本文标题大纲:
前言
在前一篇文章Java 多线程(4)—线程的同步(中) 我们看了一下如何使用 ReentrantLock 类和 synchronized 关键字来控制在多个线程并发执行的同步,并通过他们解决了我们之前留下的关于线程通过带来的一些问题。这篇是线程同步文章的最后一篇,我们来一下一些新的知识点:
volatile 关键字
首先我们来看一下 Java 中另一个和多线程有关的关键字: volatile,这个关键字是在定义变量的时候作为变量修饰符使用的。这里有一个规律:用 volatile 修饰的变量,在线程中被修改之后会立刻同步到主内存中。用该关键字修饰的变量可以保证在任意时刻,某个线程从主内存中取该变量的值总是最新的。
这个其实就是 volatile 的第一个作用:保证其修饰变量在不同线程之间的可见性。
为什么会有这个规律呢?在这里还得提一下我们在 Java 多线程(3)— 线程的同步(上) 中提到的 Java 规定的用来完成线程工作内存和主内存数据交互的 8 种原子性的操作。其中就包括了这几个:read 、load 、store 和 write,我们来看一下它们的作用:
read 操作:作用于主内存中的变量,其把主内存的一个变量的值传输到线程的工作内存中,供接下来的 load 操作使用
load 操作:其把 read 操作从主内存中得到的变量值复制到当前线程工作内存的变量副本中
store 操作:作用于线程工作内存的变量,其把工作内存中的变量的值传输到主内存中,供接下来的 write 操作使用。
write 操作:作用于主内存的变量,其把 store 操作从线程工作内存得到的变量值写入主内存的变量中这两个过程用这张图来说明是在合适不过了:
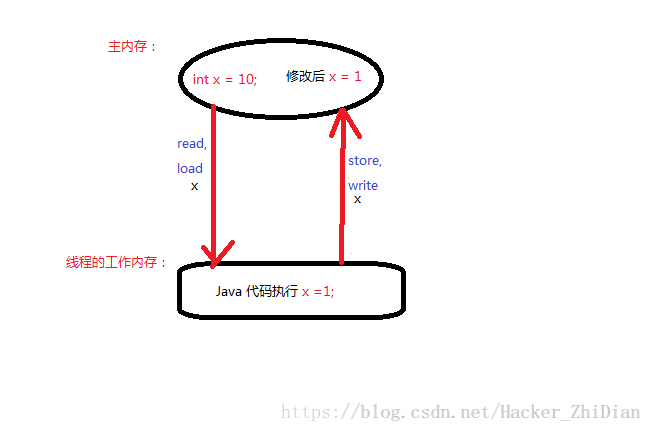
用 volatile 关键字修饰的变量,在线程的工作内存中使用之前一定会通过 load 操作来将变量的值从主内存读取到线程的工作内存中,而在修改完成之后一定会通过 store 操作来将修改后变量的值刷新到主内存中。那么之后其他线程要从主内存中取这个变量的值肯定是修改之后的值,即为最新值。这样的话就保证了用 volatile 关键字修饰的变量在每一次线程从主内存中读取的总是最新值。
volatile 关键字能保证原子性吗?
那么讲到这里可能有小伙伴会问了,既然用 volatile 关键字修饰的变量可以保证 Java 线程每次从主内存读取的值都是最新值,那么可不可以用 volatile 关键字来代替 synchronized 关键字和一些其他的锁来实现线程之间的同步呢?
