SqueezeNet 发表于ICLR-2017,作者分别来自Berkeley和Stanford,SqueezeNet不是模型压缩技术,而是 “design strategies for CNN architectures with few parameters”
创新点:
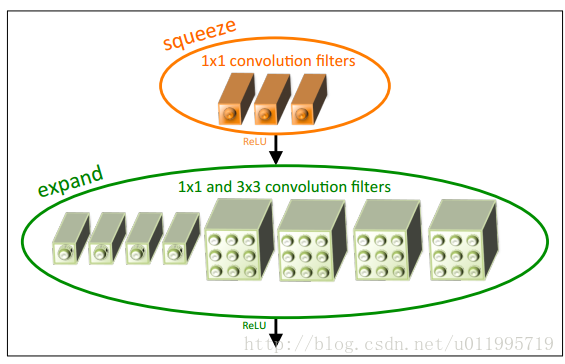
1. 采用不同于传统的卷积方式( 类似于inception思想) ,提出fire module;fire module包含两部分分:squeeze层+expand层
创新点inception的思想太接近,应该不算是突破性的。首先squeeze层,就是1*1卷积,其卷积核数要少于上一层feature map数,这个操作从inception系列开始就有了,并称之为压缩,但我觉得“压缩”更为妥当。
Expand层用1*1 和3*3 分别卷积,然后concat,这个操作再inception系列里面也有啊。。。
——————————————分割线————————————-
SqueezeNet的核心在于Fire module,Fire module 由两层构成,分别是squeeze层+expand层,如下图所示,squeeze层是一个1*1卷积核的卷积层,expand层是1*1 和3*3卷积核的卷积层,expand层中,把1*1 和3*3 得到的feature map 进行concat,具体操作如下图2所示
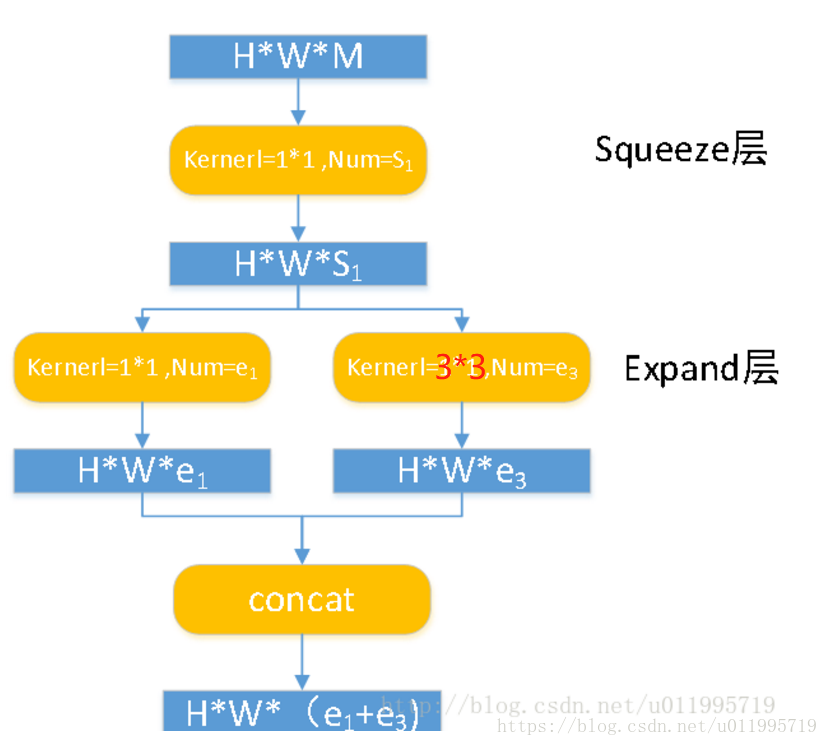
Fire module输入的feature map为H*W*M的,输出的feature map为H*M*(e1+e3),可以看到feature map的分辨率是不变的,变的仅是维数,也就是通道数,这一点和VGG的思想一致。
首先,H*W*M的feature map经过Squeeze层,得到S1个feature map,这里的S1均是小于M的,以达到“压缩”的目的,详细思想可参考Google的Inception系列。
其次,H*W*S1的特征图输入到Expand层,分别经过1*1卷积层和3*3卷积层进行卷积,再将结果进行concat,得到Fire module的输出,为 H*W*(e1+e3)的feature map。
fire模块有三个可调参数:S1,e1,e3,分别代表卷积核的个数,同时也表示对应输出feature map的维数,在本文提出的SqueezeNet结构中,e1=e3=4s1
接下来看squeezenet.网络结构:

首先经过conv1,之后是fire2-9,最后是一个conv10,最终采用global avgpool代替FC层进行输出;
更详细参数如下图所示:

看看squeezenet与alexnet的对比:

这里采用了deep compression技术,对squeezenet进行了压缩,最终才会得到0.5M的模型,并且模型性能还不错;
Deep compression是ICLR-2016 best paper!详细见:
(https://arxiv.org/pdf/1510.00149.pdf)
看了上图再回头看一看论文题目:
SqueezeNet :AlexNet-level accuracy with 50x fewer parameters and <0.5MB
Squeezenet比alexnet参数少50倍,这个没问题,上图倒数第三行可见;但是, and < 0.5MB, 这个和squeezenet完全没关系啊!是用了别的技术获得的。很容易让人误以为squeezenet可以压缩模型!!