_cache_node",
sizeof(struct kmem_cache_node), SLAB_HWCACHE_ALIGN);
register_hotmemory_notifier(&slab_memory_callback_nb);
/* Able to allocate the per node structures */
slab_state = PARTIAL;
create_boot_cache(kmem_cache, "kmem_cache",
offsetof(struct kmem_cache, node) +
nr_node_ids * sizeof(structkmem_cache_node *),
SLAB_HWCACHE_ALIGN);
/*上面临时初始化后就可以进行slab分配kmem_cache对象。该函数主要作用是将临时kmem_cache和kmem_cache_node向最终的迁移,并修正相关指针,使其指向最终的kmem_cache和kmem_cache_node,并将两者添加到slab_caches全局链表中*/
kmem_cache = bootstrap(&boot_kmem_cache);
kmem_cache_node = bootstrap(&boot_kmem_cache_node);
/* Now we canuse the kmem_cache to allocate kmalloc slabs */
/* 初始化一批后期内存中需要用到的不同大小的slab缓存(即kmalloc),可以通过/proc/slabinfo查看当前kmalloc支持的大小{64,128,192,256,512,1024,4096,8192} */
create_kmalloc_caches(0);
#ifdef CONFIG_SMP
register_cpu_notifier(&slab_notifier);
#endif
printk(KERN_INFO
"SLUB: HWalign=%d, Order=%d-%d, MinObjects=%d,"
" CPUs=%d, Nodes=%d\n",
cache_line_size(),
slub_min_order, slub_max_order, slub_min_objects,
nr_cpu_ids, nr_node_ids);
}
上面初始化完后,就可以创建自己的高速缓存,可以只用kmalloc申请内存空间。
(3)操作函数
A.kmem_cache_create
创建一个新的高速缓存
B.kmem_cache_destroy
销毁一个高速缓存
C.kmem_cache_alloc
从高速缓存中分配对象,当高速缓存中空间不足时,会调用alloc_slab_page申请一个新的slab页。
D.kmem_cache_free
释放一个对象
(4)slab着色
在slub分配算法中已经看不到着色相关信息,也可能是水平有限未找到。但是这里还是讲一下slab着色原理,有助于对硬件cache理解。
假定L1 data cache为32K,cache line32B,就有1024个cache line(指一次性可以读取/写入的数据量)。CPU访问时先访问硬件cache,没有命中时才访问内存。
硬件cache对应到内存的位置不是任意的:
cache line0 对应到内存地址:0~31,32K~32K+31,…
cache line1 对应到内存地址:32~63,32K+32~32K+63,…
cache line2 对应到内存地址:64~95,32K+64~32K+95,…
…
cache line1023 对应到内存地址:32736~32767,32K+32736~32K+32767,…
从上可以看出假定slab对象A在0地址,对象B在32地址,而对象C在32K地址,那么对象A和对象C则会使用相同的硬件cacheline0,如果频繁的访问A和C那么就会不停的切入和换出A和C,导致命中效率低下。所谓着色就是将C进行偏移存放在cache line2,这样就不会进行频繁切换,提高命中效率。当然如果cache已经用完,那么进行着色也无济于事。
3、kmalloc和kfree
kmalloc是基于slab/slob/slub分配算法上实现,如前面章节描述kmalloc存在不同固定大小的kmalloc-N的高速缓存。kmalloc在slab/slob/slub上都有实现,这里主要描述slub的实现方式:
static __always_inline void *kmalloc(size_tsize, gfp_t flags)
{
if (__builtin_constant_p(size)) { //gcc内建函数,用于判断一个值是否为编译时常量
if (size > KMALLOC_MAX_CACHE_SIZE) //大于8192(即kmalloc最大cache)通过kmalloc_large函数申请,该方式通过__get_free_pages接口,即通过buddy伙伴算法申请所需内存空间(默认最大是8M)
return kmalloc_large(size, flags);
if (!(flags & GFP_DMA)) {
int index = kmalloc_index(size);
if (!index)
return ZERO_SIZE_PTR;
//如果<=8192则通过kmalloc cache进行分配
return kmem_cache_alloc_trace(kmalloc_caches[index],
flags, size);
}
}
return__kmalloc(size, flags);//也是上面的结合,只是在size非常量情况下。
}
size为表示申请的空间大小,而flags则表示分配标志。分配标志众多,每个标志标识特定的bit位,可以通过|进行组合,常见的有如下:
GFP_KERNEL:首选标志,内核内存分配,会阻塞引起睡眠
GFP_ATOMIC:不会引起睡眠,但会使用紧急内存池,一般用于中断处理等不能睡眠的地方
从上可以看出kmalloc实现较为简单,分配说的的内存不仅虚拟地址是连续空间,物理地址上也是连续空间。
kfree则是用于释放有kmalloc申请的内存块,在slab/slob/slub都有对应的实现,这里主要展示slub的实现:
void kfree(const void *x)
{
struct page *page;
void *object = (void *)x;
trace_kfree(_RET_IP_, x);
if (unlikely(ZERO_OR_NULL_PTR(x))) //判断是否为NULL
return;
page = virt_to_head_page(x); //将虚拟地址转化成对应的页地址
if (unlikely(!PageSlab(page))) { //是否属于slab管理页,不属于则进入if处理
BUG_ON(!PageCompound(page));
kmemleak_free(x); //对该虚拟地址进行释放前处理
__free_memcg_kmem_pages(page, compound_order(page)); // 调用__free_pages释放页到伙伴算法管理里
return;
}
//如果属于slab管理页,就使用slab方式释放对象
slab_free(page->slab_cache, page, object, _RET_IP_);
}
如果释放的内存不是kmalloc分配的,或者想要释放的内存早就被释放了,那么调用该函数会导致严重的后果。注意,调用kfree(NULL)是安全的。