答案是不可以,如果能代替的话 Java 干嘛还要提供那么多实现线程之间同步的手段。当然这个回答不具有说服力,我们还是来实践一下:我们继续上篇文章中的问题,用多个线程来实现某个变量的累加,不过现在我们把这个变量用 volatile 关键字修饰,来看看会发生什么:
/**
* volatile 关键字的测试
*/
public static class VolatileTest {
private volatile static int sum = 0;
// 对 sum 变量进行 10000 次 +1 操作
public static void increase() {
for (int i = 0; i < 10000; i++) {
sum++;
}
}
public static int getSum() {
return sum;
}
public static void startTest() {
// 开启 10 个子线程进行 sum 变量的累加操作
for (int i = 0; i < 10; i++) {
new Thread(new Runnable() {
@Override
public void run() {
increase();
}
}).start();
}
// 当前活跃的线程数大于 1 的时候,证明子线程累加未完全完成,此时主线程应该让出 CPU
while (Thread.activeCount() > 1) {
Thread.yield();
}
System.out.println(getSum());
}
}
public static void main(String[] args) {
VolatileTest.startTest();
}很简单的一个程序,如果一切顺利的话,运行结果应该是100000(即为 10*10000)。我们来看一下结果:

可是一切并不是那么顺利,结果远小于 100000,我们来分析一下原因:我们在 Java 多线程(3)— 线程的同步(上) 这篇文章中已经分析过了 a--; 操作的字节码,同样的道理,我们也可以得出在这段代码中 sum++; 操作的字节码:
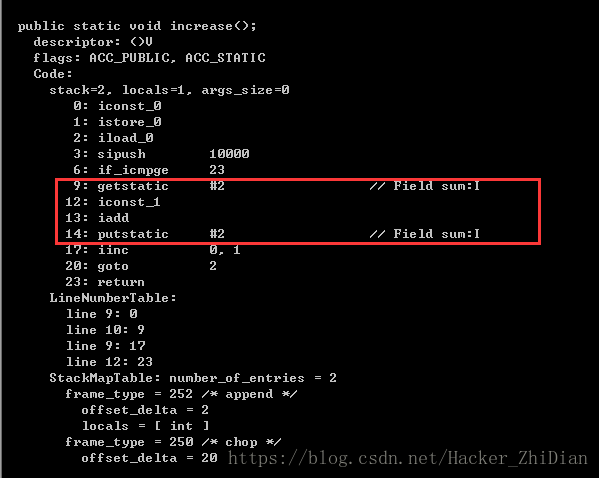
我们可以看到,increase 方法中对 sum 自增一的操作也是分为了多步:
getstatic // 从静态储存区取出变量的值并且压入操作栈顶
iconst_1 // 将整形常量 1 压入操作栈顶
iadd // 从栈中取出两个整形变量将相减的结果压入操作栈顶
putstatic // 从操作栈顶中取出变量的值并将变量值写入静态储存区这里面提到的栈存在于 Java 线程的私有工作内存中。我们可以看到。完成 sum++; 这一步需要 4 个步骤,即使我们对 sum 变量采用了 volatile 关键字修饰,也只能保证每次 sum 变量修改之后能更新到主内存,但是如果一个线程(这里命名为线程 A)在进行 increase 方法累加的时候执行了 iconst_1 指令了之后让出了 CPU 资源,然后另一个线程(这里命名为线程 B)得到了 CPU 资源并且从主内存中读取 sum 的值(此前线程 A 并没有使 sum 自增),然后进行 sum 的累加。线程 B 执行完成后让出 CPU 资源,之后线程 A 得到了 CPU 资源,继续执行未执行完的指令:iadd 和 putstatic ,但是因为此时线程工作栈内存中储存的 sum 的值仍然是在线程 B 进行累加之前从主内存取得的值,即此时的数据变成了过期的数据,所以线程 A 执行的 putstatic 就可能把较小的 sum 值刷新到主内存中。
这也就是为什么在 10 个线程对 sum 进行并发累加时会出现结果小于预期结果的情况,这也说明了单单依靠 volatile 关键字是无法实现同步的。
volatile 禁止指令重排序
我们再来看一下 volatile 关键字的另一个作用:禁止指令重排序。
首先了解一下什么是指令重排序:在 Java 编译期间,编译器可能会基于优化程序性能的目的对代码中翻译成的机器指令进行重排序,举个例子:
int a = 0;
int b = 0;
a = 10;
int res = a + b;编译器优化之后其的执行顺序可能变成了:
int a = 10;
int b = 0;
int res = a + b;也就是把 a = 10; 这条代码放到 int b = 0; 这条语句之前执行了。这其实就是 Java 内存模型中描述的 线程内表现为串行的语义(WithinThread As-If-Serial Semantics)。普通的变量仅仅会保证在该方法执行的过程中所有依赖赋值的结果的地方都会得到正确的结果。但是在单线程中我们无法直接感知到这一点。
但是编译器优化归优化,其在数据上执行的结果是不会变的,即上述代码中,不管编译器怎么优化,在单线程的情况下执行上述代码,res 的值一定会是 10 ,否则这门编程语言就有问题了。
