1.命名服务
2.订阅发布
3.分布式锁
4.master选举
5.分布式队列
6.负载均衡
1.命名服务
问题:由于数据库id自增在分库分表的情况中是不能使用的,而使用uuid又难于理解
解决:利用zookeeper创建有序节点自增的特性来生成有序id
2)利用zookeeper的树形分层结构,可以把系统中各种服务的名称,地址以及目录信息,存放在zookeeper中
实现配置中心有两种模式:push (服务端推送)、pull(客户端轮询拉取)
zookeeper采用的是推拉相结合的方式。 客户端向服务器端注册自己需要关注的节点。一旦节点数据发生变化,那么服务器端就会向客户端发送watcher事件通知。客户端收到通知后,主动到服务器端获取更新后的数据
开源项目disconf:http://disconf.readthedocs.io/zh_CN/latest/
服务器上线之后通过定时器定时往zookeeper节点写入自己服务器数据,然后监控服务器监控它,如果监控到服务器很久没更新代表这台服务器挂掉了
通过往zookeeper节点发送命令,监控服务器读取到数据执行相应命令
参考:https://www.cnblogs.com/sky-sql/p/6685531.html
create table (id , methodname …) methodname增加唯一索引
insert 一条数据XXX delete 语句删除这条记录

locker是zookeeper中的一个数据节点,node_1,node_2,node_3,代表locker下的一些列顺序节点,client_1,client_2,client_3代表客户端,Server代表需要互斥访问的服务。
2.getChildren获取所有子节点,然后通过排序获得最小节点,如果是第一个节点则返回获得锁
3.如果当前节点不是第一个则监听比自己小的上一个节点,并等待(上一个节点删除了,那么释放等待,获得锁)
假设我们有一个系统A,向外提供服务,并且这个服务必须24小时不间断提供(7*24小时可用, 99.999%可用),于是我们选择采用集群,master slave的架构方式,集群中有主机,有备机,由主机向外提供服务,备机负责监听主机的状态,一旦主机宕机,备机必须立刻接管主机继续向外提供服务,这种从备机中选出主机的过程就是master选举。
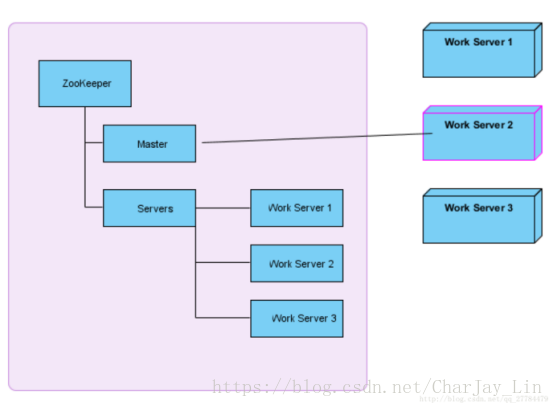
2)左边紫色代表zookeeper集群,右边代表三台工作服务器。
1.它们启动时会首先去Servers节点下创建一个临时节点,并把自己的基本信息写入节点,这个过程叫服务注册;
2.系统中的其他服务可以获取Servers节点下的字节点列表,来了解当前系统哪些服务器可用,这个过程叫服务发现;
3.然后这些服务器会尝试去创建Master节点,谁能创建成功,谁就是Master。
4.所有的备用服务器(slave)必须关注Master节点的删除事件。
master选举改成多线程(多进程)模型(master-slave) 创建三个工程,while去抢
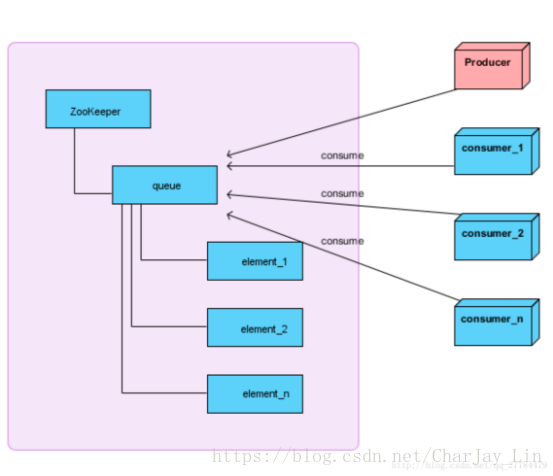
左侧为zookeeper集群,右侧为消费者和生产者,生产者在queue节点下创建顺序节点,来存放数据,消费者通过读取这些节点来消费数据。
2.确定自己节点在子节点中的顺序(看是不是最小节点,可通过SortSet或者排序算法)如果是第一个节点则返回并删除自己
3.如果自己不是最小的子节点,那么监控比自己小的上一个子节点的删除事件,否则处于等待(等待完毕返回数据,删除自己)

参考:https://www.cnblogs.com/qingfei1994/p/7670326.html
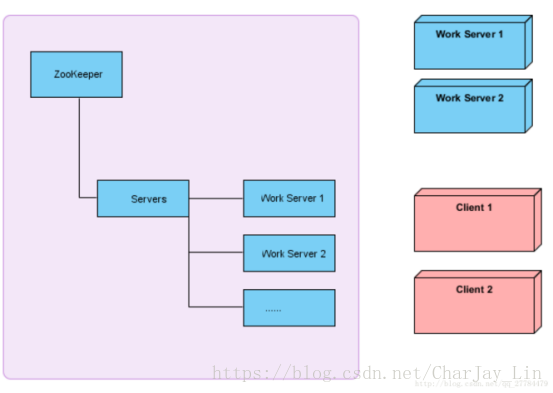
浅紫色代表zookeeper集群,右侧上方两个工作服务器,下面两个代表客户端,每台工作服务器启动都会去zookeeper Servers节点下注册一个临时节点,每台客户端启动都会去Servers节点获取可用工作服务器的列表,并通过负载均衡算法,得出一台工作服务器,并与之建立网络连接,客户端与服务端的网络连接采用netty。
curator-reciples :Apache curator-recipes组件提供了大量已经"生产化"(produced)的特性,极大的简化了使用zk的复杂度.
1)master/leader选举 :LeaderLatch、LeaderSelector
2)分布式锁(读锁、写锁):InterProcessMutex
https://blog.csdn.net/qq_27784479/article/details/78449922
https://blog.csdn.net/duke370503/article/details/52623192
https://blog.csdn.net/zuoanyinxiang/article/details/50946646