数据科学中,在对数据分析前,必须要多数据进行处理。将非正常的、错误的数据输入到算法中会导致不好的结果。所以异常的检测及处理为非常重要的一环。
1.1 单变量异常检测
在处理单变量异常时,有一条准则:极端值可以当做异常值
1. IQR(四分位距,75分位与25分位的差)。第一种是比25分位值减去IQR*1.5小的值;第二种是比75分为大IQR*1.5的值
2. Z-scores 得分绝对值大于3的观测值可认为是异常值
先用箱图来直观观察一下每个特征的分布情况
from sklearn.datasets import load_boston
import numpy as np
import pandas as pd
from sklearn import preprocessing
data=load_boston()
boston=pd.DataFrame( data.data)
boston.columns=data['feature_names']
boston.pop('CHAS')#remove column
normolized_data=preprocessing.StandardScaler().fit_transform(boston)
boston.boxplot(sym='r',vert=False,patch_artist=True,meanline=False,showmeans=True)

箱图能非常直观的观察数据间离散程度、异常值(红色)、分布差异等。在这里,
vert=False表示横向、竖向,
patch_artist=True表示上下四分位框内是否填充,True为填充
传送门:箱图https://www.jianshu.com/p/b2f70f867a4a
以下为用Z-scores寻找异常值。
之所以以3作为界限,原因是一个正态分布的数据95%的面积分布在平均数左右两个标准差范围内;99.9%的面积分布在平均数左右3个标准差范围内。
outliers_rows,outliers_columns=np.where(np.abs(normolized_data)>3)
print(len(outliers_columns))
结果为65。
这种方法虽然可以发现很多异常值,但是很多不是极端值的异常值仍会被漏掉。为了发现这些异常,利用PCA降维之后再找绝对标准差大于3的值。
传送门:PCA降维简介https://blog.csdn.net/qq_36056559/article/details/80738779
OneClassSVM
OneClassSVM是一种无监督的算法,它可以用来检查新的样本是否符合以前的数据分布。它有三个主要参数:
1. Kernel (核函数)和Degree
此两变量相关,根据经验值kernel应为rbf,degree应为3.
2. Gamma
它是与rbf核相关的参数。建议这个参数设置的越低越好,通常为实例数倒数和变量数倒数之间的最小值。
3. Nu
它决定模型是否必须符合一个精确的分布,还是应该尽量保持某种标准分布而不太注重适应现有数据
区间为(0,1],默认值为0.5.但在这里0.5的结果并不好,所以
可以由一下公式确定: nu_estimate=0.95*outliers_fraction+0.05
通常outliers_fraction的范围为0.02-0.1
一下代码用聚类生成器产生一个聚类并用OneSVM进行异常检测:
from sklearn.datasets import make_blobs
blobs=make_blobs(n_samples=1000,n_features=2,centers=1,cluster_std=1.5,shuffle=True,random_state=5)
normolized_data=preprocessing.StandardScaler().fit_transform(blobs[0])
out_fraction=0.02
nu_estimate=0.95*out_fraction+0.05
mechine_learning=svm.OneClassSVM(kernel="rbf",degree=3,gamma=1.0/len(normolized_data),nu=nu_estimate)
mechine_learning.fit(normolized_data)
detection=mechine_learning.predict(normolized_data)
outliers=np.where(detection==-1)
regular=np.where(detection==1)
from matplotlib import pyplot as plt
a=plt.plot(normolized_data[regular,0],normolized_data[regular,1],'x',markersize=2,color="green",alpha=0.6)
b=plt.plot(normolized_data[outliers,0],normolized_data[outliers,1],'o',color='red',markersize=6)
结果还是比较理想的
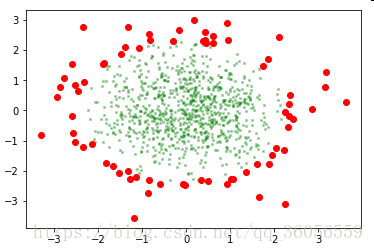
接下来回到波士顿的数据,先对数据进行标准化后再进行降维操作
normolized_data=preprocessing.StandardScaler().fit_transform(boston)#标准化
pca=PCA(n_components=5)
Zscore_components=pca.fit_transform(normolized_data)#PCA降维
out_fraction=0.02
nu_estimate=0.95*out_fraction+0.05
mechine_learning=svm.OneClassSVM(kernel="rbf",degree=3,gamma=1.0/len(Zscore_components),nu=nu_estimate)
mechine_learning.fit(Zscore_components)
detection=mechine_learning.predict(Zscore_components)
outliers=np.where(detection==-1)
regular=np.where(detection==1)
from matplotlib import pyplot as plt
a=plt.plot(Zscore_components[regular,0],Zscore_components[regular,1],'x',markersize=2,color="green",alpha=0.6)
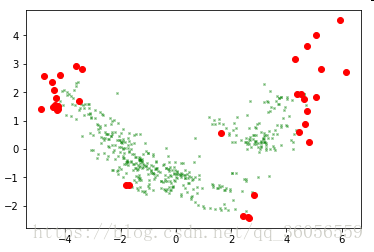
b=plt.plot(Zscore_components[outliers,0],Zscore_components[outliers,1],'o',color='red',markersize=6)outliers 和 regular结果:

35个点被认为是异常点,471个点是正常点。
因为在PCA降维中,分量1和2占据了原数据大部分的信息量。为了观察更加直观的结果,用pyplot来看看分量1和2的分布情况:
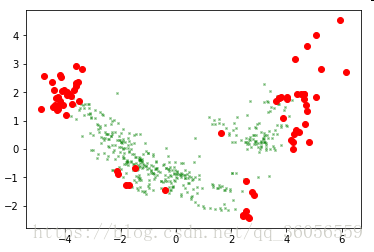
当outliers_fraction值为0.1时:
参考文献:
1. 《数据科学导论》
2. http://scikit-learn.org/stable/modules/generated/sklearn.svm.OneClassSVM.html
3. https://www.jianshu.com/p/b2f70f867a4a