然而在多线程执行的情况下,指令重排可能会导致一些预期之外的情况。假设有以下场景:
// 此处变量要用 volatile 关键字修饰,避免因指令重排序导致错误
volatile boolean isInitialized = false;
// 以下方法在线程 A 中执行,在里面进行程序初始化的操作
public void initialize() {
// 进行初始化操作 ......、
isInitialized = true; // 初始化完成之后设置初始化完成标志为 true,即表示程序初始化完成
}
// 以下方法在线程 B 执行
public void startTask() {
while (!isInitialized) {
sleep(); // 继续等待初始化完成
}
// 初始化完成之后开始执行任务
executeTask();
}在上面用伪代码描述了一个应用场景,假设如果 isInitialized 变量我们不用 volatile 关键字修饰的话,有可能经过编译器的优化之后对指令进行重排序,使得 isInitialized = true; 这条代码放在初始化操作之前调用了,也就是说程序明明还没有初始化完成而 isInitialized 变量的值却变成了 true,那么如果此时线程 B 得到了 CPU 资源就会执行 executeTask() 方法中的代码了,这显然不是我们想看到的。
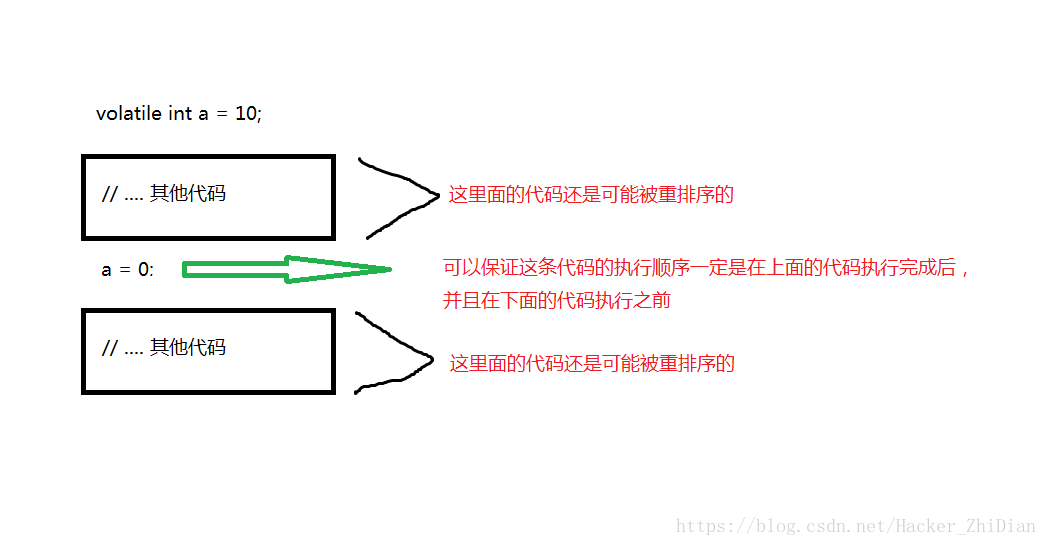
关于 volatile 关键字想补充一点的是,volatile 只保证被其修饰的变量不会被编译器重排序,但是其他代码还是可能会被重排序的,什么意思呢,看一张图:
synchronized 和 volatile 关键字
关于这两个关键字,可以说 synchronized 关键字可以完成由 volatile 关键字提供的可见性的功能,即可以用synchronized 关键字通过控制线程同步来实现可见性。对于这个方面指的是同步块的可见性:Java 内存模型规定:在一个同步块中对一个变量执行 unlock 操作之前,必须先把此变量从线程的工作内存刷新到主内存中。 以此保证每次线程从主内存中获取变量的值得时候,该变量的值一定是最新值。但是用synchronized 实现可见性的缺点也是很明显:效率比 volatile 关键字低,因为 synchronized 关键字有可能会阻塞线程。
但是相对于 synchronized 关键字来说,volatile 不能实现代码块的原子性,所以在实现原子性的时候不能采用 volatile ,关于这点上文已经分析的很清楚了。
然而如果需要禁止指令重排序,则只能通过 volatile 关键字实现。
synchronized 易错点
我们最后来看一个关于线程同步的错误例子,假设有以下程序:
/**
* synchronized 关键字的错误用法
*/
public static class SynchronizedErrorTest {
private static int value = 0;
public static int getValue() {
return value;
}
// 同步方法,每次都把 value 递增 2
public static synchronized void evevIncreament() {
value ++;
value ++;
}
public static void startTest() {
// 新建 10 个子线程用于进行累加操作
for (int i = 0; i < 10; i++) {
new Thread(new Runnable() {
@Override
public void run() {
while (true) {
evevIncreament();
}
}
}).start();
}
// 主线程不断取 value 的值,如果是奇数,那么打印并退出程序
int value = 0;
while (true) {
value = getValue();
if (value % 2 != 0) {
System.out.println(value);
System.exit(0);
}
}
}
}
public static void main(String[] args) {
SynchronizedErrorTest.startTest();
}上述代码中我们已经把 evevIncreament 方法声明成了同步方法,如果不仔细思考的话,可能会认为这个程序会一直执行下去,不会退出,但是事实真的如此吗,我们看看结果:
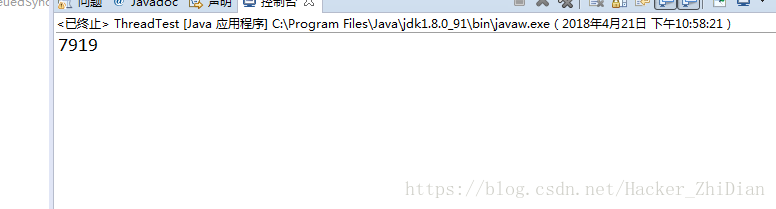
很遗憾,在 value 值为 7919 的时候程序退出了,为什么会出现这种情况?我们已经把 evevIncreament 方法声明为同步方法了,而且 getValue 方法也只有一句 return value; 代码,这句也代码确实是原子性操作。那么上面的运行结果从何而来?
