背景介绍:
超分辨率的目标是将输入的低分辨率图像(画质较差、像素低)输出为高分辨率图像,如输入256×256pixels大小的低分辨率lr图像,输出512×512pixels大小的超分辨率super resolution的图像。因为需要评估算法的性能,所以还会涉及到原图的高分辨率hr图像。
作者介绍:
汤晓鸥教授和何凯明团队的文章,在深度卷积网络的浪潮下,提出的端对端的超分辨率算法。该算法简称为SRCNN,后续还会对基于Sub-Pixel优化的超分辨率算法,以及SRCNN提出的优化算法FSRCNN算法进行笔记总结。
一、算法流程概述
SRCNN是首个使用CNN结构的端到端的超分辨率算法。首先,输入预处理。对输入的低分辨率lr图像使用bicubic算法进行放大,放大为目标尺寸。那么接下来算法的目标就是将输入的比较模糊的lr图像,经过卷积网络的处理,得到超分辨率sr的图像,使它尽可能与原图的高分辨率hr图像相似。
令F为训练模型的目标函数,输入低分辨率图像Y,经过该函数的处理F(Y),得到与高分辨率原图X尽可能相似的结果。这个过程大致由三部分组成:
1) 块提取及特征表示:从低分辨率图像Y中提取图像块,将每个图像块表示为一个高维向量。所有图像块的高维向量组成为一组特征矩阵(feature maps),feature map的channel数等于向量的维度。可以直接理解为使用多层卷积操作,生成的feature maps。
2) 非线性映射:将高维的向量映射为另一个高维的向量,即将第一个卷积网络输出的高维特征矩阵(feature maps)使用另一组卷积核进行卷积操作,实现特征映射。
3) 重建:将之前计算得到的高维特征融合,生成最终的超分辨率图像。目标是预测的超分辨率sr图像尽可能与高分辨率hr原图相似。
二、网络结构
网络结构如下图所示。整个卷积网络包括三个处理过程,1)对原图进行卷积,生成n1维的feature maps 2)对n1维的feature maps进行卷积生成n2维 3)对n2维feature maps进行卷积生成超分辨率的图像。

图1. 输入低分辨率图像Y,第一个卷积层提取n1维feature map。第二个卷积操作将n1维feature map映射到n2维的feature map。最后的卷积操作将n2维feature map映射为高分辨率维度,channel为3的图像F(Y)。
整个卷积网络结构还很简单,当年提出这个算法的时候还没有出现非常多很深的网络,虽然只有三个卷积操作,已经取得了很大的突破。作者对卷积网络合理性的分析是将其类比为一种稀疏编码算法。
三、训练
训练的目标是学出超分辨率映射函数F,其中涉及参数为P = {W_1, W_2, W_3, B_1, B_2, B_3},分别对应着三次卷积操作的卷积核和bias。训练过程中,最小化生成的超分辨率图像F(Y; P)与目标的高分辨率原图像X的损失值。其中使用的损失函数是均方误差MSE,定义如下:
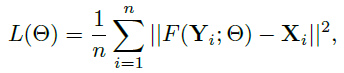
其中n是训练样本数量,即图像数量。选用MSE作为损失函数是因为它和图像质量的一个评估标准PSNR的数学定义相关,PSNR的数学定义如下:
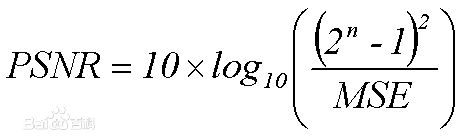
如以上定义所示,PSNR与MSE成反比,则预测结果越好,MSE应越小,PSNR值应越大。
四、实验结果
网络在ImageNet数据集上训练过程的PSNR曲线如下。训练的图像量越大,PSNR值有增高的趋势。
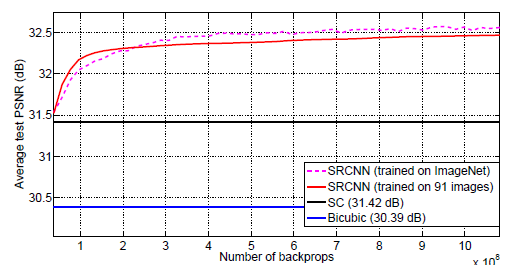
图2. SRCNN根据不同的训练数据集,得到的PSNR值随着数据集增大而增高。
下图为SRCNN与现有算法的PSNR值的对比结果。
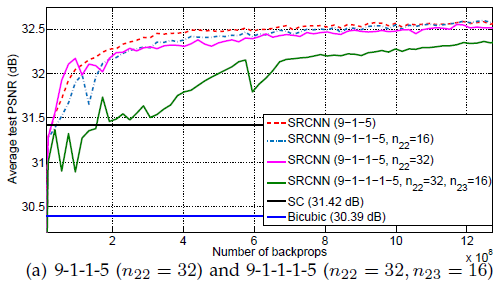
图3. SRCNN与SC、Bicubic现有算法的PSNR值对比
题外话是,PSNR以及SSIM值在过去的图像质量评估中,充当重要的衡量标准。然而,随着这几年算法框架的发展,生成的图像质量单纯依据这几个数学指标不再变得那么权威,肉眼评估与数值指标差别较大,也就是出现了数值评估低,但肉眼看着效果更好的现象。所以在性能评估中肉眼的衡量也同样重要。

图4. 实验结果