ajax 爬虫 网址http://www.doyo.cn/tu
下拉网页
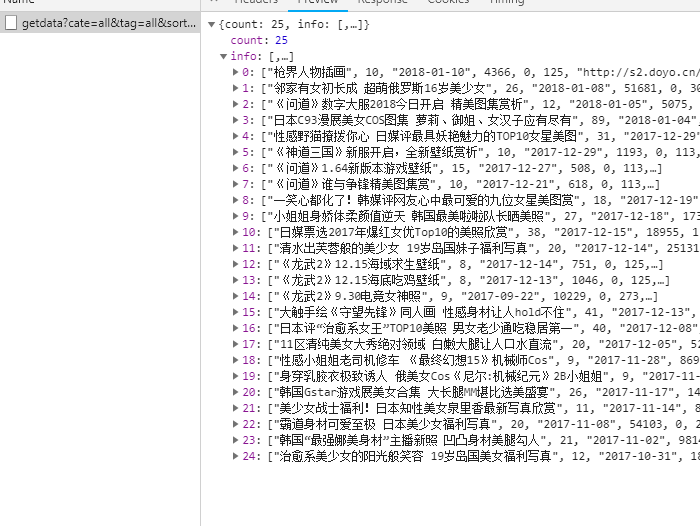
代码:
# coding=utf-8 import random import time from multiprocessing import Pool import requests from requests.exceptions import RequestException import json import os import re # <img src="http://s2.doyo.cn/img/5a/0a/684c9e9e780a3000002e.jpg" id="big_picture"> pattern = re.compile('<img src="(.*?)" id="big_picture" />', re.S) headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/65.0.3325.146 Safari/537.36 " } data_url = 'http://www.doyo.cn/tu/getdata' root_url = 'http://www.doyo.cn/picture/{number}/{index}/view' try: os.mkdir('mm') os.chdir('mm') except: pass parent_path = os.getcwd() j = open('picinfo.json', 'w', encoding='utf-8') def get_one_page(start): params = { "cate": "all", "tag": "all", "sort": "updatetime", "start": "0", "count": start } try: response = requests.get(url=data_url, params=params) if response.status_code == 200: return response.text return None except RequestException: print("NetWork Error") def get_one_data(html): data = json.loads(html) if data and 'info' in data.keys(): for info in data.get('info'): yield { 'title': info[0], 'count': info[1], 'pic': info[6], 'number': info[7] } def write_to_file(res): os.chdir(parent_path) j.write(json.dumps(res, ensure_ascii=False) + '\n') def get_img_urllist(res): # root_url = 'http://www.doyo.cn/picture/{number}/{index}/view' for index in range(1, int(res.get('count')) + 1): yield root_url.format(number=res.get('number'), index=index) def save_img(res): os.chdir(parent_path) try: os.mkdir(res.get('title')) os.chdir(res.get('title')) except: pass url_list = get_img_urllist(res) for imag_url in url_list: url = get_img_url(imag_url) print(url) try: filename = str(random.random()) time.sleep(0.1) response = requests.get(url, headers=headers) with open(filename + '.jpg', 'wb') as f: f.write(response.content) except: pass def get_html(url): try: response = requests.get(url, headers=headers) if response.status_code == 200: return response.text else: return None except RequestException: print("connection error") def get_img_url(imag_url): html = get_html(imag_url) res = re.search(pattern=pattern, string=html) if res: return res.group(1) def main(start): html = get_one_page(start) res = get_one_data(html) for each in res: write_to_file(each) save_img(each) if __name__ == '__main__': start = [n * 25 for n in range(0, 1)] for i in start: main(i) j.close()