其实问题在于我们被 getValue 方法的原子性误导了,getValue 方法确实具有原子性不假,但是其并没有被 synchronized 关键字修饰,那么可能就会有这种情况:假设现在有一个子线程 A 是专门执行 evevIncreament 方法的,这个方法中有两个 value++; 操作,那么一种情况是子线程 A 刚刚执行完第一个 value++; 操作之后让出了 CPU 资源(此时 value 值为奇数),碰巧这时执行 getValue 方法的线程(这里即为主线程)得到了 CPU 资源,那么它执行了 getValue 方法,其得到的 value 值就是奇数了,对于这种情况程序就结束了。
可能有小伙伴要反驳了,getValue 方法明明是同步方法啊。其实这里和同步方法并没有直接的关系。我们只将 evevIncreament 方法用 synchronized 关键字修饰了,所以同一时刻只能有一个线程进入 evenIncreament 方法中执行代码。但是 getValue 方法并没有用 synchronized 关键字修饰,所以当某个累加线程进入 evenIncreament 方法执行代码的时候,主线程完全可以进入 getValue 方法中执行代码而不被阻塞。这样就有可能导致上面的情况发生。
那么我们如何改进呢?其实我们只需要将 getValue 方法也用 synchronized 关键字修饰就可以了。这样做之后,同一时刻就只有一个线程能够获取 SynchronizedErrorTest.class 对象的锁(对于静态方法 synchronized 关键字锁住的是类的 class 对象),也就是同一时刻只有一个线程能够进入 evenIncreament 方法或者 getValue 方法执行代码。这样的话就可以保证程序的正确性。这里就不给出代码了,理解原理后相信你已经可以独自做出来了。
原子类
其实,为了方便我们编写多线程程序,在 Java SE5 中已经引入了 AtomicInteger 、AtomicLong、AtomicReference 等特殊的原子类来保证我们在使用这些类时可以不主动加入额外的同步手段来保证程序的正确性,从某些方面来说减轻了开发者编写多线程程序的负担。下面我们用 AtomicInteger 类来改进上面的程序,使其达到我们想要的结果:
/**
* AtomicInteger 类的使用,AtomicInteger 类本身对其中的一些操作提供了多线程程序的同步控制
*/
public static class AtomicIntegerTest {
private static AtomicInteger value = new AtomicInteger(0);
public static int getValue() {
return value.get();
}
// 数字递增方法,每次把 value 的值递增 2
public static void evevIncreament() {
value.addAndGet(2);
}
public static void startTest() {
// 新建 10 个子线程用于进行累加操作
for (int i = 0; i < 10; i++) {
new Thread(new Runnable() {
@Override
public void run() {
while (true) {
evevIncreament();
}
}
}).start();
}
// 主线程不断取 value 的值,如果是奇数,那么打印并退出程序
int value = 0;
while (true) {
value = getValue();
if (value % 2 != 0) {
System.out.println(value);
System.exit(0);
}
}
}
}
public static void main(String[] args) {
AtomicIntegerTest.startTest();
}可以看到,我们并没有在程序中添加任何的锁和 synchronized 关键字来手动实现同步,但是这个程序如果不手动结束的话就会一直运行下去。正是因为 AtomicInteger 类本身就对其中提供的一些方法实现了同步。当然,还有其他的一些原子类也是类似的,有兴趣的小伙伴可以自行看一下相关的文档。
好了,对于 Java 中的线程同步我们就讲到这里了,用了 3 篇文章的篇幅,终于能把线程之间的同步讲得比较清晰了。
如果你仔细思考了这 3 篇文章,我相信你对线程同步至少有了一个基本的理解。
事实上,如果要在保证程序准确性的前提下写出一个高效率的并发程序并不容易,因为对于不同的问题,我们需要考虑很多的实现细节。这些都是需要丰富的实践经验和扎实的理论作为基础。
好了, 这篇文章到就这里了,下一篇文章我们将会一起讨论关于 Java 中线程池的相关问题。那里会有一些新的有意思的知识点。如果博客中有什么不正确的地方,还请多多指点。如果这篇文章对您有帮助,请不要吝啬您的赞,欢迎继续关注本专栏。
谢谢观看。。。