外键、联合查询和子查询
-
外键
-
概念:
-
foreign key 外面的键(键不在自己的表中),如果说一张表中有一个字段(非主键)指向另外一张表中的主键,那么就将该字段称之为外键。
-
增加外键
一张表可以有多个外键
-
可以在创建表的时候创建外键
在所有表的字段之后,使用foreign key(外键字段) references 外部 表(主键字段)
-
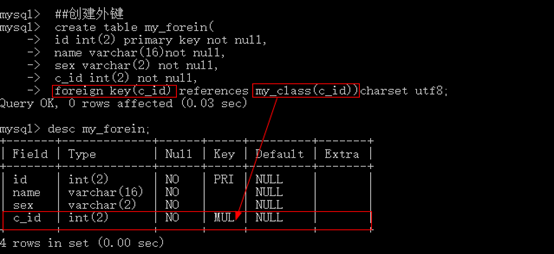
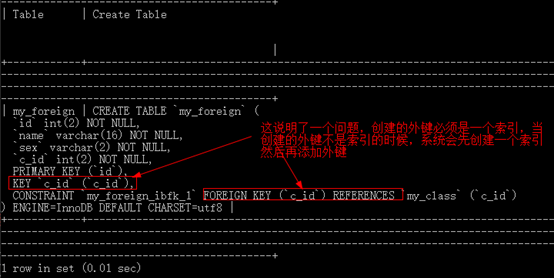
-
可以在创建表之后创建外键:修改表结构
Alter table 表名 add [constraint] foreign key(外键字段)references 父表(主键字段);
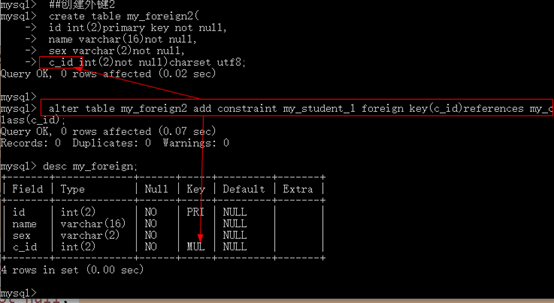
-
修改&删除外键
外键不可修改,只能先删除后添加。
-
删除外键
Alter table 表名 drop 外键名, drop key 外键名; 这样删除外键才比较彻底,如果不加上 drop key 外键名 的话就会保留该索引而仅仅是删除了外键。
-
-
外键存在的条件:
- 保证表的存储引擎是innodb(mysql默认的存储引擎),如果不是,那么外键的创建不会失败,但是没有任何的约束效果。
- 外键字段的字段类型必须与父表的主键类型完全一致。
- 一张表中,外键的名字是不能重复的。
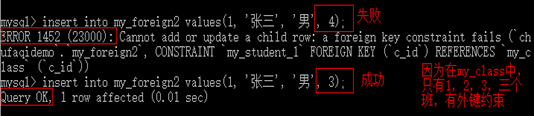
- 增加的外键字段(数据已经存在),必须保证数据与父表主键要求对应。也就是说,当子表中数据已经存在3班,而我们要创建的外键所对应的父表的主键所有记录中没有3班时,那么创建外键会失败。
注意:任何外键创建的失败,都不会提示出错的具体位置,那么我们就必须首先保证上述的条件成立。
-
外键的作用
-
默认的作用:
A:对父表:父表的数据进行写入操作的时候(删和改都必须涉及到主键本身,如果不是主键本身的话,那么对子表表没有任何的影响),如果外键中的某条数据的主键内容已经被子表引用的话,数据的删改会失败。
B:对子表:子表在进行数据写入的时候,如果对应在外键的字段找不到对应的匹配,那么操作会失败。
-
外键约束
所谓外键的约束,就是指外键的作用,上面讲的作用是指外键默认的约束。
但是这里所讲的外键约束是自定义的约束作用,我们可以通过外键的需求,进行定制的操作。
外键约束有三种约束模式(都是针对父表的约束):
模式一: district 严格约束(默认的 ),父表不能删除或者更新已经被子表数据引用的记录
模式二:cascade 级联模式:父表的操作,对应的子表关联的数据也跟着操作 。
模式三:set null:置空模式,父表操作之后,子表对应的数据(外键字段)也跟着被置空。
通常的一个合理的约束模式是:删除的时候子表置空;更新的时候子表级联。
指定模式的语法:foreign key(外键字段)references 父表(主键字段)on delete 模式 on update 模式;
注意:删除置空的前提条件是 外键字段允许为空,不然外键会创建失败。
外键虽然很强大,能够进行各种约束,但是对于java web来讲,外键的约束降低了数据的可控性。通常在实际开发时,很少使用外键来约束。
-
