Python部分
1 Python的函数参数传递
下面验证Python函数参数传递的方式:
def changelist(lst): #修改列表
lst[0] = '1'
lst = [111, 2, 3, 4]
changelist(lst)
print lst
def changedict(dic): #修改字典
dic["lustar"] ="yes"
dict1 = {"lustar": "no"}
changedict(dict1)
print dict1
输出结果为:
['1', 2, 3, 4]
{'lustar': 'yes'}
可见,对于列表和字典,参数传递的方式是引用传递。
def changestring(string1): #修改字符串
string1 += "None"
str1 = "I am a good boy!"
changestring(str1)
print str1
def changevar(a): #修改变量
a += 111
b = 1
changevar(b)
print b
输出结果为:
I am a good boy! 1
可见,对于字符串以及一般的变量,结果类似于值传递,并不会影响到原结果。那么,如果想改变字符串的值呢?返回新的字符串即可:
def changestring(string1):
string1 += "None"
return string1 #修改后的参数作为返回值
str1 = "I am a good boy!"
print id(str1)
str1 = changestring(str1)
print str1
print id(str1)
输出结果为:
31869336 I am a good boy!None 31867712
可见,这时的字符串已经不是在原来的基础上修改了,实际上是返回了一个新字符串。
结论:
对于可以修改的对象,如列表和字典,函数的参数传递方式是引用传递。
对于不能修改的对象,包括字符串、一般变量和元组(元组本来就不能修改),参数传递的方式是值传递。如果确实需要修改该对象的值,可以利用函数的返回值进行修改。
静态方法是指类中无需实例参与即可调用的方法(不需要self参数),在调用过程中,无需将类实例化,直接在类之后使用.号运算符调用方法。
通常情况下,静态方法使用@staticmethod装饰器来声明。
示例代码:
class ClassA(object):
@staticmethod
def func_a():
print('Hello Python')
if __name__ == '__main__':
ClassA.func_a()
# 也可以使用实例调用,但是不会将实例作为参数传入静态方法
ca = ClassA()
ca.func_a()
这里需要注意的是,在Python 2 中,如果一个类的方法不需要self参数,必须声明为静态方法,即加上@staticmethod装饰器,从而不带实例调用它。
而在Python 3中,如果一个类的方法不需要self参数,不再需要声明为静态方法,但是这样的话只能通过类去调用这个方法,如果使用实例调用这个方法会引发异常。
class ClassA(object):
def func_a():
print('Hello Python')
if __name__ == '__main__':
ClassA.func_a()
# 以下使用实例调用会引发异常
ca = ClassA()
ca.func_a()
异常信息:
func_a() takes 0 positional arguments but 1 was given
因为func_a没有声明为静态方法,类实例在调用func_a时,会隐式地将self参数传入func_a,而func_a本身不接受任何参数,从而引发异常。
类方法在Python中使用比较少,类方法传入的第一个参数为cls,是类本身。并且,类方法可以通过类直接调用,或通过实例直接调用。但无论哪种调用方式,最左侧传入的参数一定是类本身。
通常情况下,类方法使用@classmethod装饰器来声明
class ClassA(object):
@classmethod
def func_a(cls):
print(type(cls), cls)
if __name__ == '__main__':
ClassA.func_a()
ca = ClassA()
ca.func_a()
从运行结果可以看出,无论是类调用还是实例调用,类方法都能正常工作。且通过打印cls,可以看出cls传入的都是类实例本身。
<class 'type'> <class '__main__.ClassA'> <class 'type'> <class '__main__.ClassA'>
这里需要注意,如果存在类的继承,那类方法获取的类是类树上最底层的类。
class BaseA(object):
@classmethod
def func_a(cls):
print(type(cls), cls)
class BaseB(object):
pass
class ClassA(BaseA, BaseB):
pass
if __name__ == '__main__':
ClassA.func_a()
ca = ClassA()
ca.func_a()
代码中ClassA继承自BaseA、BaseB,在调用类方法时,虽然类方法是从BaseA继承而来,但是传入func_a的cls函数实际上是ClassA,也就是最底层(最具体)的类。
运行结果:
