一、实验原理:
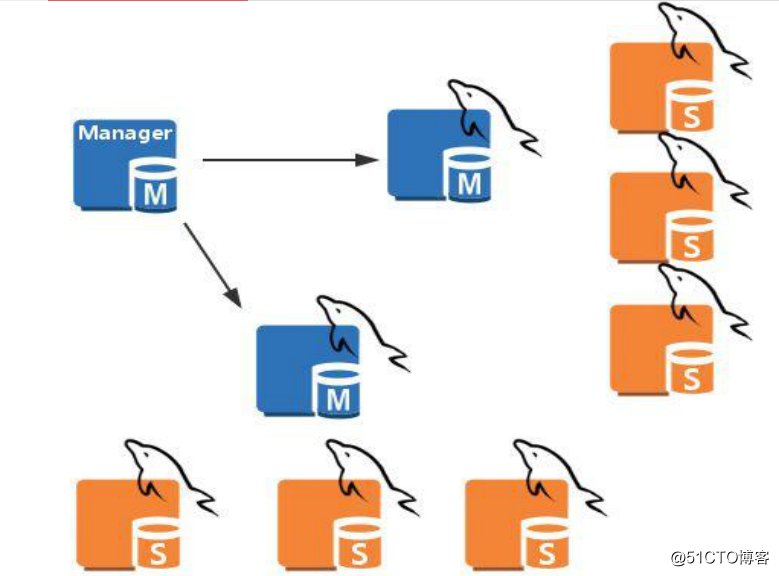
1、拓扑结构图如下:
2、工作原理:
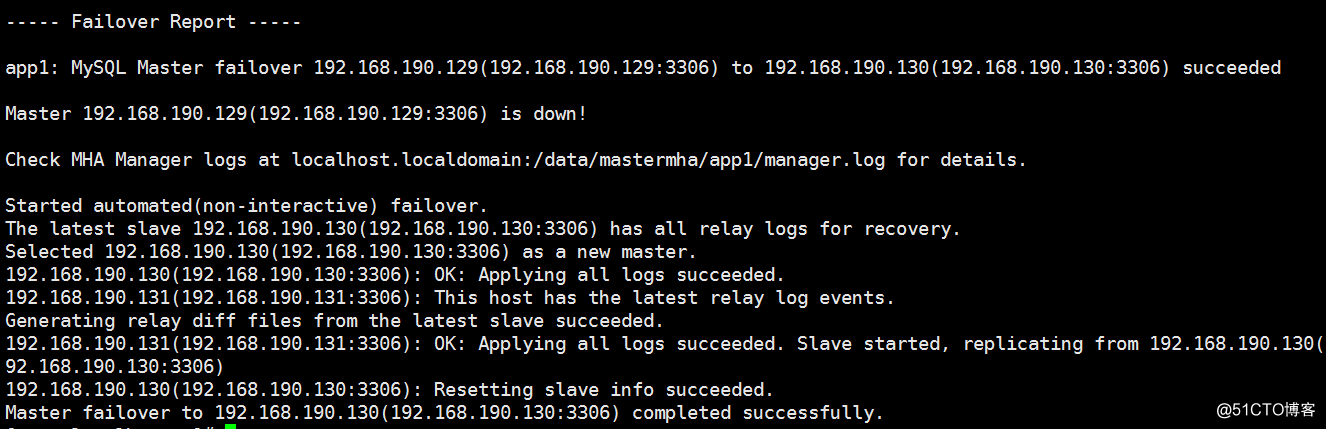
从宕机崩溃的master保存二进制日志事件(binlog events)
识别含有最新更新的slave
应用差异的中继日志(relay log)到其他的slave
应用从master保存的二进制日志事件(binlog events)
提升一个slave为新的master
使其他的slave连接新的master进行复制
3、工具包:
MHA软件由两部分组成,Manager工具包和Node工具包
1、 Manager工具包主要包括以下几个工具:
masterha_check_ssh 检查MHA的SSH配置状况
masterha_check_repl 检查MySQL复制状况
masterha_manger 启动MHA
masterha_check_status 检测当前MHA运行状态
masterha_master_monitor 检测master是否宕机
masterha_master_switch 故障转移(自动或手动)
masterha_conf_host 添加或删除配置的server信息
2、Node工具包:这些工具通常由MHA Manager的脚本触发,无需人为操作)主要包括以下几个工具:
save_binary_logs 保存和复制master的二进制日志
apply_diff_relay_logs 识别差异的中继日志事件并将其差异的事件应用于其他的slave
filter_mysqlbinlog 去除不必要的ROLLBACK事件(MHA已不再使用此工具)purge_relay_logs 清除中继日志(不会阻塞SQL线程)
二、实验环境准备:
1、vmware中准备四台虚拟主机
主机名分别为manager,master,slave1,slave2 系统为centos7
对应ip:192.168.190.128-131
2、setenforce 0 关掉selinux
iptables -F 清掉防火墙
3、配置好yum源,以及epel源
4、四台虚拟主机保证时间同步,ntpdate命令
三、实验步骤:
1、四台主机实现ssh无密连接
ssh-keygen 任意一台主机生成公钥私钥对
ssh-copy-id 192.168.190.128 生成文件在.ssh目录
scp -r /root/.ssh 192.168.190.129
scp -r /root/.ssh 192.168.190.130
scp -r /root/.ssh 192.168.190.131
2、manager节点
(1) yum install mha4mysql-manager-0.56-0.el6.noarch.rpm mha4mysql-node-0.56-0.el6.noarch.rpm
(2) mkdir /data/mastermha/app1/ -pv
(3)vim /etc/mastermha/app1.cnf
[server default]
user=mhauser 主服务器的管理账号
password=centos mhauser的密码
manager_workdir=/data/mastermha/app1/ 工作目录
manager_log=/data/mastermha/app1/manager.log 日志目录
remote_workdir=/data/mastermha/app1/
ssh_user=root ssh连接账号
repl_user=repluser 复制账号
repl_password=centos 复制账号的密码
ping_interval=1
[server1]
hostname=192.168.190.129 主服务器
candidate_master=1 有机会晋升为主
[server2]