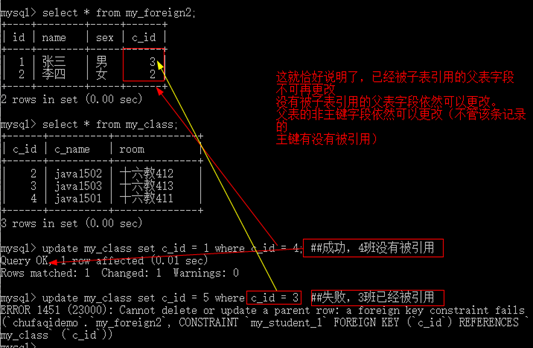
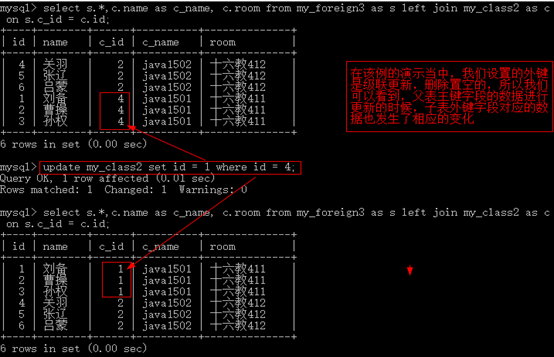
-
联合查询
-
概念:
-
将多次查询(多条select 语句),在记录上进行拼接(字段不会增加)
基本语法:多条select 语句构成,每一条select语句获取的字段数必须严格一致(但是与字段类型无关)
Select语句1
Union [union选项]
Select语句2 …….
Union 选项
A:all 保留所有(不管重复)
B:distinct 去重(整个重复):默认的
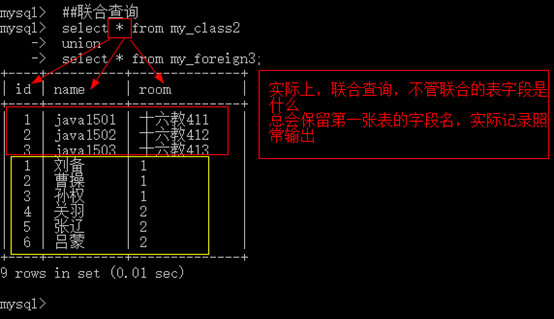
-
联合查询的意义
联合查询不在于我们可以随意的拼凑数据,真正的意义是:
-
查询同一张表,但是需求不同:
如查询学生信息,男生身高升序,女生升高降序。
-
多表查询
多张表的结构是完全一样的,保存数据的结构也是一样的
-
-
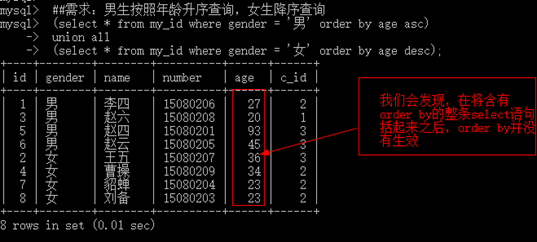
在联合查询中的order by
- 在联合查询中order by不能直接使用,需要将整条select语句用小括号阔气来才能使用
- 若要order by 生效,就必须使用limit

-
子查询
-
概念:
-
sub query ,查询是在某个查询结果智商的进行的(一条select 语句内部包含一条select语句)
-
分类:
按位置分类,按结果分类
-
按位置分类:
子查询(select语句)在外部查询()select语句中出现的位置
Form子查询:子查询跟在from之后
Where子查询:子查询在where条件中
Exists子查询:子查询出现在exists里面。
-
按结果分类:
根据子查询的结果进行分类(理论上讲任何一个查询的得到的结果都可以理解为二维表)
标量子查询:子查询得到的结果是一行一列
列子查询:子查询得到的结果是一列多行
行子查询:子查询得到的结果是多列一行
以上查询的结果都是在where之后
表子查询:子查询得到的结果是多列多行
-
标量子查询
需求:知道了班级名字为java1501,想获取该班的所有学生
-
确定数据源:获取所有学生id
Select * frommy_id where c_id = ?;
-
获取班级id,可以通过班级名字来确定,这条子查询语句就是一个标量子查询
Select * from my_class where c_name = 'java1501';

-
列子查询
-
需求:
查询所有在读班级的学生
-
步骤
-
-
确定数据源 学生
Select * from my_id where c_id in(?);
-
确定有效班级的id 即所有班级的id
Select c_id from my_class;
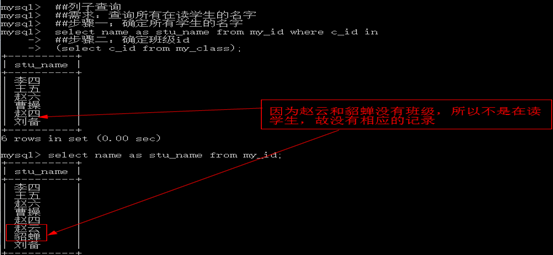
如果说,班级表里面没有二班,而my_id表里面有学生是二班的,那么该学生最终也不会出现在查询的记录当中。
注意:列子查询返回的结果会比较多,需要使用in作为条件匹配,其实msql中还有几个类似的条件:all,some,any
=any óin;其中的一个;
Any ó some;
=all ó为全部
肯定句:
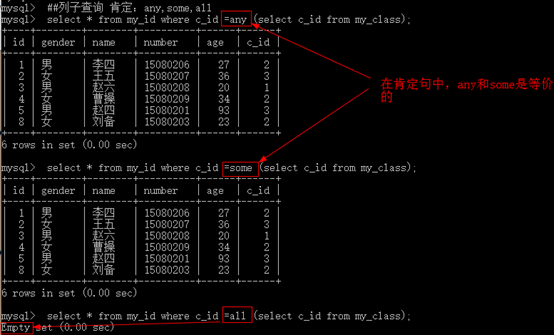