<class 'type'> <class '__main__.ClassA'> <class 'type'> <class '__main__.ClassA'>
所以,在某些时候,需要明确调用类属性时,不要使用类方法传入的cls参数,因为它传入的是类树中最底层的类,不一定符合设计初衷。
可以直接通过类名访问类属性。
class BaseA(object):
@classmethod
def func_a(cls):
# 直接使用类名,而不使用cls
print(BaseA)
print(type(cls), cls)
class BaseB(object):
pass
class ClassA(BaseA, BaseB):
pass
if __name__ == '__main__':
ClassA.func_a()
实例方法,除静态方法与类方法外,类的其他方法都属于实例方法。
实例方法需要将类实例化后调用,如果使用类直接调用实例方法,需要显式地将实例作为参数传入。
最左侧传入的参数self,是实例本身。
class ClassA(object):
def func_a(self):
print('Hello Python')
if __name__ == '__main__':
# 使用实例调用实例方法
ca = ClassA()
ca.func_a()
# 如果使用类直接调用实例方法,需要显式地将实例作为参数传入
ClassA.func_a(ca)
3 类变量和实例变量
实例变量是对于每个实例都独有的数据,而类变量是该类所有实例共享的属性和方法。
其实我更愿意用类属性和实例属性来称呼它们,但是变量这个词已经成为程序语言的习惯称谓。
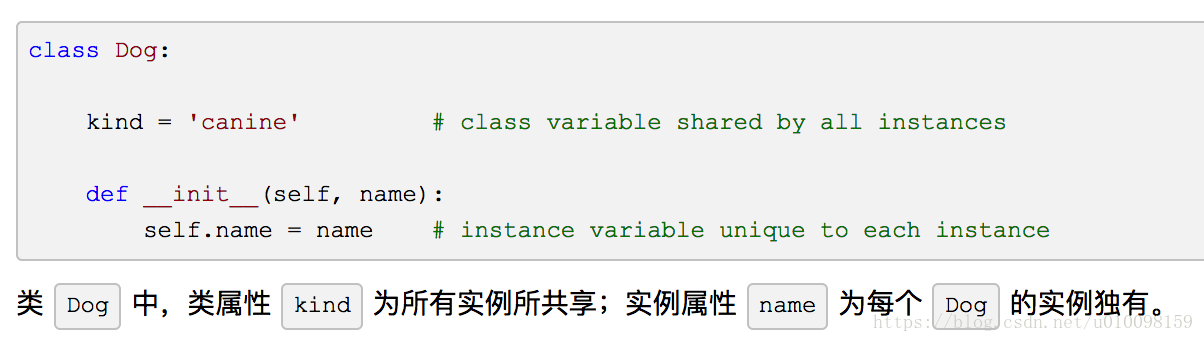
参考博客:https://www.cnblogs.com/crazyrunning/p/6945183.html
4 Python中单下划线和双下划线
_xxx :保护变量,意思是只有类对象和子类对象能够访问到这些变量(尽量避免在类外部直接修改)
__xxx__ :系统定义名字
__xxx :类中的私有变量名
以单下划线开头(_foo)的代表不能直接访问的类属性,需通过类提供的接口进行访问,不能用“from xxx import *”而导入;
以双下划线开头的(__foo)代表类的私有成员;
以双下划线开头和结尾的(__foo__)代表python里特殊方法专用的标识,如__init__()代表类的构造函数。
5 迭代器和生成器
迭代器:Python中一个实现了_iter_方法和_next_方法的类对象,就是迭代器;
生成器:生成器是一种特殊的迭代器,带有yield的迭代器。
参考:https://blog.csdn.net/u014745194/article/details/70176117
https://blog.csdn.net/qq_34857250/article/details/78882422
6 *args and **kwargs
*args 表示任何多个无名参数,它是一个tuple;**kwargs 表示关键字参数,它是一个dict。并且同时使用*args和**kwargs时,必须*args参数列要在**kwargs前。
实例:
当你不确定你的函数里将要传递多少参数时你可以用*args.例如,它可以传递任意数量的参数;
| 1 2 3 4 5 6 7 8 |
>>> def print_everything(*args): for count, thing in enumerate(args): ... print '{0}. {1}'.format(count, thing) ... >>> print_everything('apple', 'banana', 'cabbage') 0. apple 1. banana 2. cabbage |
相似的,**kwargs允许你使用没有事先定义的参数名。
| 1 2 3 4 5 6 7 |
>>> def table_things(**kwargs): ... for name, value in kwargs.items(): ... print '{0} = {1}'.format(name, value) ... >>> table_things(apple = 'fruit', cabbage = 'vegetable') cabbage = vegetable apple = fruit |
7 装饰器与原理
参考博客:https://blog.csdn.net/u010358168/article/details/77773199
8 Python中重载
::python 自然就不需要函数重载
函数重载主要是为了解决两个问题。
- 可变参数类型。
- 可变参数个数。
另外,一个基本的设计原则是,仅仅当两个函数除了参数类型和参数个数不同以外,其功能是完全相同的,此时才使用函数重载,如果两个函数的功能其实不同,那么不应当使用重载,而应当使用一个名字不同的函数。
问题 1 ,函数功能相同,但是参数类型不同,python 如何处理?答案是根本不需要处理,因为 python 可以接受任何类型的参数,如果函数的功能相同,那么不同的参数类型在 python 中很可能是相同的代码,没有必要做成两个不同函数。
问题2 ,函数功能相同,但参数个数不同,python 如何处理?大家知道,答案就是缺省参数。对那些缺少的参数设定为缺省参数即可解决问题。因为你假设函数功能相同,那么那些缺少的参数终归是需要用的。
