1、字符编码和转码
1.1.在python2默认编码是ASCII, python3里默认是unicode
1.2.unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节), so utf-16就是现在最常用的unicode版本, 不过在文件里存的还是utf-8,因为utf8省空间
1.3.在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string


import sys print(sys.getdefaultencoding())#打印编码格式 msg = '我是一个BOY' msg_gb2312 = msg.encode("gb2312") print(msg_gb2312) gb2312_to_unicode = msg_gb2312.decode('gb2312') print(gb2312_to_unicode) gb2312_to_utf8 = msg_gb2312.decode('gb2312').encode('utf-8') print(gb2312_to_utf8)
2、文件操作流程:
- 打开文件,得到文件句柄并赋值给一个变量
- 通过句柄对文件进行操作
- 关闭文件
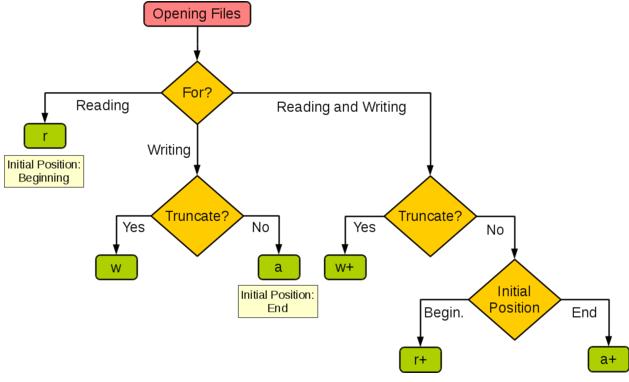
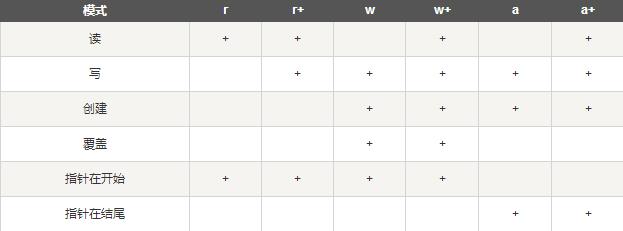
#打开文件 file object = open(file_name [, access_mode][, encoding='utf-8']) #关闭文件 file.close() #为了避免打开文件后忘记关闭,可以通过管理上下文,即: with open('file','access_mode') as f: #读 file.read([size]) #从文件读取指定的字节数,如果未给定或为负则读取所有。 file.readline([size])#读取整行,包括 "\n" 字符。 file.readlines([sizehint])#读取所有行并返回列表,若给定sizeint>0,则是设置一次读多少字节,这是为了减轻读取压力。 #写 file.write(str)#将字符串写入文件,返回的是写入的字符长度。 file.writelines(sequence)#向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。 #设置文件当前位置 file.seek(offset[, whence]) #返回文件当前位置。 file.tell() #截取文件,截取的字节通过size指定,默认为当前文件位置。 file.truncate([size])
3、函数
3.1定义:函数是指将一组语句的集合通过一个名字(函数名)封装起来,要想执行这个函数,只需调用其函数名即可
特性:
-
-
- 减少重复代码
- 使程序变的可扩展
- 使程序变得易维护
-
3.2参数:
普通参数,默认参数,可变参数*args(返回元组 可变位置参数,可变关键字参数),**kwargs(返回字典keyword-only) 参数
调用函数(传参):
位置参数,关键字参数,参数结构(位置参数解构,关键字参数解构) 关键参数必须放在位置参数之后
3.3局部变量和全局变量:
在子程序中定义的变量称为局部变量,在程序的一开始定义的变量称为全局变量。
全局变量作用域是整个程序,局部变量作用域是定义该变量的子程序。
当全局变量与局部变量同名时:在定义局部变量的子程序内,局部变量起作用;在其它地方全局变量起作用。
3.4 返回值
要想获取函数的执行结果,就可以用return语句把结果返回
注意:
-
- 函数在执行过程中只要遇到return语句,就会停止执行并返回结果,so 也可以理解为 return 语句代表着函数的结束
- 如果未在函数中指定return,那这个函数的返回值为None
3.5递归特性:
必须有一个明确的结束条件
每次进入更深一层递归时,问题规模相比上次递归都应有所减少
递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)