注意:因为我们的my_id中,能满足c_class表中的所有班级id的数据并不存在,所以我们查找到的数据是空数据。
否定句:

-
行子查询
-
概念:
返回的结果可以是多行多列(一行多列)
需求:要求查询整个学生当中年龄最大且班级性别是男的学生
-
步骤
-
-
确定数据源:
Select * from my_id where age = ? and height = ? ;
-
确定最大年龄和身高
Select max(age) and sex = '男'from my_id;
行子查询:我们需要构造行元素
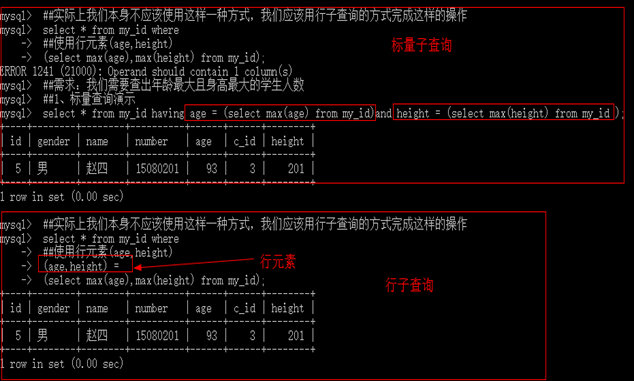
行元素:我们标量查询中的两个字段转化为一个行元素,这样我们查询的内容就仅局限于一个元素,而不是两个元素。
-
表子查询
-
概念:
子查询的一个结果返回的是一个多行多列的二维表,是因为子查询返回的结果是当作一个二维表来使用。
From 子查询 : 将子查询得到的结果当作from数据源
-
需求:
找出每个班中最高的一个学生
-
步骤
-
-
确定数据源,先将学生按照身高降序排序
Select * from my_id oder by height desc;
-
从每个班选出第一个学生
Select * from my_id group by c_id;
-
综上:select * from my_id group by c_id order by height;
但是这样查询出来的数据是不符和我们所需要的数据的,因为我们会发现我们获取到的数据是有错误的。那么我么应该怎么做呢?
我们应该先对数据排序,再进行分组,这样我们获取到的数据就是我们想要的结果。
Select * from (select * from my_id order by height desc) group by c_id;这样看上去数对的,但是系统依然会提示错误。因为表子查询出来的语句是需要一个别的。正确实例如下:
Select from (select * from my_ id order by height desc)as student group by c_id;
-
Exists子查询
-
概念:
是否存在的意思,就是用来判断复合某个条件的记录是否满足,exists 是接在where语句之后的,而这种操作一般是用来进行跨表查询的。Exists返回的结果只有0和1;
-
需求:
查询所有的学生,前提条件是班级存在,就是不为空。
-
步骤
-

-
确定数据源
Select * from my_id where ?;
-
确定条件是否满足
Exists(select * from my_class);
值得注意的是:exists 语句只是判断数据是否存在,存在就会将 主句 select 后面所要查询的数据全部打印出来。
-
注意事项
- 我们应当注意到,不管order by 语句是否在group by 语句之前,group by语句是一定会在order by 之前执行的。在上述查询的实例中"查询每个班级的身高最高的学生" 简单的用order by 与 group by 组合的方式来进行查询实际上order by 语句是没有起到任何的作用的;
- 上述所有的查询方式,实际上是不存在这种分类的,那些分类只是我们认为的将之规范起来的,所以在实际应用的开发中是没有这些分类的,我们只是根据实际的查询需要选择我们的查询方式的。