所以,Python不需要函数重载
9 __new__和__init__的区别
__new__是一个静态方法,而__init__是一个实例方法.__new__方法会返回一个创建的实例,而__init__什么都不返回.- 只有在
__new__返回一个cls的实例时后面的__init__才能被调用. - 当创建一个新实例时调用
__new__,初始化一个实例时用__init__.
10 Python 写单例模式
手写的话可以参考java版本的。
11 协程
参考博客:http://python.jobbole.com/86481/
12 Python 2.7.x 和 3.x 版本的重要区别
参考博客:http://python.jobbole.com/80006/
13 闭包
闭包(closure)是函数式编程的重要的语法结构。闭包也是一种组织代码的结构,它同样提高了代码的可重复使用性。
当一个内嵌函数引用其外部作作用域的变量,我们就会得到一个闭包. 总结一下,创建一个闭包必须满足以下几点:
- 必须有一个内嵌函数
- 内嵌函数必须引用外部函数中的变量
- 外部函数的返回值必须是内嵌函数
14 匿名函数Lambda
参考:https://www.zhihu.com/question/20125256
15 Python函数式编程
参考:https://coolshell.cn/articles/10822.html
16 Python里的拷贝
参考:https://blog.csdn.net/u011630575/article/details/78604226
17 Python垃圾回收机制
Python GC主要使用引用计数(reference counting)来跟踪和回收垃圾。在引用计数的基础上,通过“标记-清除”(mark and sweep)解决容器对象可能产生的循环引用问题,通过“分代回收”(generation collection)以空间换时间的方法提高垃圾回收效率。
1)引用计数
PyObject是每个对象必有的内容,其中ob_refcnt就是做为引用计数。当一个对象有新的引用时,它的ob_refcnt就会增加,当引用它的对象被删除,它的ob_refcnt就会减少.引用计数为0时,该对象生命就结束了。
优点:
- 简单
- 实时性
缺点:
- 维护引用计数消耗资源
- 循环引用
2 标记-清除机制
基本思路是先按需分配,等到没有空闲内存的时候从寄存器和程序栈上的引用出发,遍历以对象为节点、以引用为边构成的图,把所有可以访问到的对象打上标记,然后清扫一遍内存空间,把所有没标记的对象释放。
3 分代技术
分代回收的整体思想是:将系统中的所有内存块根据其存活时间划分为不同的集合,每个集合就成为一个“代”,垃圾收集频率随着“代”的存活时间的增大而减小,存活时间通常利用经过几次垃圾回收来度量。
Python默认定义了三代对象集合,索引数越大,对象存活时间越长。
举例:
当某些内存块M经过了3次垃圾收集的清洗之后还存活时,我们就将内存块M划到一个集合A中去,而新分配的内存都划分到集合B中去。当垃圾收集开始工作时,大多数情况都只对集合B进行垃圾回收,而对集合A进行垃圾回收要隔相当长一段时间后才进行,这就使得垃圾收集机制需要处理的内存少了,效率自然就提高了。在这个过程中,集合B中的某些内存块由于存活时间长而会被转移到集合A中,当然,集合A中实际上也存在一些垃圾,这些垃圾的回收会因为这种分代的机制而被延迟。
操作系统部分
1 select,poll和epoll
其实所有的I/O都是轮询的方法,只不过实现的层面不同罢了.
这个问题可能有点深入了,但相信能回答出这个问题是对I/O多路复用有很好的了解了.其中tornado使用的就是epoll的.
基本上select有3个缺点:
- 连接数受限
- 查找配对速度慢
- 数据由内核拷贝到用户态
poll改善了第一个缺点
epoll改了三个缺点.
2 调度算法
- 先来先服务(FCFS, First Come First Serve)
- 短作业优先(SJF, Shortest Job First)
- 最高优先权调度(Priority Scheduling)
- 时间片轮转(RR, Round Robin)
- 多级反馈队列调度(multilevel feedback queue scheduling)
实时调度算法:
- 最早截至时间优先 EDF
- 最低松弛度优先 LLF
3 死锁
原因:
- 竞争资源
- 程序推进顺序不当
必要条件:
- 互斥条件
- 请求和保持条件
- 不剥夺条件
- 环路等待条件
处理死锁基本方法:
- 预防死锁(摒弃除1以外的条件)
- 避免死锁(银行家算法)
- 检测死锁(资源分配图)
- 解除死锁
- 剥夺资源
- 撤销进程
4 程序编译与链接
Bulid过程可以分解为4个步骤:预处理(Prepressing), 编译(Compilation)、汇编(Assembly)、链接(Linking)
整个的面试题参考:http://python.jobbole.com/85231/