hostname=192.168.190.130 从服务器
candidate_master=1 有机会晋升为主
[server3]
hostname=192.168.190.131 从服务器
candidate_master=1 有机会晋升为主
3、master,slave1,slave2节点
yum install mha4mysql-node-0.56-0.el6.noarch.rpm
4、master节点
(1)systemctl start mariadb
(2)vim /etc/my.cnf
log-bin 启用二级制
server_id=1 服务器id,每个节点必须不同
innodb_file_per_table 每个库,每张表
skip_name_resolve=1 通过ip连接,不解析主机名
log_slave_updates = 1 主从切换时用
plugin_load = "rpl_semi_sync_master=semisync_master.so;rpl_semi_sync_slave=semisync_slave.so" 加载半同步复制的插件,主从的都装,主坏,从顶上时实现半同步
loose_rpl_semi_sync_master_enabled = 1 开启主的半同步功能
loose_rpl_semi_sync_slave_enabled = 1 开启从的半同步功能
loose_rpl_semi_sync_master_timeout = 5000
mysql
mysql>show master logs
mysql>grant replication slave on *.* to repluser@'192.168.31.%' identified by ‘centos';
mysql>grant all on *.* to mhauser@‘192.168.190.%’ identified by ‘magedu‘;
show variables like '%semi%';5、slave1节点和slave2节点
vim /etc/my.cnf
[mysqld]
server_id=2 不同节点此值各不相同
log-bin
read_only 只读,对超级用户无效,主坏切换为主时,全局变量会变
relay_log_purge=0 不删除中继日志
skip_name_resolve=1 不解析主机名,通过ip连接
plugin_load = "rpl_semi_sync_master=semisync_master.so;rpl_semi_sync_slave=semisync_slave.so" 加载半同步复制的插件,主从的都装,主坏,从顶上时实现半同步
loose_rpl_semi_sync_master_enabled = 1 开启主的半同步功能
loose_rpl_semi_sync_slave_enabled = 1 开启从的半同步功能
loose_rpl_semi_sync_master_timeout = 5000
mysql>CHANGE MASTER TO MASTER_HOST=‘MASTER_IP', MASTER_USER='repluser', MASTER_PASSWORD=‘centos', MASTER_LOG_FILE='mariadb-bin.000001', MASTER_LOG_POS=245;6、 manager节点上进行测试
1、masterha_check_ssh --conf=/etc/mastermha/app1.cnf 检测ssh连通性
2、masterha_check_repl --conf=/etc/mastermha/app1.cnf 检测复制功能
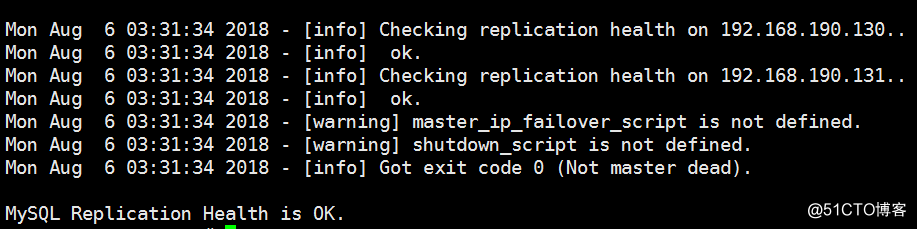
3、masterha_manager --conf=/etc/mastermha/app1.cnf 启动mha管理
4、停掉主节点的mariadb服务,查看对应的日志